单元 4. 设计数据到达监控与事件触发机制¶
模型的训练或模型推理都需要使用到数据,每天会有新的数据产生,且数据产生的时间并不固定。因此需要在数据到达后第一时间触发任务流的运行。
本节描述设计数据到达监控与事件触发的任务流。
数据准备¶
编排任务流前,已通过以下命令在 Hive 中创建了一个 status_tbl 表,用于记录每天数据的更新情况:
create table status_tbl(masterid string, updatetime timestamp, flag int);
status_tbl 表结构及字段说明如下:
字段名称 |
描述 |
|---|---|
masterid |
场站ID |
updatetime |
插入数据的时间 |
flag |
状态,1表示数据已写入,0表示数据已使用 |
设计任务流¶
当源数据更新完成后,可在 status_tbl 表中插入一条记录,表示某个场站的数据更新已完成。任务流监控到状态表中的数据更新后,就会对该场站的数据进行加工处理。处理完成后,将该场站的状态更新为0,表示该场站当天的数据已使用。
状态表的实时监控可通过在任务流前加上 Recursion 算子来实现,具体过程如下:
任务流运行,使用监控状态表的数据。
判断获取的状态是否满足退出条件,如果不满足,则继续轮询,查询该状态表。
当满足退出条件时(可以在 Hive 表中插入一条满足退出条件的记录),表明数据已更新,可以进行后续的处理。
任务流前加上 Recursion 算子后,完成编排的任务流如下图所示:
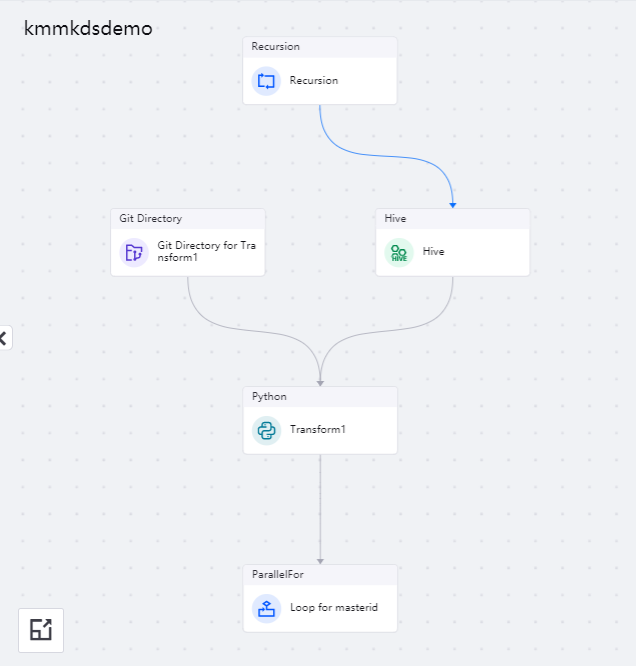
在 Recursion 算子的子画布中,使用以下算子编排任务流:
Hive 算子:从 Hive 中查询状态表数据,并获取 Hive 算子所需的 keytab 和 kerberos 配置文件
Git Directory 算子:从 Git 目录获取
transform3.py文件,用于 Python 算子的输入Python 算子:对输入文件做格式化处理
将算子拖到编辑画布,完成编排后的任务流如下图所示:
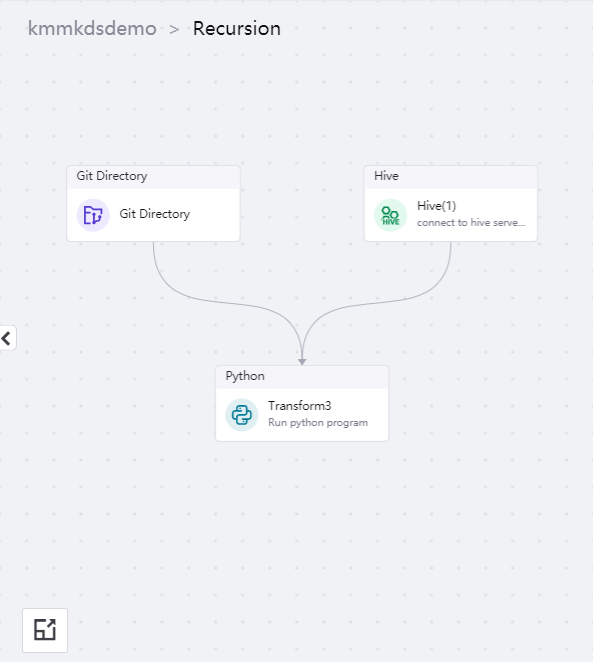
任务流中编排的每个算子的配置说明如下:
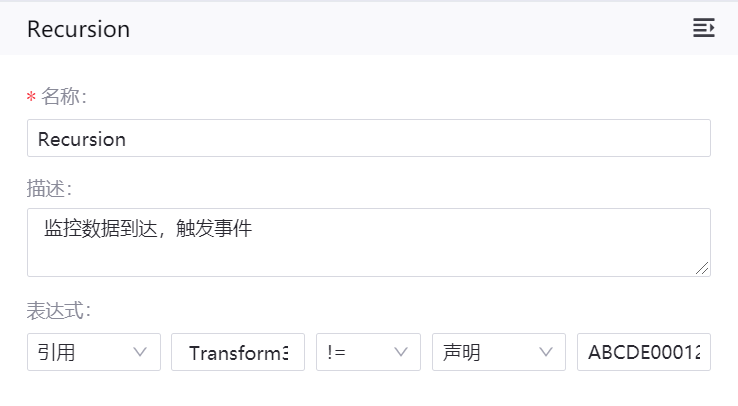
Recursion 算子¶
名称:Recursion
描述:监控数据到达,触发事件
配置参数
Recursion 算子的表达式格式为:
引用 | Transform3.list_output1 | != | 声明 | ABCDE00012020-06-221
算子配置示例如下图所示:
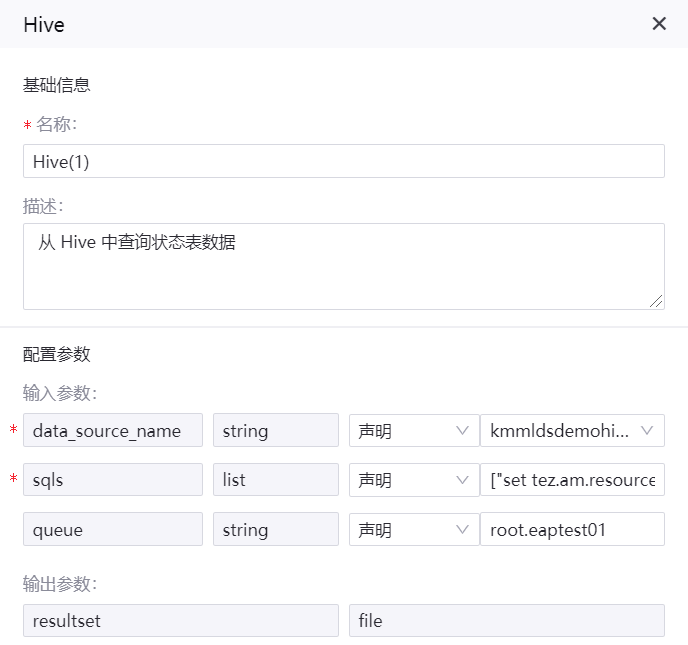
Hive 算子¶
名称:Hive(1)
描述:从 Hive 中查询状态表数据、keytab、和 krb5 配置文件
输入参数
参数名称 |
数据类型 |
操作类型 |
值 |
|---|---|---|---|
data_source_name |
String |
声明 |
注册的 Hive 数据源名称 |
sqls |
List |
声明 |
[“set tez.am.resource.memory.mb=1024”,”select masterid, date(updatetime) as updatetime, flag from status_tbl”] |
queue |
String |
声明 |
root.eaptest01(通过资源管理申请的大数据队列名称) |
输出参数
参数名称 |
值 |
|---|---|
resultset |
file |
算子配置示例如下图所示:
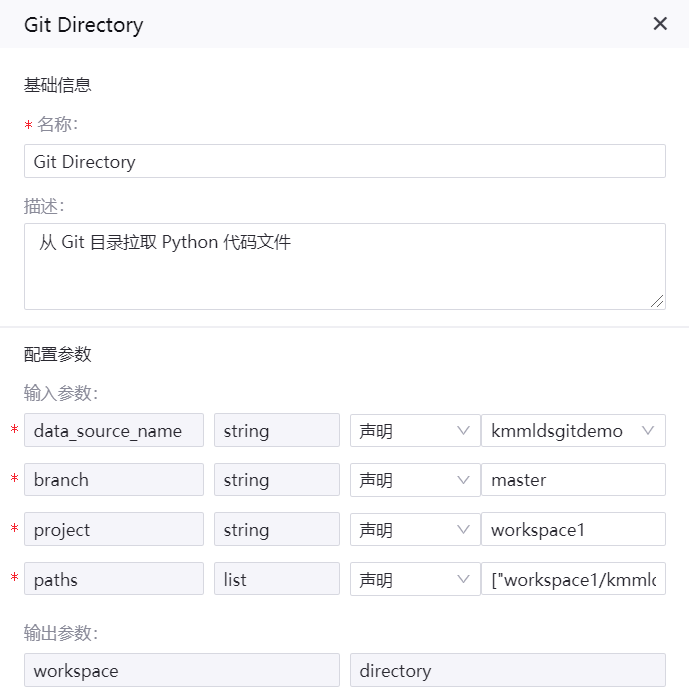
Git Directory 算子¶
名称:Git Directory
描述:从 Git 目录拉取 Python 代码文件
输入参数
参数名称 |
数据类型 |
操作类型 |
值 |
|---|---|---|---|
data_source_name |
String |
声明 |
注册的 Git 数据源名称 |
branch |
String |
声明 |
master |
project |
String |
声明 |
workspace1 |
paths |
List |
声明 |
[“workspace1/kmmlds/transform3.py”] |
输出参数
参数名称 |
值 |
|---|---|
workspace |
directory |
paths |
list |
算子配置示例如下图所示:
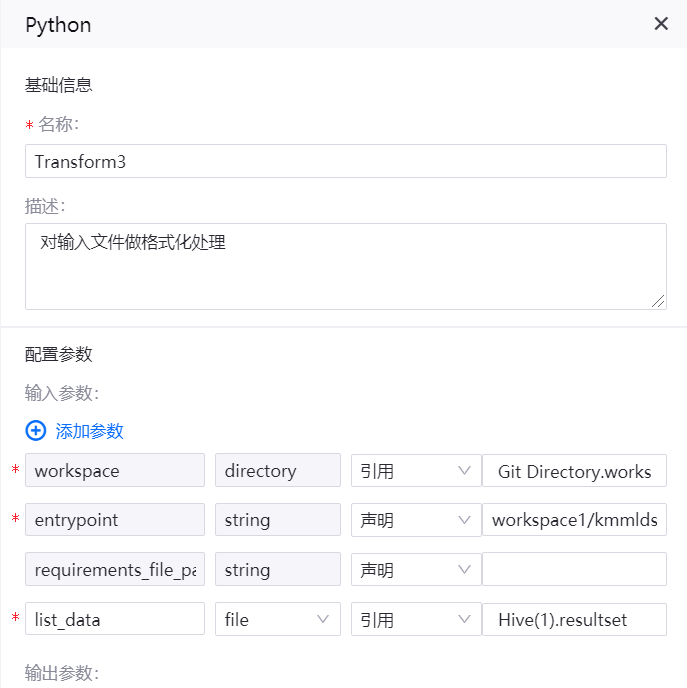
Python 算子¶
名称:Transform3
描述:对输入文件做格式化处理
输入参数
参数名称 |
数据类型 |
操作类型 |
值 |
|---|---|---|---|
workspace |
Directory |
引用 |
Git Directory.workspace |
entrypoint |
String |
声明 |
workspace1/kmmlds/transform3.py |
requirements_file_path |
String |
声明 |
|
list_data |
file |
引用 |
Hive(1).resultset |
输出参数
参数名称 |
值 |
|---|---|
list_output1 |
String |
算子配置示例如下图所示: