单元 4:设计任务流¶
本教程中,你可以根据以下逻辑预测风机绕组的温升。
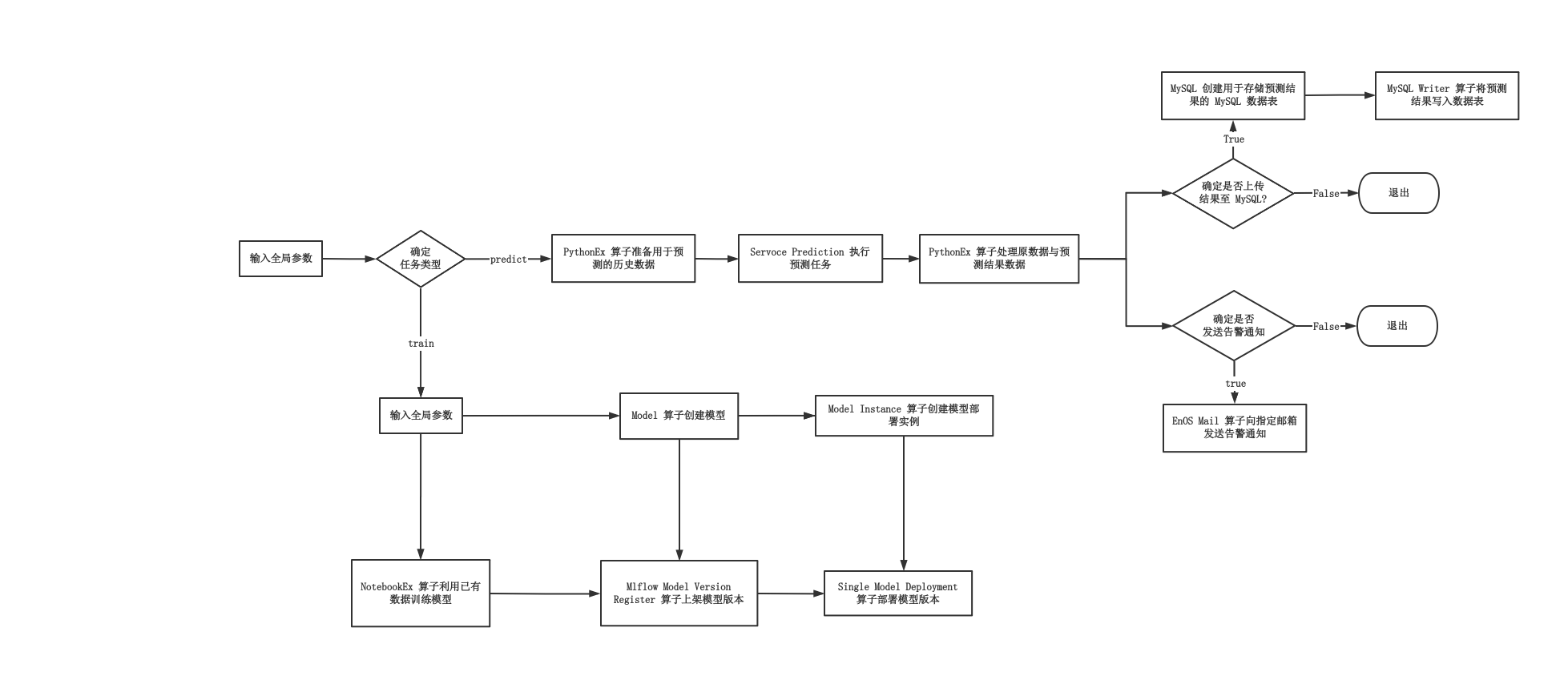
本单元介绍如何设计任务流预测风机绕组的温升。你可以通过以下任一方法设计任务流:
方法 1:基于样例任务流快速设计任务流。
方法 2:从头开始设计任务流,熟悉智能任务流的整体功能。
有关本教程中使用到的算子的更多信息,参见 算子参考。
方法 1:基于样例任务流设计任务流¶
如需快速了解如何通过编排智能任务流中的算子执行预测任务,可导入样例任务流并基于此设计任务流预测风机绕组的温升。
步骤 1:导出样例任务流¶
为了基于样例任务流构建自定义任务流,首先需要通过以下步骤导出样例任务流:
登录 EnOS 管理控制台并在左侧导航栏中选择 智能工作室 > 智能任务流。
在 样例任务流 标签页中选择 wind-engine-temperature-predicting 样例任务流的 任务流查看 按钮。
选择 导出
 导出样例任务流配置。
导出样例任务流配置。
步骤 2:导入样例任务流¶
通过以下步骤导入样例任务流配置文件,从而复用样例任务流的任务流结构、算子以及全局参数等信息:
在左侧导航栏中选择 智能工作室 > 智能任务流。
在自建任务流标签页中选择的 新建实验。
在弹窗中输入
temp-rise作为此实验的名称。选择 确定 创建实验并打开此实验的任务流画布,进行任务流的设计和开发。
选择 导入 按钮
 ,导入样例任务流配置文件。
,导入样例任务流配置文件。
步骤 3:配置全局参数¶
为了让任务流设计过程更为简单高效,你可以将全局适用的参数设置为全局参数,避免重复配置。本教程中使用的全局参数已包含于样例任务流中。选择画布右侧的 任务流设置 图标配置全局参数。其中各个参数的含义如下所示。
编号 |
参数 |
说明 |
|---|---|---|
1 |
tasktype |
|
2 |
model |
指定模型名称,指定执行训练或预测任务的模型。 |
3 |
instance |
指定 model 中所选模型的实例名称。 |
4 |
resourcepool |
选择用于模型部署的资源池。 |
5 |
enable_alert_email |
|
6 |
mysql_source |
指定用于存储预测结果的 MySQL 数据源。 |
7 |
Threshold |
指定温升阈值。如果温升超过阈值,将发送告警电子邮件。 |
8 |
prediction_model |
指定用于执行预测任务的模型。 |
9 |
prediction_instance |
指定 prediction_model 中所选模型的实例名称,用于执行预测任务。 |
10 |
dataset_name |
指定用于预测和训练任务的数据集。 |
11 |
sample_ratio |
指定用于将 dataset_name 中指定的数据集拆分为训练集和预测集的比率。 |
12 |
receivers |
选择接收告警电子邮件的用户。 |
13 |
copyto |
选择接收抄送的告警电子邮件的用户。 |
14 |
locale |
|
15 |
incident |
输入告警通知电子邮件的文本。 |
16 |
priority |
输入告警通知电子邮件的优先级。 |
步骤 4:查看主画布中的算子¶
主画布包含以下 2 个算子。
Do Train:当 tasktype 参数为
train时,执行训练任务。Do Predict:当 tasktype 参数为
perdict时,执行预测任务。
步骤 5:查看训练任务的算子¶
选择 Do Train 算子的 展开  以打开此算子的子画布,其中包含以下算子。
以打开此算子的子画布,其中包含以下算子。
名称 |
描述 |
|---|---|
NotebookEx |
|
Model |
此 Model 算子用于创建模型。 |
Mlflow Model Version Register |
此 Mlflow Model Version Register 算子用于为指定的模型注册 Mflow 模型版本。 |
Model Instance |
此 Model Instance 算子用于创建模型部署实例。 |
Single Model Deployment |
此 Single Model Deployment 算子用于部署在 Mlflow Model Version Register 算子中注册的模型版本。 |
步骤 6:查看预测任务的算子¶
选择 Do Predict 算子的 展开 以打开其子画布,其中包含以下算子。
名称 |
描述 |
|---|---|
Get History Data to Predict the Future |
|
Predict |
此 Service Prediction 算子用于使用已训练的模型执行预测任务,并输出预测结果。 |
Process Results |
|
Check MySQL Config |
此 PythonCode 算子用于检查是否可以将预测结果保存至 EnOS MySQL。 |
Condition for Training Alert |
此 Condition 算子用于在 enable_alert_email 全局参数为 true 的情况下向指定用户发送告警电子邮件。其子画布包含用于向指定用户发送告警电子邮件的 EnOS Mail 算子。 |
Export to MySQL? |
|
方法 2:新建任务流预测温升¶
你也可以从头开始利用算子设计一个低代码任务流,计算风力发电机组绕组温升并将计算结果上传到 MySQL 数据源中。有关相关算子的更多信息,参见 算子参考文档。
步骤 1:新建实验¶
在左侧导航栏中选择 智能工作室 > 智能任务流。
在自建作业流标签页中选择 新建实验。
在弹窗中输入
temp-rise作为此任务流的名称。选择 确定 创建实验并打开此实验的画布页面,设计任务流。
步骤 2:添加全局参数¶
为了让任务流设计过程更为简单高效,通过以下步骤将全局适用的参数设置为全局参数从而避免重复配置:
在 temp-rise 任务流画布中选择 任务流设置
 打开任务流设置面板。
打开任务流设置面板。在任务流设置面板的配置参数部分选择 添加参数 并添加以下全局参数。
编号 |
名称 |
类型 |
说明 |
|---|---|---|---|
1 |
tasktype |
string |
|
2 |
model |
string |
指定模型名称,指定执行训练或预测任务的模型。 |
3 |
instance |
string |
指定 model 中所选模型的实例名称。 |
4 |
resourcepool |
resourcepool |
选择用于模型部署的资源池。 |
5 |
enable_alert_email |
boolean |
|
6 |
mysql_source |
mysql_source |
指定用于存储预测结果的 MySQL 数据源。 |
7 |
Threshold |
number |
指定温升阈值。如果温升超过阈值,将发送告警电子邮件。 |
8 |
prediction_model |
model_name |
指定用于执行预测任务的模型。 |
9 |
prediction_instance |
model_instance |
指定 prediction_model 中所选模型的实例名称,用于执行预测任务。 |
10 |
dataset_name |
string |
指定用于预测和训练任务的数据集。 |
11 |
sample_ratio |
number |
指定用于将 dataset_name 中指定的数据集拆分为训练集和预测集的比率。 |
12 |
receivers |
user_contact_list |
选择接收告警电子邮件的用户。 |
13 |
copyto |
user_contact_list |
选择接收抄送的告警电子邮件的用户。 |
14 |
locale |
locale |
|
15 |
incident |
string |
输入告警通知电子邮件的文本。 |
16 |
priority |
string |
输入告警通知电子邮件的优先级。 |
步骤 3:配置主画布中的算子¶
你需要在主画布中添加两个 Condition 算子:
执行训练任务的 Condition 算子:当 tasktype 参数为
train时,执行训练任务。执行预测任务的 Condition 算子:当 tasktype 参数为
perdict时,执行预测任务。
添加执行训练任务的 Condition 算子¶
从左侧算子列表中拖拽一个 Condition 算子到画布中。
选择此算子并在右侧面板中配置以下信息:
在基本信息部分输入
Do Train作为算子名称。在配置参数部分中配置表达式为
Reference|tasktype|==|Declaration|train。
添加执行预测任务的 Condition 算子¶
从左侧算子列表中拖拽一个 Condition 算子到画布中。
选择此算子并在右侧面板中配置以下信息:
在基本信息部分输入
Do Predict作为算子名称。在配置参数部分中配置表达式为
Reference|tasktype|==|Declaration|predict。
步骤 4:配置用于执行训练任务的算子¶
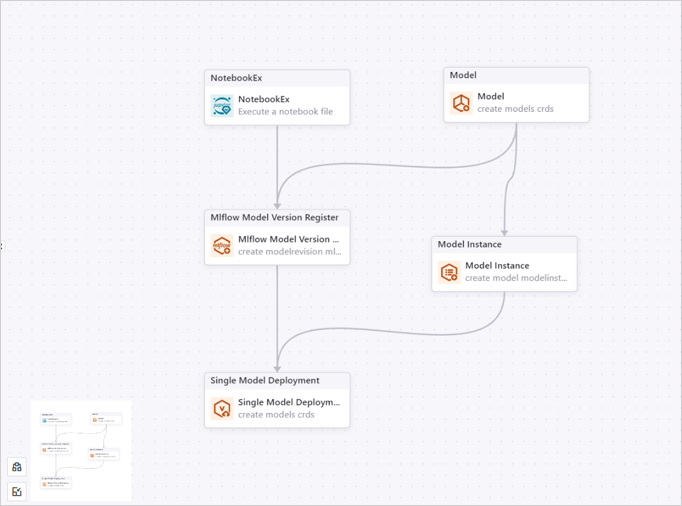
本教程中的训练过程包括创建模型、训练模型、创建模型实例、创建模型版本和部署模型版本。双击 Do Train 算子打开此算子的子画布。你需要在 Do Train 子画布中添加以下 5 个算子:
利用样例数据集训练模型并输出已训练模型的 NotebookEx 算子。
创建模型的 Model 算子。
注册并导出模型版本的 Mlflow Model Version Register 算子。
创建模型部署实例的 Model Instance 算子。
部署已注册的模型版本的 Single Model Deployment 算子。
配置用于训练模型的 NotebookEx 算子¶
从左侧算子列表中拖拽一个 NotebookEx 算子到 Do Train 子画布。
选择此 NotebookEx 算子并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
workspace
声明
选择在 单元 3:准备代码 中创建的 Notebook 实例和文件夹,指定 entrypoint 和 requirement 参数中所需文件的目录。
entrypoint
声明
选择
Train.ipynb,指定模型训练的代码文件。requirement
声明
选择
requirements_train.txt指定模型训练所需的依赖包。在 输入参数 部分选择 添加参数 并重复 3 次,添加 3 个输入参数并配置以下信息。
名称
类型
引用/声明
参数值
描述
epochs
number
声明
10
使用训练数据集训练模型,并重复 10 次。
dataset
string
引用
dataset_name
将 dataset_name 全局参数中指定的数据集用于模型训练。
ratio
number
引用
sample_ratio
引用 sample_ratio 全局参数中指定的比率将数据集拆分为训练集和预测集。
配置用于创建模型的 Model 算子¶
从左侧算子列表中拖拽一个 Model 算子到 Do Train 子画布。
选择此 Model 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
category
声明
选择
Predictor,创建用于执行预测任务的模型。model_name
引用
选择
model,将模型名称配置为 model 全局参数的值。input_data_type
声明
选择
Tabular作为模型的输入数据类型。scope
声明
选择
Public,让模型对当前 OU 中的所有智能工作室用户可用。technique
声明
选择
Regression。usecase
声明
选择
Wind,声明此模型适用于风电相关的场景。input_format
声明
输入 模型输入格式 中的代码,指定模型的输入格式。
interface
声明
选择
REST作为模型 API 接口的格式。output_format
声明
输入 模型输出格式 中的代码,指定模型的输出格式。
error_on_exist
声明
选择
false,当模型名称已存在时系统不会报错。
模型输入格式
在 Model 算子中创建的模型的输入格式如下所示。
[
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "gen_active_pw",
"range": [],
"repeat": 0
},
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "gen_speed",
"range": [],
"repeat": 0
},
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "torque",
"range": [],
"repeat": 0
},
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "tem_in",
"range": [],
"repeat": 0
},
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "tem_out",
"range": [],
"repeat": 0
},
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "wind_speed",
"range": [],
"repeat": 0
},
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "rotor_speed",
"range": [],
"repeat": 0
},
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "tem_var",
"range": [],
"repeat": 0
}
]
模型输出格式
在 Model 算子中创建的模型的输出格式如下所示。
[
{
"annotations": "",
"defaultValue": null,
"dtype": "float",
"ftype": "continuous",
"name": "tem_var",
"range": [],
"repeat": 0
}
]
配置用于注册模型版本的 Mlflow Model Version Register 算子¶
从左侧算子列表中拖拽一个 Mlflow Model Version Register 算子到 Do Train 子画布。
将 Model 算子和 NotebookEx 算子的输出锚点连接到此 Mflow Model Version Register 算子的输入锚点。
选择此 Mlflow Model Version Register 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
input_data
声明
输入 模型版本输入数据 中的代码,指定模型版本的输入数据。
version_rule
声明
选择
time,根据算子运行的时间命名模型版本。architecture
声明
选择
x86作为运行模型版本的基本硬件信息。framework
声明
选择
tensorflow作为运行模型版本的计算框架。language
声明
选择
python3作为模型版本的开发语言。model_reference
引用
选择 Model 算子的
model.model_name_output输出参数,指定模型版本所属的模型。minio_paths
引用
选择 NotebookEx 算子的
NotebookEx.mlflow_model_file_paths输出参数,指定模型版本的 minio 路径。
模型版本输入数据
在 Mlflow Model Version Register 算子中创建的模型版本的输入数据如下所示。
{
"data": {
"names": [
"gen_active_pw",
"gen_speed",
"torque",
"tem_in",
"tem_out",
"wind_speed",
"rotor_speed",
"tem_var"
],
"ndarray": [
[
19.646925,
963.533899,
9311.739885,
19.948558,
6.743743,
6.990860,
13.066677,
932.398765
],
[
20.020045,
1010.172848,
10268.291071,
19.698487,
6.722673,
7.189325,
13.955926,
1070.147035
]
]
}
}
配置用于创建模型部署实例的 Model Instance 算子¶
从左侧算子列表中拖拽一个 Model Instance 算子到 Do Train 子画布。
将 Model 算子的输出锚点连接到此 Model Instance 算子的输入锚点。
选择此 Model Instance 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
name
引用
选择
instance,将模型实例命名为 instance 全局参数的值。resource_pool
引用
选择
resource_pool,将 resource_pool 全局参数中指定的资源池用于部署实例。model_name
引用
选择 Model 算子的
Model.model_name_output输出参数,指定部署实例所属的模型。deploy_mode
声明
选择
ONLINE作为部署模式。error_on_exist
声明
选择
false,当模型版本名称已存在时系统不会报错。
配置用于部署模型版本的 Single Model Deployment 算子¶
从左侧算子列表中拖拽一个 Single Model Deployment 算子到 Do Train 子画布。
将 Model Instance 算子和 Mlflow Model Version Register 算子的输出锚点连接到此 Single Model Deployment 算子的输入锚点。
选择此 Single Model Deployment 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
model_version
引用
选择 Mlflow Model Version Register 算子的
Mlflow Model Version Register.model_revision_name输出参数,指定要部署的模型版本。instance_name
引用
选择 Model Instance 算子的
Model Instance.instance_name_output输出参数,指定模型版本部署的部署实例。request_CPU
声明
输入
0.1以指定模型版本部署所需的 CPU 资源。limit_CPU
声明
输入
0.5以指定模型版本部署的 CPU 资源上限。request_memory
声明
输入
1.0以指定模型版本部署所需的内存资源。limit_memory
声明
输入
1.0以指定模型版本部署的内存资源上限。
配置完成的 Do Train 子画布如下所示。
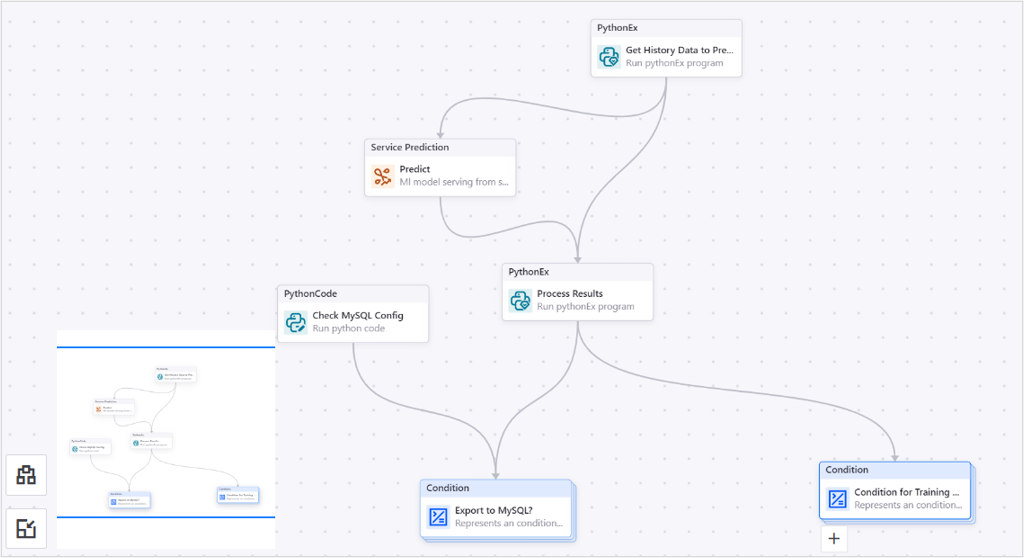
步骤 5:配置用于预测任务的算子¶
本教程中的训练过程包括准备数据、预测、处理结果、存储结果和配置告警通知。在主画布上,双击 Do Predict 算子打开其子画布。你需要在 Do Predict 子画布中添加以下 6 个算子:
用于为预测任务准备数据的 PythonEx 算子。
用于执行预测任务的 Service Prediction 算子。
用于收集和处理预测结果的 PythonEx 算子。
用于检查 MySQL 数据源是否可用于存储预测结果的 PythonCode 算子。
用于在 MySQL 数据源可用的情况下,将预测结果存储到 MySQL 数据源的 Condition 算子。
用于发送告警通知的 Condition 算子。
配置用于为预测任务准备数据的 PythonEx 算子¶
从左侧算子列表中拖拽一个 PythonEx 算子到 Do Predict 子画布。
选择此 PythonEx 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
workspace
声明
选择在 单元 3:准备代码 中创建的 Notebook 实例和文件夹,指定 entrypoint 和 requirement 参数中所需文件的目录。
entrypoint
声明
选择
prepare_predict_history_data.py以指定模型训练的代码文件。requirement
声明
选择
requirements_predict.txt以声明模型训练所需的依赖包。在 输入参数 部分选择 添加参数 并重复 2 次,添加 2 个输入参数并配置以下信息。
名称
类型
引用/声明
参数值
描述
dataset
string
引用
dataset_name
将 dataset_name 全局参数中指定的数据集作为预测数据集。
ratio
number
引用
sample_ratio
引用 sample_ratio 全局参数中指定的比率,将数据集拆分为训练集和预测集。
在 输出参数 部分选择 添加参数 并重复 2 次,添加 2 个输出参数并配置以下信息。
名称
类型
data
file
predict_data
file
配置用于执行预测任务的 Service Prediction 算子¶
从左侧算子列表中拖拽一个 Service Prediction 算子到 Do Predict 子画布。
将 PythonEx 算子的输出锚点连接到此 Service Prediction 算子的输入锚点。
选择此 Service Prediction 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
model
引用
选择
prediction_model,将 prediction_model 全局参数中指定的模型用于预测任务。instance
引用
选择
prediction_instance,将 prediction_instance 全局参数中指定的模型实例用于预测任务。namespace
引用
选择
resourcepool,将 resource_pool 全局参数中指定的资源池用于预测任务。data_type
声明
选择
csv作为预测数据的文件格式。data
引用
选择 PythonEx 算子的
PythonEx.predict_data输出参数,将处理后的数据用于预测任务。
配置用于处理预测结果的 PythonEx 算子¶
从左侧算子列表中拖拽一个 PythonEx 算子到 Do Predict 子画布。
将第一个 PythonEx 算子以及 Service Prediction 算子的输出锚点连接到此 PythonEx 算子的输入锚点。
选择此 PythonEx 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
workspace
声明
选择在 单元 3:准备代码 中创建的 Notebook 实例和文件夹,指定 entrypoint 和 requirement 参数中所需文件的目录。
entrypoint
声明
选择
process_results.py,指定模型训练的代码文件。requirement
声明
选择
requirements_predict.txt以声明模型训练所需的依赖包。在 输入参数 部分选择 添加参数 并重复 4 次,添加 4 个输入参数并配置以下信息。
名称
类型
引用/声明
参数值
描述
predictions
file
引用
Service Prediction.predictions
从 Service Prediction 算子获取预测结果。
data
file
引用
PythonEx.data
获取风机绕组温度的原始数据。
threshold
number
引用
threshold
指定温升阈值。如果温升超过阈值,将发送告警电子邮件。
enable_alert
boolean
引用
enable_alert_email
根据 enable_alert_email 全局参数的值启用或禁用告警通知功能。
在 输出参数 部分选择 添加参数 并重复 3 次,添加 3 个输出参数并配置以下信息。
名称
类型
result
file
alert
boolean
content
string
配置用于检查 MySQL 配置的 PythonCode 算子¶
从左侧算子列表中拖拽一个 PythonCode 算子到 Do Predict 子画布。
选择此 PythonCode 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
code
声明
输入 MySQL 检查代码 中的代码检查 MySQL 配置。
在 输入参数 部分选择 添加参数 并配置以下信息。
名称
类型
引用/声明
参数值
描述
mysql_source
mysql_source
引用
mysql_source
指定 MySQL 数据源,检查此数据源是否可用于存储预测结果。
在 输入参数 部分选择 添加参数 并配置以下信息。
名称
类型
export_to_mysql
boolean
MySQL 检查代码
检查 MySQL 数据源是否可用于存储预测结果的代码如下所示。
# Sample imports
import json
import argparse
from pathlib import Path
# Define an ArgumentParser
parser = argparse.ArgumentParser()
parser.add_argument("--mysql_source", type=str, required=True)
parser.add_argument("--export_to_mysql", type=str, required=True)
# Parse arguments from command
args = parser.parse_args()
Path(args.export_to_mysql).parent.mkdir(parents=True, exist_ok=True)
with open(args.export_to_mysql, 'w') as f:
f.write('True' if args.mysql_source else 'False')
配置用于将结果存储到 MySQL 数据源的 Condition 算子¶
从左侧算子列表中拖拽一个 Condition 算子到 Do Predict 子画布。
将第二个 PythonEx 算子以及 PythonCode 算子的输出锚点连接到此 Condition 算子的输入锚点。
选择此算子,并在右侧面板为此 Condition 算子配置以下表达式。
Reference | PythonCode.export_to_mysql | == | Declaration | True
按照以上所述配置此 Condition 算子后,你需要双击此算子以打开其子画布并添加以下 2 个算子:
用于创建数据表的 Mysql 算子。
用于将预测结果写入由 Mysql 算子创建的数据表的 Mysql Writer 算子。
配置用于创建数据表的 Mysql 算子¶
从左侧算子列表中拖拽一个 Mysql 算子到 Condition 子画布。
选择此 Mysql 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
data_source_name
引用
选择
mysql_source,在 mysql_source 全局参数中指定的 MySQL 数据源中创建表。sqls
声明
输入 数据表创建代码 中的代码创建数据表。
数据表创建代码
用于创建数据表的代码如下所示。
"CREATE TABLE if not exists predicted_demo (data_time_utc timestamp DEFAULT CURRENT_TIMESTAMP, predicted float, actual float, threshold float, is_abnormal TINYINT(1));"
配置将数据写入数据表的 Mysql Writer 算子¶
从左侧算子列表中拖拽一个 Mysql Writer 算子到 Condition 子画布。
选择此 Mysql Writer 算子,并在右侧面板的 输入参数 部分配置以下算子参数。
参数
引用/声明
描述
data_source_name
引用
选择
mysql_source,将预测结果写入在 mysql_source 全局参数中指定的 MySQL 数据源。statement
声明
输入 MySQL 写入代码 中的代码,将结果数据写入到 Mysql 算子创建的数据表中。
data
引用
选择用于处理结果的 PythonEx 算子的
PythonEX(1).result输出参数作为要写入数据表的数据。
MySQL 写入代码
将预测结果数据写入到数据表的代码如下所示。
INSERT IGNORE INTO `predicted_demo` (`data_time_utc`, `predicted`, `threshold`, `is_abnormal`) VALUES (%s, %s, %s, %s);
配置用于判断是否发送告警电子邮件的 Condition 算子¶
从左侧算子列表中拖拽一个 Condition 算子到 Do Predict 子画布。
在右侧面板上将第二个 PythonEx 算子的输出锚点连接到此 Condition 算子的输入锚点。
选择此 Condition 算子,并配置以下表达式。
Reference | PythonEx(1).alert | == | Declaration | True
此 Condition 算子配置后,双击此算子以打开其子画布并添加 EnOS Mail 算子,从而向 EnOS 用户发送告警通知邮件。
配置用于发送告警通知邮件的 EnOS Mail 算子¶
从左侧算子列表中拖拽一个 EnOS Mail 算子到 Condition(1) 子画布。
选择此 EnOS Mail 算子,并在右侧面板的 输入参数 部分配置以下信息。
参数
引用/声明
描述
receivers
引用
选择
receivers,将告警通知邮件发送到 receivers 全局参数中的用户。copyto
引用
选择
copyto,将告警通知邮件抄送给 copyto 全局参数中的用户。locale
引用
选择
locale,使用 locale 全局参数中规定的语言发送告警通知邮件。module
声明
选择
Model Hub,表明告警与智能集市模块的模型有关。target
引用
选择
model,将告警对象设置为 model 全局参数中指定的模型。incident
引用
选择
incident,将与告警相关的事件配置设置 incident 全局参数中的内容。detail
引用
选择用于处理结果的 PythonEx 算子的
PythonEx(2).content输出参数作为告警的详细内容。priority
引用
选择
priority,将告警的优先级配置为 priority 全局参数的值。
配置上述算子后,从面包屑导航中选择 Do Predict 返回 Do Predict 子画布。配置完成的 Do Predict 子画布如下所示。