智能集市故障排除¶
本文用于识别并解决使用智能集市过程中的一些问题。
构建模型时报错:Need GNU Compiler Collection¶
在智能集市中构建模型时报错: need GNU Compiler Collection(GCC)。
故障原因¶
Wheel 包缺失导致报错。
解决方案¶
在 智能集市 中打开模型所在的 Notebook 实例。
在 Notebook 终端中运行以下命令以上传 wheel 包:
pip install thriftpy
模型版本测试失败并报错:NO such file or directory:’model’¶
通过 MLFlow 导入的模型版本上架后,模型测试失败并出现以下错误信息:NO such file or directory:'model'。
故障原因¶
The value of model parameter in mlflow.{framework}.log_model 命令中 model 的参数值不是 model。其中,Framework 指 Mlflow 过程中所使用的框架。
解决方案¶
在 智能集市 中打开模型所在的 Notebook 实例。
在 文件浏览器 中打开 JupyterLab 文件。
检查
mlflow.{framework}.log_model命令,将 model 的参数值改为model。
模型版本测试失败并报错:IsADirectoryError:[ERROR 21] is a directory :’/microservice/model’¶
通过 MLFlow 导入的模型版本上架后,模型测试失败并出现以下错误信息:IsADirectoryError:[ERROR 21] is a directory :'/microservice/model'。
故障原因¶
使用 Mlflow 1.9 或以上版本会导致该报错。智能集市目前支持 Mlflow 1.8 及以下版本。
解决方案¶
使用 Mlflow 1.8.0 或以下版本导入模型,并注册模型版本。你可以通过以下步骤安装 Mlflow 1.8.0:
在 智能集市 中打开模型所在的 Notebook 实例。
在 文件浏览器 中打开 JupyterLab 文件。
运行以下命令:
conda install Mlflow==1.8.0
安装完成后,重新上架模型版本并测试。
模型版本测试失败并报错:ModuleNotFoundError: No module named ‘{framework}’¶
通过 MLFlow 导入的模型版本上架后,模型测试失败并出现以下错误信息:ModuleNotFoundError: No module named '{framework}'。其中,Framework 指 Mlflow 过程中所使用的框架。
故障原因¶
原因 1:训练代码中使用了错误的服务框架。
原因 2:log_model 命令中使用了错误的调用方法。
解决方案¶
在 智能集市 中打开模型所在的 Notebook 实例。
在 文件浏览器 中打开 JupyterLab 文件。
运行以下命令:
对于原因 1:运行
import mlflow.{framework}命令,导入正确的服务框架。对于原因 2: 运行
mlflow.{framework}.log_model命令,调用正确的服务框架。
重新上架模型版本并测试。
模型版本测试失败并报错:AttributeError: ‘str’ object has no attribute ‘decode’¶
通过 MLFlow 导入的模型版本上架后,模型测试失败并出现以下错误信息:AttributeError: 'str' object has no attribute 'decode'。
故障原因¶
H5py 版本冲突导致报错。智能集市支持 H5py 2.10.0。
解决方案¶
在 智能集市 中打开模型所在的 Notebook 实例。
在 文件浏览器 中打开 JupyterLab 文件。
运行以下命令:
conda install h5py==2.10.0
安装完成后,重新上架模型版本并测试。
模型版本测试失败并报错:File “/microservice/MlflowPredictor.py”, line 30, in predict¶
通过 MLFlow 导入的模型版本上架后,模型测试失败并出现以下错误信息:File "/microservice/MlflowPredictor.py", line 30, in predict。
故障原因¶
模型文件错误导致报错。
解决方案¶
在模型测试页面,复制左侧代码框中的代码。
在 智能集市 中打开模型所在的 Notebook 实例。
在 Notebook 实例中粘贴已复制的代码,以测试模型。
根据测试结果,在本地模型文件中修改错误。 ## 模型版本测试失败并报错:TypeError: an integer is required (got type bytes)
通过 MLFlow 导入的模型版本上架后,模型测试失败并出现以下错误信息:TypeError: an integer is required (got type bytes)。该报错信息在报错日志中如下图所示:
故障原因¶
原因 1:使用 tensorflow 1.15 或以下版本训练模型。
原因 2:Notebook 中的依赖包版本与 Mlflow 上架时使用的依赖包版本不一致。
原因 3:Notebook 的 Python 版本与 Mlflow 上架时使用的依赖包版本不一致。
解决方案¶
对于原因 1:更新 tensorflow 框架版本至 2.3.1。
对于原因 2:通过以下步骤修复依赖包版本冲突:
在 智能集市 中打开模型所在的 Notebook 实例。
在 文件浏览器中打开 conda.yaml 文件。
检查并修改 conda.yaml 中的依赖包版本,使其与 Mlflow 上架时使用的依赖包版本一致。
对于原因 3:通过以下步骤修复 Python 版本冲突:
在 智能集市 中打开模型所在的 Notebook 实例。
在终端中运行
python -命令,查看 Notebook 的 Python 版本。检查并修改 Notebook 中的 Python 版本,使其与 Mlflow 上架时使用的 Python 版本一致。
模型可在 Notebook 中运行,但模型版本上架或测试失败¶
你可以在 Notebook 中成功运行模型,但在模型版本上架或模型版本测试时失败。
故障原因¶
模型输入参数被封装为 dataframe。 通过以下步骤检查具体原因:
在 智能集市 中打开模型所在的 Notebook 实例。
在 文件浏览器 中打开 JupyterLab 文件。
运行
mlflow.{framework}.save_model命令,将模型文件保存至 Notebook。 其中,Framework指模型使用的机器学习框架。运行
mlflow.pyfunc.load_model命令,检查是否可以加载模型。若加载模型成功,通过
pd.dataframe函数将预测数据封装为 dataframe,并运行predict函数以进行模型预测。
解决方案¶
解决方案 1:如果加载模型失败,检查本地模型文件,并修改文件中的错误。
解决方案 2:如果模型预测成功,记录下 mlflow 和 python 的版本号并联系管理员。
上架模型版本时出现包戳:test success, number of test result not match repeat from model¶
若模型的输出参数类型为 object,上架模型版本时出现以下错误信息: test success, number of test result not match repeat from model 。
故障原因¶
模型的输出结果不是 object 类型。
解决方案¶
检查并修改输出参数,确保参数值为 object 类型。object 类型的示例如下所示:
[{ "data": [ ["2021-07-31", 5, 6], ["2021-07-31", 5, 6], ["2021-07-31", 5, 6]]}]
测试或部署模型版本时,日志文件不完整¶
测试或部署模型版本时,日志文件不完整。
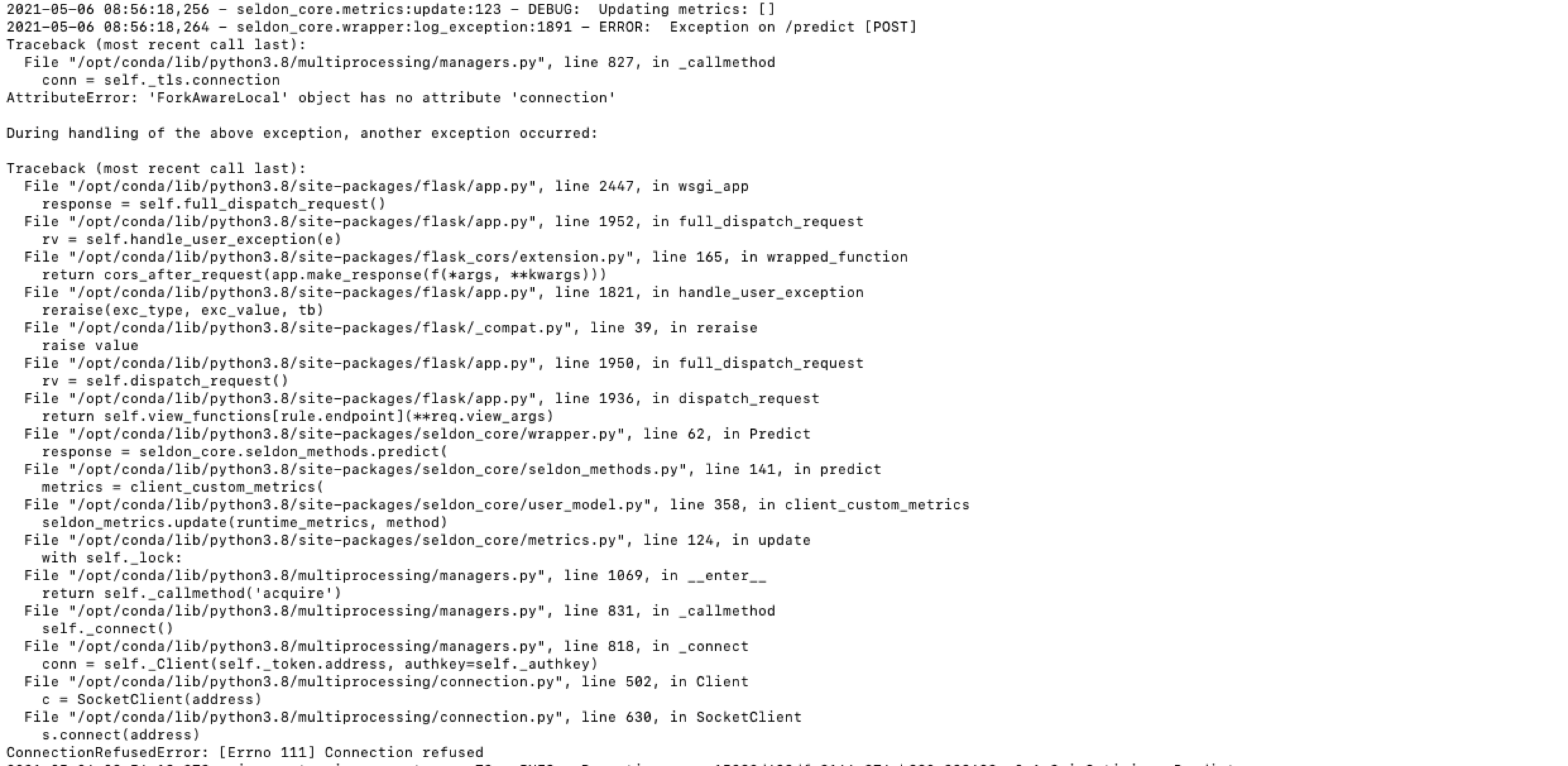
故障原因¶
内存不足导致进程关闭。
解决方案¶
解决方案 1:如果测试模型时发生错误,在 输入参数 中添加
force_to_stage参数,以强制上架模型版本。 如需了解更多模型参数的信息,可参考 Set Model Parameters。解决方案 2:如果部署模型时发生错误,增加 Resource Request 和 Resource Limit 的参数值并重试。 如需了解更多模型部署的信息,可参考 Deploy a Model Version.
使用 Cloudpickle 序列化时出错¶
使用 Cloudpickle 进行序列化时出现如下错误:
File "/opt/conda/lib/python3.8/site-packages/mlflow/pyfunc/__init__.py", line 522, in load_model
model_impl = importlib.import_module(conf[MAIN])._load_pyfunc(data_path)
File "/opt/conda/lib/python3.8/site-packages/mlflow/pyfunc/model.py", line 223, in _load_pyfunc
python_model = cloudpickle.load(f)
AttributeError: Can't get attribute '_make_function' on <module 'cloudpickle.cloudpickle' from '/opt/conda/lib/python3.8/site-packages/cloudpickle/cloudpickle.py'>
2022-06-07 01:44:27,878 - jaeger_tracing:report_span:73 - INFO: Reporting span 874aec19bfb8dc2f:b5d9f8f14bbebca4:0:1 MlflowPredictor.Predict
2022/06/07 01:44:28 WARNING mlflow.pyfunc: The version of CloudPickle that was used to save the model, `CloudPickle 2.1.0`, differs from the version of CloudPickle that is currently running, `CloudPickle 2.0.0`, and may be incompatible
2022-06-07 01:44:28,388 - seldon_core.wrapper:log_exception:1891 - ERROR: Exception on /predict [POST]
Traceback (most recent call last):
File "/opt/conda/lib/python3.8/site-packages/seldon_core/user_model.py", line 236, in client_predict
故障原因¶
模型训练中的模型版本与模型测试中的版本不一致。
解决方法¶
指定同一模型版本进行模型训练和模型测试。其最佳实践之一为:
env = {
'name': 'model',
'channels': ['default'],
'dependencies': [
'python=3.8.8',
{'pip': [
'mlflow==1.13.1',
'sklearn',
'cloudpickle=={}'.format(cloudpickle.__version__),
'eapdataset',
]}
]
}
wind_power_forecast_model = wind_power_forecast(model=fitted_model)
mlflow.pyfunc.log_model(artifact_path="model", python_model=wind_power_forecast_model, conda_env=env)