单元 4: 任务流设计¶
本节将通过以下方式介绍如何设计智能任务流:
基于样例任务流设计可供快速开始的任务流。
新建任务流以熟悉智能任务流的整体功能。
若要了解任务流产品中各类算子的功能和使用方法,可参考算子参考文档。
选项 1:基于样例任务流设计任务流¶
导出样例任务流¶
通过以下步骤导出样例任务流配置:
登录 EnOS 管理控制台,从左侧导航栏中选择 智能工作室 > 智能任务流,打开 实验列表 首页。
选择 样例作业流,找到 wind-power-forecast 并选择 任务流查看。本教程使用的样例任务流在 2.3 更新 1 中进行了更新。
选择导出
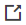 下载任务流配置文件。
下载任务流配置文件。
新建实验¶
通过以下步骤新建实验:
登录 EnOS 管理控制台,从左侧导航栏中选择 智能工作室 > 智能任务流,打开 实验列表 首页。
选择 新建实验,输入实验的名称(winddemo)和描述。
选择 确定,创建实验并打开实验的 任务流设计 页面,进行任务流的设计和开发。
选择导入
 将样例任务流配置导入。
将样例任务流配置导入。
更新全局参数设计¶
当任务流中有某些参数需经常变动且全局适用时,建议将其作为全局参数:
易于调试。调试代码时,全局参数的配置是全局性的,避免了重复每个算子中的相同参数的重新配置,将显著提升开发效率
易于传参调用。外部调用任务流时可以通过全局参数传递参数给算子使用
易于任务流模板沉淀。将需要变化的参数作为全局参数统一配置,也可保持算子本身设计的稳定性
本教程中使用的全局参数已在样例任务流中配置,可选择画布右侧的任务流设置图标  查看。其中每个参数的含义如下表所示:
查看。其中每个参数的含义如下表所示:
编号 |
参数名称 |
含义 |
|---|---|---|
1 |
resourcepool |
用于指定模型部署实例使用的资源池。需要更新为本 OU 下的资源池。 |
2 |
datasetname |
用于指定使用的数据集名称。本教程中使用的是样例数据集。 |
3 |
tasktype |
用于控制任务流的分支走向:
|
4 |
predictiontype |
用于控制任务流的预测类型:
|
5 |
lenoflist |
用于指定产生的 looplist 的长度。其值模拟的是实际场景中的风机数量,依据使用场景的不同而有不同定义。 |
6 |
modelinstnacename |
用于指定训练好的模型部署实例名称。 |
7 |
prediction_dataset_name |
用于指定训练数据集。 |
8 |
sample_split_ratio |
用于指定数据集中训练集和预测集的分配比例。 |
9 |
hdfs_source |
用于指定将模型文件上传的 HDFS 数据源。数据源需先在 数据源连接 中创建。 |
10 |
hive_source |
用于指定将预测结果上传的 Hive 数据源。数据源需先在 数据源连接 中创建。 |
11 |
ouid |
当前 OU ID。 |
12 |
prediction_instance |
用于指定预测任务的实例名称。当训练分支完成后,其值应与 modelinstnacename 一致以便使用训练好的模型进行预测。 |
主画布设计¶
主画布中包括以下两个条件逻辑算子:
Condition for Training:全局参数
tasktype==training时执行训练分支任务。Condition for Prediction:全局参数
tasktype==prediction时执行预测分支任务。
检查训练分支任务¶
双击 Condition for training 算子可进入其子画布,其中包含以下算子:
Recursion for Event Trigger,确定原始数据何时可用于模型训练的 Recursion 算子。在本教程中,其生成的随机数小于5,则表明数据准备就绪。
Generate Target List,生成一个循环列表用于后续 ParallelFor 算子循环并发训练任务的 PythonEx 算子。确保
workspace为 wind_power_forecasting 以及entrypoint为 generate_model_list.py 。Loop for Model Training,并发执行训练任务的 ParallelFor 算子。双击进入子画布可查看或编辑以下算子。
Operator Name |
Description |
|---|---|
Prepare Training Data |
此 PythonEx 算子用于准备训练数据并导出数据文件。确保 workspace 为 wind_power_forecasting、entrypoint 为 prepare_train_data.py 以及 requirements 为 requirements1.txt。 |
Model Training |
此 PythonEx 算子用于根据输入数据训练模型并输出训练模型。确保 workspace 为 wind_power_forecasting、entrypoint 为 train_model.py 以及 requirements 为 requirements2.txt。 |
Create a Model |
此 Model 算子用于创建一个模型。 |
Create a Model Revision |
此 Mlflow Model Version Register 算子用于在指定模型里注册一个 Mlflow 类型的模型版本。 |
Create a Model Instance |
此 Model Instance 算子用于创建一个模型的部署实例。 |
Create a Model Test Operator |
此 Model Test 算子用于测试模型版本是否为可发布成模型服务的有效模型。 |
Deploy the Model Revision |
此 Single Model Deployment 算子可基于已上架的模型版本部署单一模型版本的模型服务(或模型上线),上线成功后,会产生一个可供调用的模型服务。 |
检查预测分支任务¶
双击 Condition for Prediction 算子可进入其子画布,其中包含以下算子:
Generate Target List for prediction, 产生一个循环列表用于后续 ParallelFor 算子循环并发预测任务的 PythonEx 算子。确保
workspace为 wind_power_forecasting 以及requirements为 generate_model_list.py。Loop For prediction,并发执行预测任务的 ParallelFor 算子。Loop For prediction 子画布包含以下 2 个算子:
Condition for Service Prediction Type 算子:当全局参数 predictiontype 的参数值为
service时,基于已发布模型服务执行模型预测任务。Condition for Model File Prediction 算子:当全局参数 predictiontype 的参数值为
file时,基于 Mlflow 模型文件执行模型预测任务。
Condition for Service Prediction Type 算子¶
此算子基于已发布的模型服务进行预测。双击可进入子画布,其中包含以下算子:
算子名称 |
功能描述 |
|---|---|
Prepare Prediction Data |
此 PythonEx 算子用于准备预测使用的数据,通过 result_datafile file 类型的输出参数提供给预测算子使用。确保 |
Predict from Service |
此 Service Prediction 算子基于模型服务进行预测,通过 predictions file 型参数返回预测结果。 |
Write results |
此 PythonEx 算子用于接收预测算子的预测结果并将结果写入文件。确保 |
Check Hive Config |
此 PythonCode 算子用于检查当前 OU 下是否有 Hive 库可供预测结果存储。确保 |
Export to Hive? |
|
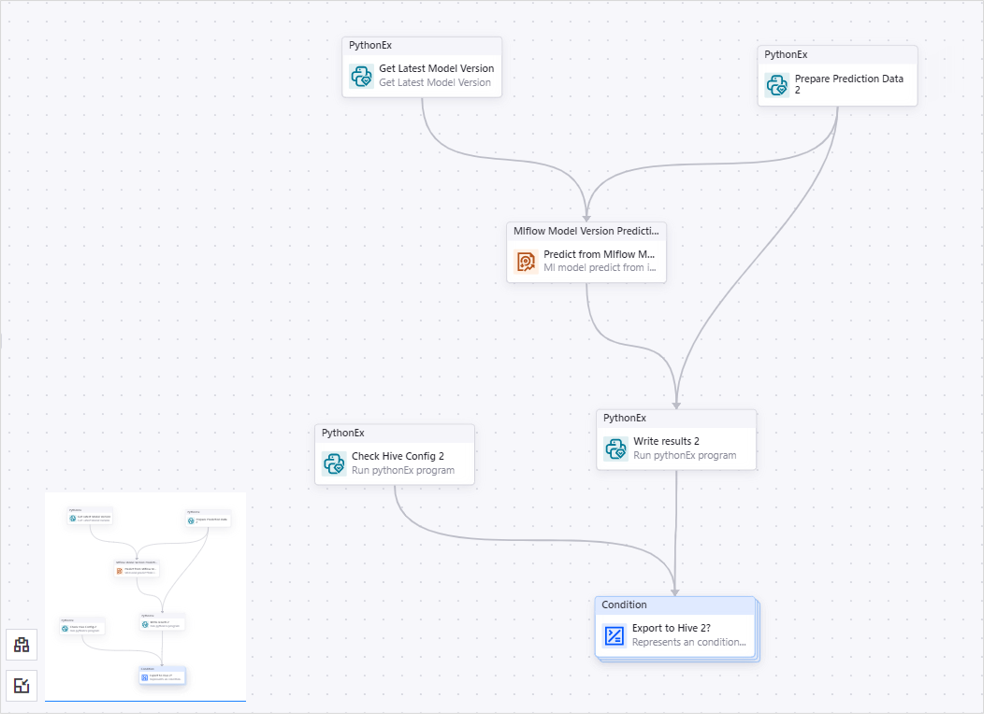
Condition for Model File Pprediction 算子¶
此算子基于 Mlflow 模型文件进行预测。双击可进入子画布,其中包含以下算子:
算子名称 |
功能描述 |
|---|---|
Get Latest Model Version |
此 PythonEx 算子用于获取该模型下的最新模型版本用以预测。确保 |
Prepare Prediction Data 2 |
此 PythonEx 算子用于准备预测使用的数据,通过 result_datafile file 类型的输出参数提供给预测算子使用模型服务进行预测,预测结果通过 predictions file 型参数返回。确保 workspace 为 wind_power_forecasting、entrypoint 为 prepare_predict_data.py 以及 requirements 为 requirements1.txt。 |
Predict from Mlflow Model File |
此 Mlflow Model Version Prediction 算子基于 Mlflow 模型文件进行预测,通过 predictions file 类型参数返回预测结果。 |
Write results 2 |
此 PythonEx 算子用于接收预测算子的预测结果并将结果写入文件。确保 |
Check Hive Config 2 |
此 PythonCode 算子用于检查当前 OU 下是否有 Hive 库可供预测结果存储。确保 |
Export to Hive 2? |
|
选项 2:新建任务流¶
新建实验¶
通过以下步骤新建实验:
登录 EnOS 管理控制台,从左侧导航栏中选择 智能工作室 > 智能任务流 ,打开 实验列表 首页。
在 自建作业流 标签页中选择 新建实验。
在弹出窗口中输入实验的名称(winddemo)和描述。
选择 确定, 创建实验并打开实验的 任务流设计 页面,进行任务流的设计和开发。
添加全局参数¶
当任务流中的某些参数需经常变动且全局适用时,建议将其作为全局参数,从而提高配置效率且便于参数管理。
通过以下步骤配置全局参数:
选择任务流设置图标
,打开任务流设置页面。选择 添加参数,添加以下全局参数:
编号 |
名称 |
类型 |
参数值 |
|---|---|---|---|
1 |
resourcepool |
resource_pool |
用于指定模型部署实例使用的资源池。在下拉菜单中选择当前 OU 的主资源池。 |
2 |
dataset_name |
string |
用于指定使用的数据集。输入 sample-power-forecast 以使用该样例数据集。 |
3 |
tasktype |
string |
用于控制任务流的任务类型: 输入 training 进行训练任务,输入 prediction 进行预测任务。此处输入 training ,将预测任务设置为缺省任务类型。 |
4 |
predictiontype |
string |
用于控制任务流的预测类型:输入 file 进行 Mlflow 模型文件预测,输入 service 进行模型服务预测。此处输入 service 将模型服务预测设置为缺省预测类型。 |
5 |
lenoflist |
number |
用于指定生成 looplist 的长度。其值模拟的是在实际场景中的风机数量。输入 1 ,模拟一个风机的场景。 |
6 |
modelinstancename |
string |
用于指定训练好的模型部署实例名称。输入 kmmldsdeployinstance1 指定该模型部署实例。 |
7 |
prediction_dataset_name |
string |
用于指定执训练数据集。输入 sample-power-forecast 以使用此数据集训练模型。 |
8 |
sample_split_ratio |
number |
用于指定数据集中训练集与预测集的分配比例。 输入 0.75,将75%的数据用于模型训练,25%的数据用于模型预测。 |
9 |
hdfs_source |
hdfs_source |
用于指定上传模型文件的 HDFS 数据源,需预先在 数据源连接 中创建。在下拉菜单中选择 HDFS 数据源。 |
10 |
hive_source |
hive_source |
用于指定上传预测结果的 Hive 数据源,需预先在 数据源连接 中创建。在下拉菜单中选择 Hive 数据源。 |
11 |
ouid |
string |
用于指定所在 OU。 输入当前 OU ID。 |
12 |
prediction_instance |
model_instance |
用于指定预测任务的实例名称。当训练分支完成后,其值应与 modelinstnacename 一致以便使用训练好的模型进行预测。输入 kmmldsdeploymentinstance1 指定此预测实例。 |
主画布设计¶
主画布中包括两个 Condition 算子:
Condition 算子 1:任务类型为“训练”时执行训练分支任务。
Condition 算子 2:任务类型为“预测”时执行预测分支任务。
通过以下步骤添加 Condition 算子 1:
从算子列表中拖拽一个 Condition 算子到主画布中。
选择此算子,配置以下信息:
名称:输入
Condition for Training。表达式: 配置为
引用|tasktype|==|声明|training。
通过以下步骤添加 Condition 算子 2:
从算子列表中拖拽一个 Condition 算子到主画布中。
选择此算子,配置以下信息:
名称: 输入
Condition for Prediction。表达式:配置为
引用|tasktype|==|声明|prediction。
配置训练任务¶
本教程中,训练分支包含数据准备、模型训练、模型版本测试、模型部署等过程。在主画布中,双击 Condition for Training 算子打开子画布,你需要在 Condition for Prediction 子画布中添加 3 个算子:
Recursion 算子:确定原始数据何时可用于模型训练。在本教程中,其生成的随机数小于5,则表明数据准备就绪。
PythonEx 算子:生成用于后续 ParallelFor 算子循环并发训练的循环列表。
ParallelFor 算子:并发执行模型训练任务。
配置准备原始数据的 Recursion 算子¶
通过以下步骤添加 Recursion 算子:
从算子列表中拖拽一个 Recursion 算子到 Condition for Training 子画布中。
双击此 Recursion 算子,进入其子画布。
从算子列表中拖拽一个 PythonEx 算子到 Recursion 算子的子画布中。
选择此 PythonEX 算子, 配置以下信息:
名称:输入
Generate a Number between 1-10。workplace: 选择
wind_power_forecasting。entrypoint: 选择
generate_random_int.py。选择 输出参数 > 添加参数 为算子添加输出参数,并配置为
result_number|number。
选择导航栏上的 Condition for Training 标签,返回 Condition 算子子画布。
选择此 Recursion 算子,配置以下信息:
名称:输入
Recursion for Event Trigger。表达式:配置为
Reference|Generate a Number between 1-10.result_number|<|Declaration|5。
选择顶部工具栏的保存图标
 以保存配置信息。
以保存配置信息。
配置生成循环列表的 PythonEx 算子¶
通过以下步骤添加 PythonEx 算子:
从算子列表中拖拽一个 PythonEx 算子到 Condition for Training 子画布中。
连接 Recursion for Event Trigger 算子的输出锚点与该 PythonEx 算子的输入锚点。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Generate Target List。workspace: 选择
wind_power_forecasting。entrypoint: 选择
generate_model_list.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
lenoflist|number|Reference|lenoflist。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
result_number|list。
选择顶部工具栏的保存图标
以保存配置信息。
配置并发执行模型训练任务的 ParallelFor 算子¶
通过以下步骤添加 ParallelFor 算子:
从算子列表中拖拽一个 ParallelFor 算子到 Condition for Training 子画布中。
连接 Generate Target List 算子的输出锚点与该 ParallelFor 算子的输入锚点。
选择此 ParallelFor 算子,配置以下信息:
名称:输入
Loop for Model Training。输入参数:配置为
引用|Generate Target List.result_list|item。
Loop For Model Training 算子负责训练模型,并部署训练完成的模型。你需要在 Loop For Model Training 子画布中添加 7 个算子:
PythonEx 算子 1:处理训练所需的数据,并输出数据文件。
PythonEx 算子 2:基于数据训练模型,并输出训练过的模型。
Model 算子:创建一个新模型。
Mlflow Model Version Register 算子:在创建的模型里注册一个 Mlflow 类型的模型版本,并导出模型版本文件。
Model Instance 算子:创建模型部署实例。
Model Test 算子:测试模型版本是否可发布为有效模型。
Single Model Deployment 算子:基于已上架的模型版本部署单一模型版本。
通过以下步骤添加 PythonEx 算子 1:
从算子列表中拖拽一个 PythonEx 算子到 Loop For Model Training 子画布中。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Prepare Training Data。workspace: 选择
wind_power_forecasting。entrypoint: 选择
prepare_training_data.py。requirement:选择
requirement1.txt。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
datasetname|string|Reference|dataset_name。选择 输入参数 > 添加参数 为算子添加另一输入参数,并配置为
ratio|number|Reference|sample_split_ratio。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
result_datafile|file。
通过以下步骤添加 PythonEx 算子 2:
从算子列表中拖拽一个 PythonEx 算子到 Loop For Model Training 子画布中。
连接 Prepare Training Data 算子的输出锚点与该 PythonEx 算子的输入锚点。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Model Training。workspace: 选择
wind_power_forecasting。entrypoint: 选择
train_model.py。requirement:选择
requirement2.txt。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
result_datafile|file|Reference|Prepare Training Data.result_datafile。
通过以下步骤添加 Model 算子:
从算子列表中拖拽一个 Model 算子到 Loop For Model Training 子画布中。
选择此 Model 算子,配置以下信息:
名称:输入
Create a Model。category: 选择
model-predictor。model_name: 引用
item。input_data_type:选择
Text。scope:选择
private。technique:选择
matching。usecase:选择
Light field。publisher:选择
system。为 input_format 参数输入以下代码:
[ { "annotations": "", "defaultValue": 300, "dtype": "int", "ftype": "continuous", "name": "i.set", "range": [0, 440], "repeat": 0 },{ "annotations": "", "defaultValue": 300, "dtype": "int", "ftype": "continuous", "name": "X_basic.forecast_time", "range": [0, 440], "repeat": 0},{ "annotations": "", "defaultValue": 300, "dtype": "int", "ftype": "continuous", "name": "X_basic.horizon", "range": [0, 440], "repeat": 0},{ "annotations": "", "defaultValue": 8, "dtype": "int", "ftype": "continuous", "name": "X-basic.time", "range": [0, 49], "repeat": 0},{ "annotations": "", "defaultValue": 10, "dtype": "int", "ftype": "continuous", "name": "X-basic.hour", "range": [0, 23], "repeat": 0},{ "annotations": "", "defaultValue": 10, "dtype": "int", "ftype": "continuous", "name": "EC.nwp_time", "range": [0, 23], "repeat": 0},{ "annotations": "", "defaultValue": 1.5, "dtype": "float", "ftype": "continuous", "name": "EC.dist", "range": [1, 2], "repeat": 0},{ "annotations": "", "defaultValue": 1.5, "dtype": "float", "ftype": "continuous", "name": "EC.ws", "range": [1, 2], "repeat": 0},{ "annotations": "", "defaultValue": 250, "dtype": "float", "ftype": "continuous", "name": "EC.wd", "range": [240, 300], "repeat": 0},{ "annotations": "", "defaultValue": 1, "dtype": "float", "ftype": "continuous", "name": "EC.rho", "range": [1, 2], "repeat": 0},{ "annotations": "", "defaultValue": 850, "dtype": "float", "ftype": "continuous", "name": "EC.pres", "range": [820, 900], "repeat": 0},{ "annotations": "", "defaultValue": 20, "dtype": "float", ftype": "continuous", "name": "EC.tmp", "range": [18, 30], "repeat": 0},{ "annotations": "", "defaultValue": 1, "dtype": "float", "ftype": "continuous", "name": "GFS.nwp_time", range": [1, 2], "repeat": 0},{ "annotations": "", "defaultValue": 20, "dtype": "int", "ftype": "continuous", "name": "GFS.dist", "range": [12, 100], "repeat": 0},{ "annotations": "", "defaultValue": 1, "dtype": "float", "ftype": "continuous", "name": "GFS.ws", range": [1, 2], "repeat": 0 },{ "annotations": "", "defaultValue": 50, "dtype": "float", "ftype": "continuous", "name": "GFS.wd", "range": [40, 300], "repeat": 0 },{ "annotations": "", "defaultValue": 1, "dtype": "float", "ftype": "continuous", "name": "GFS.rho", "range": [1, 2], "repeat": 0},{ "annotations": "", "defaultValue": 850, "dtype": "float", "ftype": "continuous", "name": "GFS.pres", "range": [840, 900], "repeat": 0},{ "annotations": "", "defaultValue": 19, "dtype": "float", "ftype": "continuous", "name": "GFS.tmp", "range": [18, 20], "repeat": 0} ]
为 output_format 参数输入以下代码:
[ { "annotations": "", "defaultValue": 0, "dtype": "float", "ftype": "continuous", "name": "power", "range": [], "repeat": 0}]
interface:选择
REST。error_on_exit:选择
false。
通过以下步骤添加 Mlflow Model Version Register 算子:
从算子列表中拖拽一个 Mlflow Model Version Register 算子到 Loop For Model Training 子画布中。
连接 Create a model 算子和 Model Training 算子的输出锚点与该 Mlflow Model Version Register 算子的输入锚点。
选择此 Mlflow Model Version Register 算子,配置以下信息:
名称:输入
Create a Model Revision。为 input data 参数输入以下代码:
{ "data": { "names": [ "i.set", "X_basic.forecast_time", "X_basic.horizon", "X-basic.time", "X-basic.hour", "EC.nwp_time", "EC.dist", "EC.ws", "EC.wd", "EC.rho", "EC.pres", "EC.tmp", "GFS.nwp_time", "GFS.dist", "GFS.ws", "GFS.wd", "GFS.rho", "GFS.pres", "GFS.tmp"], "ndarray": [ [ 300, 300, 300, 8, 10, 10, 1.5, 1.5, 250, 1, 850, 20, 1, 20, 1, 50, 1, 850, 19] ]} }
version_rule: 选择
time。architecture: 选择
X86。coprocessor: 选择
None。framework:选择
sklearn。language: 选择
python3。model_reference:引用
Create a Model.model_name_output。publisher:选择
system。minio_paths:引用
Generate Target List.mlflow_model_file_paths。enforce_register: 选择
true,确保在未能通过模型测试时也能正常注册模型版本。serve_as_file:选择
true,算子将保存模型文件,用于模型文件预测任务。
通过以下步骤添加 Model Instance 算子:
从算子列表中拖拽一个 Model Instance 算子到 Loop For Model Training 子画布中。
连接 Create a model 算子的输出锚点与该 Model Instance 算子的输入锚点。
选择此 Model Instance 算子,配置以下信息:
名称:输入
Create a Model Instance。name:引用
modelinstancename。resource_pool:引用
resourcepool。model_name:引用
Create a Model.model_name_output。deploy_mode:选择
ONLINE。
通过以下步骤添加 Model Test 算子:
从算子列表中拖拽一个 Model Test 算子到 Loop For Model Training 子画布中。
连接 Create a Model Revision 算子的输出锚点与该 Model Test 算子的输入锚点。
选择此 Model Test 算子,配置以下信息:
名称:输入
Create a Model Test。为 input_dat 参数输入以下代码:
{ "data": { "names": [ "i.set", "X_basic.forecast_time", "X_basic.horizon", "X-basic.time", "X-basic.hour", "EC.nwp_time", "EC.dist", "EC.ws", "EC.wd", "EC.rho", "EC.pres", "EC.tmp", "GFS.nwp_time", "GFS.dist", "GFS.ws", "GFS.wd", "GFS.rho", "GFS.pres", "GFS.tmp"], "ndarray": [ [ 300, 300, 300, 8, 10, 10, 1.5, 1.5, 250, 1, 850, 20, 1, 20, 1, 50, 1, 850, 19 ] ]} }
model_builder: 引用
Create a Model Revision.model_builder_name。test_timeout: 输入
300。
通过以下步骤添加 Single Model Deployment 算子:
从算子列表中拖拽一个 Single Model Deployment 算子到 Loop For Model Training 子画布中。
连接 Create a Model Instance 算子、Create a Model Revision 算子和 Create a Model Test 算子的输出锚点与该 Single Model Deployment 算子的输入锚点。
选择此 Single Model Deployment 算子,配置以下信息:
名称:输入
Deploy the Model Revision。model_revision:引用
Create a Model Revision.model_revision_name。instance_name:引用
Create a Model Instance.instance_name_output。request_cpu:输入
0.5。request_memory:输入
0.5。limit_cpu:输入
0.8。limit_memory:输入
0.8。
选择顶部工具栏的保存图标
以保存配置信息。
配置完成的 Loop For Model Training 子画布如下所示:
配置预测任务¶
在主画布中,双击 Condition for Prediction 算子打开子画布。你需要在 Condition for Prediction 子画布中添加 2 个算子。
PythonEx 算子:生成用于模型预测任务的循环列表。
ParallelFor 算子:执行模型预测任务。
配置生成循环列表的 PythonEx 算子¶
通过以下步骤添加 PythonEx 算子:
从算子列表中拖拽一个 PythonEx 算子到 Condition for Prediction 子画布中。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Generate Target List for Prediction。workspace:选择
wind_power_forecasting。entrypoint:选择
generate_model_list.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
lenoflist|number|Reference|lenoflist。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
result_list|file。
选择顶部工具栏的保存图标
以保存配置信息。
配置并发执行模型预测任务的 ParallelFor 算子¶
通过以下步骤添加 ParallelFor 算子:
从算子列表中拖拽一个 ParallelFor 算子到 Condition for Prediction 子画布中。
连接 Generate Target List for Prediction 算子的输出锚点与该 ParallelFor 算子的输入锚点。
选择此 ParallelFor 算子,配置以下信息:
名称:输入
Loop For prediction。输入参数:配置为
引用|Generate Target List.result_list|item。
选择顶部工具栏的保存图标
以保存配置信息。
本教程包含以下两种模型预测任务类型:基于 Mlflow 模型文件的预测,以及基于已发布模型服务的预测。你需要在 Loop For prediction 子画布中添加 2 个 Condition 算子以执行不同类型的预测任务:
Condition 算子 1:当全局参数 predictiontype 的参数值为
service时,基于已发布模型服务执行模型预测任务。Condition 算子 2:当全局参数 predictiontype 的参数值为
file时,基于 Mlflow 模型文件执行模型预测任务。
配置执行模型服务预测的 Condition 算子¶
通过以下步骤添加 Condition 算子:
从算子列表中拖拽一个 Condition 算子到 Loop For prediction 子画布中。
选择此算子,配置以下信息:
名称: 输入
Condition for Service Prediction Type。表达式:配置为
引用|predictiontype|==|声明|service。
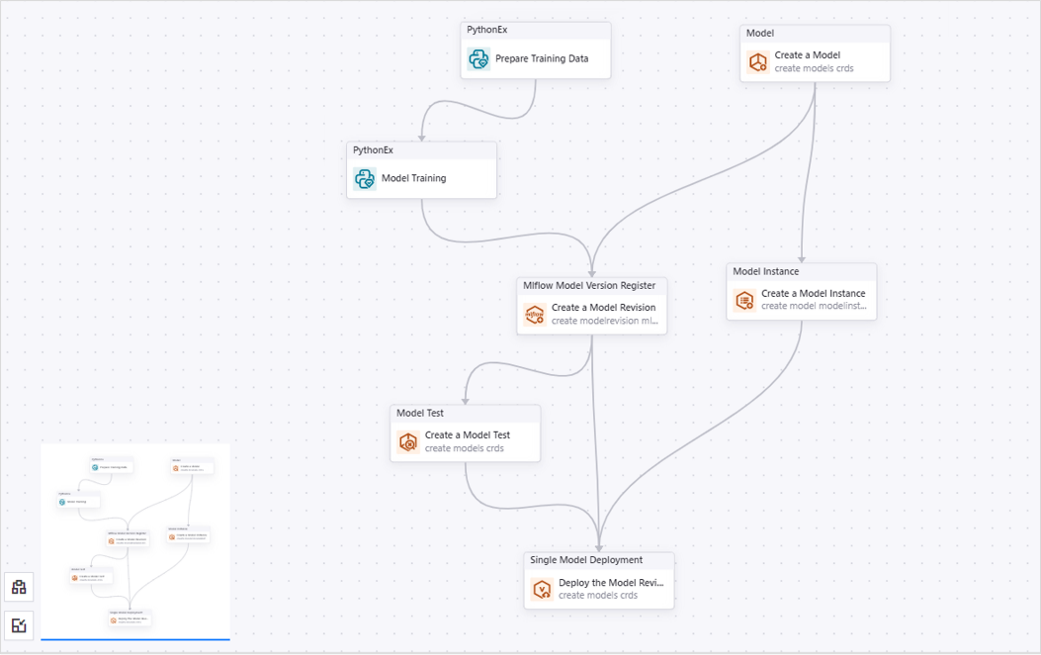
Condition for Service Prediction Type 算子执行模型服务预测,并导出预测结果文件。若当前 OU 下有可用 EnOS Hive 数据源,可将预测结果文件上传至 Hive 表格。你需要在 Condition for Service Prediction Type 子画布中添加 5 个算子:
PythonEx 算子 1:准备预测数据。
Service Prediction 算子:基于模型服务执行预测任务,并输出预测结果。
PythonEx 算子 2:将预测结果与真实数据写入文件。
PythonCode 算子:检查当前 OU 下是否有可用于存储预测结果文件的 EnOS Hive。
Condition 算子:在 EnOS Hive 可用时将结果文件存储至 EnOS Hive。
通过以下步骤添加 PythonEx 算子 1:
从算子列表中拖拽一个 PythonEx 算子到 Condition for Service Prediction Type 子画布中。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Prepare Prediction Data。workspace:选择
wind_power_forecasting。entrypoint:选择
prepare_predict_data.py。requirements: 选择
requirements1.txt。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
datasetname|string|Reference|dataset_name。选择 输入参数 > 添加参数 为算子添加另一输入参数,并配置为
ratio|number|Reference|sample_split_ratio。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
features|file。选择 输出参数 > 添加参数 为算子添加另一输出参数,并配置为
raw_data|file。
通过以下步骤添加 Service Prediction 算子:
从算子列表中拖拽一个 Service Prediction 算子到 Condition for Service Prediction Type 子画布中。
连接 Prepare Prediction Data 算子的输出锚点与该 Service Prediction 算子的输入锚点。
选择此 Service Prediction 算子,配置以下信息:
名称:输入
Predict from Service。model:引用
item1。instance:引用
modelinstancename。namespace:引用
resourcepool。datatype:选择
csv。data:引用
Prepare Prediction Data.features。
通过以下步骤添加 PythonEx 算子 2:
从算子列表中拖拽一个 PythonEx 算子到 Condition for Service Prediction Type 子画布中。
连接 Prepare Prediction Data 算子和 Prediction from Service 算子的输出锚点与该 PythonEx 算子的输入锚点。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Write results。workspace:选择
wind_power_forecasting。entrypoint:选择
write_results.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
predicted_data|file|Reference|Predict from Service.predictions。选择 输入参数 > 添加参数 为算子添加另一输入参数,并配置为
actual_data|file|Reference|Prepare Prediction Data.raw_data。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
outputfile|file。
通过以下步骤添加 PythonCode 算子:
从算子列表中拖拽一个 PythonCode 算子到 Condition for Service Prediction Type 子画布中。
选择此 PythonCode 算子,配置以下信息:
名称:输入
Check Hive Config。workspace:选择
wind_power_forecasting。entrypoint:选择
check_hive_config.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
hive_source|hive_source|Reference|hive_source。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
export_to_hive|boolean。
通过以下步骤添加 Condition 算子:
从算子列表中拖拽一个 Condition 算子到 Condition for Service Prediction Type 子画布中。
连接 Write results 算子和 Check Hive Config 算子的输出锚点与该 Condition 算子的输入锚点。
选择此 Condition 算子,配置以下信息:
名称:输入
Export to Hive?。表达式: 配置为
引用|Check Hive Config.export_to_hive|==|声明|ture。
Export to Hive? 算子将上传模型服务预测结果上传至 EnOS Hive。 你需要在 Export to Hive? 子画布中添加 3 个算子:
PythonEx 算子:生成 HDFS 目录路径以及用于将文件上传至 EnOS Hive 的 SQL 语句。
HDFS Uploader 算子:将预测结果文件上传至 HDFS 目录。
Hive 算子:将预测结果储存至 EnOS Hive。
通过以下步骤添加 PythonEx 算子:
从算子列表中拖拽一个 PythonEx 算子到 Export to Hive? 子画布中。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Generate variables。workspace:选择
wind_power_forecasting。entrypoint:选择
generate_variables.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
ouid|string|Reference|ouid。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
sql_statements|list。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
hdfs_dest|string。
通过以下步骤添加 HDFS Uploader 算子:
从算子列表中拖拽一个 HDFS Uploader 算子到 Export to Hive? 子画布中。
连接 Generate variables 算子的输出锚点与该 HDFS Uploader 算子的输入锚点。
选择此 HDFS Uploader 算子,配置以下信息:
名称:输入
HDFS Uploader。data_source: 引用
hdfs_source。file:引用
Write results.outputfile。filename:引用
item1。dest:引用
Generate variables.hdfs_dest。overwrite:选择
ture。
通过以下步骤添加 Hive 算子:
从算子列表中拖拽一个 Hive 算子到 Export to Hive? 子画布中。
连接 Generate variables 算子和 HDFS Uploader 算子的输出锚点与该 Hive 算子的输入锚点。
选择此 Hive 算子,配置以下信息:
名称:输入
Hive。data_source: 引用
hive_source。sqls:引用
Generate variables.sql_statements。
选择顶部工具栏的保存图标
以保存配置信息。
配置完成的 Condition for Service Prediction 子画布如下所示:
配置执行模型文件预测的 Condition 算子¶
通过以下步骤添加 Condition 算子:
从算子列表中拖拽一个 Condition 算子到 Loop For prediction 子画布中。
选择此算子,配置以下信息:
名称: 输入
Condition for Model File Prediction。表达式:配置为
引用|predictiontype|==|声明|file。
Condition for Model File Prediction 算子执行 Mlflow 模型文件预测,并导出预测结果文件。若当前 OU 下有可用 EnOS Hive,可将预测结果文件上传至 Hive 表格。你需要在 Condition for Model File Prediction 子画布中添加 6 个算子:
PythonEx 算子 1:获取最新模型版本。
PythonEx 算子 2:准备预测数据。
Service Prediction 算子:基于模型服务执行预测任务,并输出预测结果。
PythonEx 算子 3:将预测结果与真实数据写入文件。
PythonEx 算子 4:检查当前OU下是否有可用于存储预测结果文件的 EnOS Hive。
Condition 算子:在 EnOS Hive 可用时将结果文件存储至 EnOS Hive。
通过以下步骤添加 PythonEx 算子 1:
从算子列表中拖拽一个 PythonEx 算子到 Condition for Model File Prediction 子画布中。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Get Latest Model Version。workspace:选择
wind_power_forecasting。entrypoint:选择
get_latest_model_version.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
model_name|model_name|Reference|item1。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
latest_version|model_version。
通过以下步骤添加 PythonEx 算子 2:
从算子列表中拖拽一个 PythonEx 算子到 Condition for Model File Prediction 子画布中。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Prepare Prediction Data 2。workspace:选择
wind_power_forecasting。entrypoint:选择
prepare_predict_data.py。requirements: 选择
requirements1.txt。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
datasetname|string|Reference|prediction_dataset_name。选择 输入参数 > 添加参数 为算子添加另一输入参数,并配置为
ratio|number|Reference|sample_split_ratio。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
features|file。选择 输出参数 > 添加参数 为算子添加另一输出参数,并配置为
raw_data|file。
通过以下步骤添加 Mlflow Model Version Prediction 算子:
从算子列表中拖拽一个 Mlflow Model Version Prediction 算子到 Condition for Model File Prediction 子画布中。
连接 Prepare Prediction Data 2 算子和 Get Latest Model Version 算子的输出锚点与该 Mlflow Model Version Prediction 算子的输入锚点。
选择此 Mlflow Model Version Prediction 算子,配置以下信息:
名称:输入
Predict from Mlflow Model File。model_name:引用
item1。model_version:引用
Get Latest Model Version.latest_version。data:引用
Prepare Prediction Data 2.features。data_type:选择
csv。
通过以下步骤添加 PythonEx 算子 3:
从算子列表中拖拽一个 PythonEx 算子到 Condition for Model File Prediction 子画布中。
连接 Prepare Prediction Data 2 算子和 Predict from Mlflow Model File 算子的输出锚点与该 PythonEx 算子的输入锚点。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Write results 2。workspace:选择
wind_power_forecasting。entrypoint:选择
write_results.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
predicted_data|file|Reference|Predict from Mlflow Model File.predictions。选择 输入参数 > 添加参数 为算子添加另一输入参数,并配置为
actual_data|file|Reference|Prepare Prediction Data 2.raw_data。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
outputfile|file。
通过以下步骤添加 PythonCode 算子:
从算子列表中拖拽一个 PythonCode 算子到 Condition for Model File Prediction 子画布中。
选择此 PythonCode 算子,配置以下信息:
名称:输入
Check Hive Config 2。workspace:选择
wind_power_forecasting。entrypoint:选择
check_hive_config.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
hive_source|hive_source|Reference|hive_source。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
export_to_hive|boolean。
通过以下步骤添加 Condition 算子:
从算子列表中拖拽一个 Condition 算子到 Condition for Model File Prediction 子画布中。
连接 Write results 2 算子和 Check Hive Config 2 算子的输出锚点与该 Condition 算子的输入锚点。
选择此 Condition 算子,配置以下信息:
名称:输入
Export to Hive 2?。表达式: 配置为
引用|Check Hive Config 2.export_to_hive|==|声明|ture。
Export to Hive 2? 算子将上传 Mlflow 模型文件预测结果上传至 EnOS Hive。 你需要在 Export to Hive 2? 子画布中添加 3 个算子:
PythonEx 算子:生成 HDFS 目录路径以及用于将文件上传至 EnOS Hive 的 SQL 语句。
HDFS Uploader 算子:将预测结果文件上传至 HDFS 目录。
Hive 算子:将预测结果储存至 EnOS Hive。
通过以下步骤添加 PythonEx 算子:
从算子列表中拖拽一个 PythonEx 算子到 Export to Hive 2? 子画布中。
选择此 PythonEx 算子,配置以下信息:
名称:输入
Generate variables 2。workspace:选择
wind_power_forecasting。entrypoint:选择
generate_variables.py。选择 输入参数 > 添加参数 为算子添加一个输入参数,并配置为
ouid|string|Reference|ouid。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
sql_statements|list。选择 输出参数 > 添加参数 为算子添加一个输出参数,并配置为
hdfs_dest|string。
通过以下步骤添加 Hive 算子:
从算子列表中拖拽一个 Hive 算子到 Export to Hive? 子画布中。
连接 Generate variables 算子的输出锚点与该 Hive 算子的输入锚点。
选择此 Hive 算子,配置以下信息:
名称:输入
Hive 2。data_source: 引用
hive_source。sqls:引用
Generate variables 2.sql_statements。
通过以下步骤添加 HDFS Uploader 算子:
从算子列表中拖拽一个 HDFS Uploader 算子到 Export to Hive 2? 子画布中。
连接 Generate variables 2 算子和 Hive2 算子的输出锚点与该 HDFS Uploader 算子的输入锚点。
选择此 HDFS Uploader 算子,配置以下信息:
名称:输入
HDFS Uploader 2。data_source: 引用
hdfs_source。file:引用
Write results 2.outputfile。filename:引用
item1。dest:引用
Generate variables 2.hdfs_dest。overwrite:选择
ture。
选择顶部工具栏的保存图标
以保存配置信息。
配置完成的 Condition for Model File Prediction 子画布如下所示: