Supported Interpreters¶
%hive¶
By default, the Hive interpreter uses the default queue resource for data query and processing, which might lead to uncontrollable job running and unmanageable data processing resource. If you need to run data query and processing jobs with high resource consumption, you need to request Batch Data Processing resource and configure the interpreter with the requested queue name with the following steps.
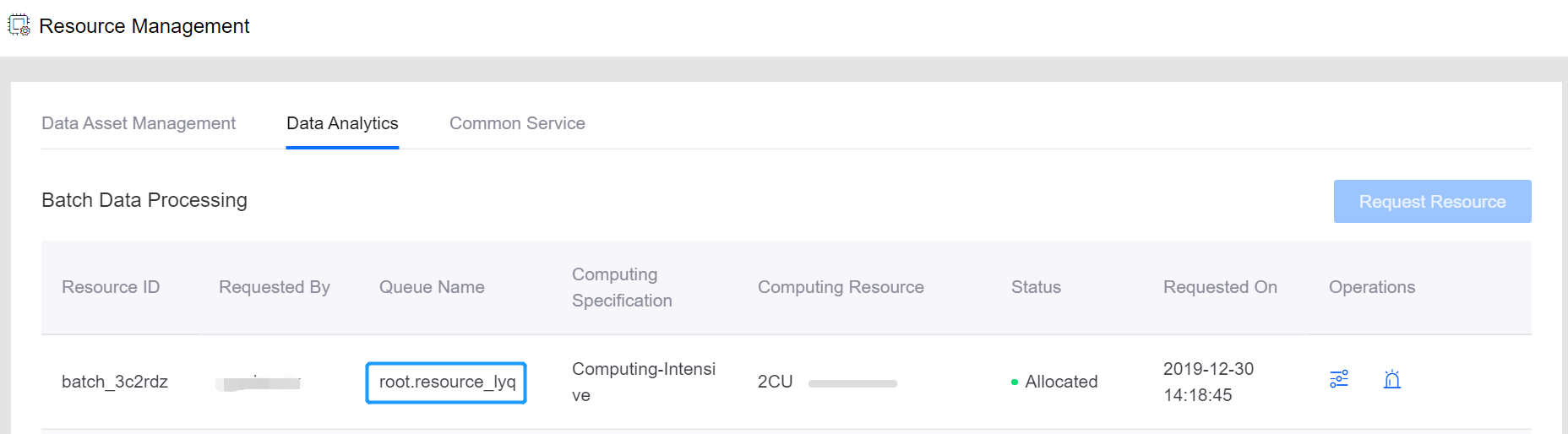
Log in to the EnOS Management Console, go to Resource Management > Enterprise Data Platform (or use the link on the Zeppelin notebook page), and request the Batch Processing - Queue resource.
When the requested resource is allocated, find the name of the queue resource in the Queue Name column of the resource table.
Open your Zeppelin notebook and run the following code:
%hive set mapreduce.job.queue.name={queue_name}
Check the running result.

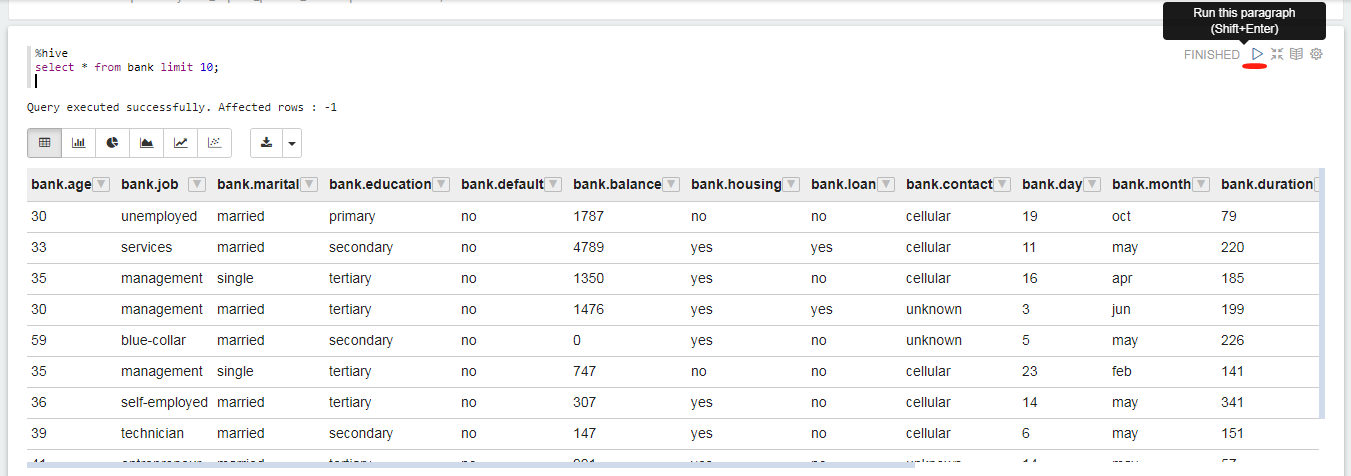
The following example shows how to use SQL to query a table of raw data.
%hive
select * from bank limit 10;
Click  to run the paragraph of code, and you’ll get results similar to what’s shown as follows.
to run the paragraph of code, and you’ll get results similar to what’s shown as follows.
%md¶
The following example shows a markdown sample:
%md
# hello world
- **hello world**

%python¶
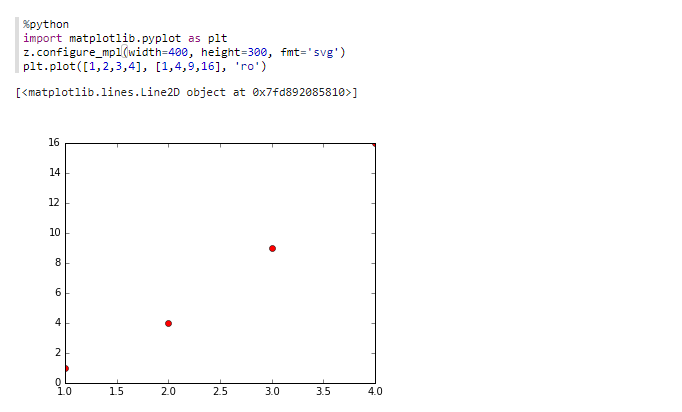
The following example shows the foundational operation of python, that is to mark two coordinate points.
%python
import matplotlib.pyplot as plt
z.configure_mpl(width=400, height=300, fmt='svg')
plt.plot([1,2,3,4], [1,4,9,16], 'ro')
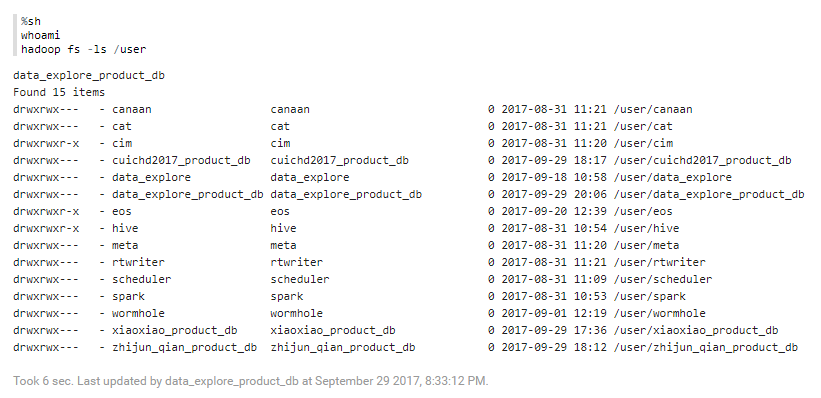
%sh¶
The following example shows the foundational operation of shell.
%sh
whoami
hadoop fs -ls /user