Resource Preparation¶
Batch Processing - Container Resource¶
Before using the features of the Batch Data Processing service (such as Python and Shell type tasks for batch data analysis), you need to request for the Batch Processing - Container resource on the EnOS Management Console. The Batch Data Processing - Container resource provides the following types:
Design Mode: Used by the Batch Data Processing - Script Development feature, for running and debugging scripts.
Running Mode: Used by the Data Synchronization and Batch Data Processing features, for running manual and periodic workflows (such as Python and Shell type tasks) for batch data analysis.
Requesting for the Container Resource¶
Log in to the EnOS Management Console with OU administrator account and click Resource Management from the left navigation panel.
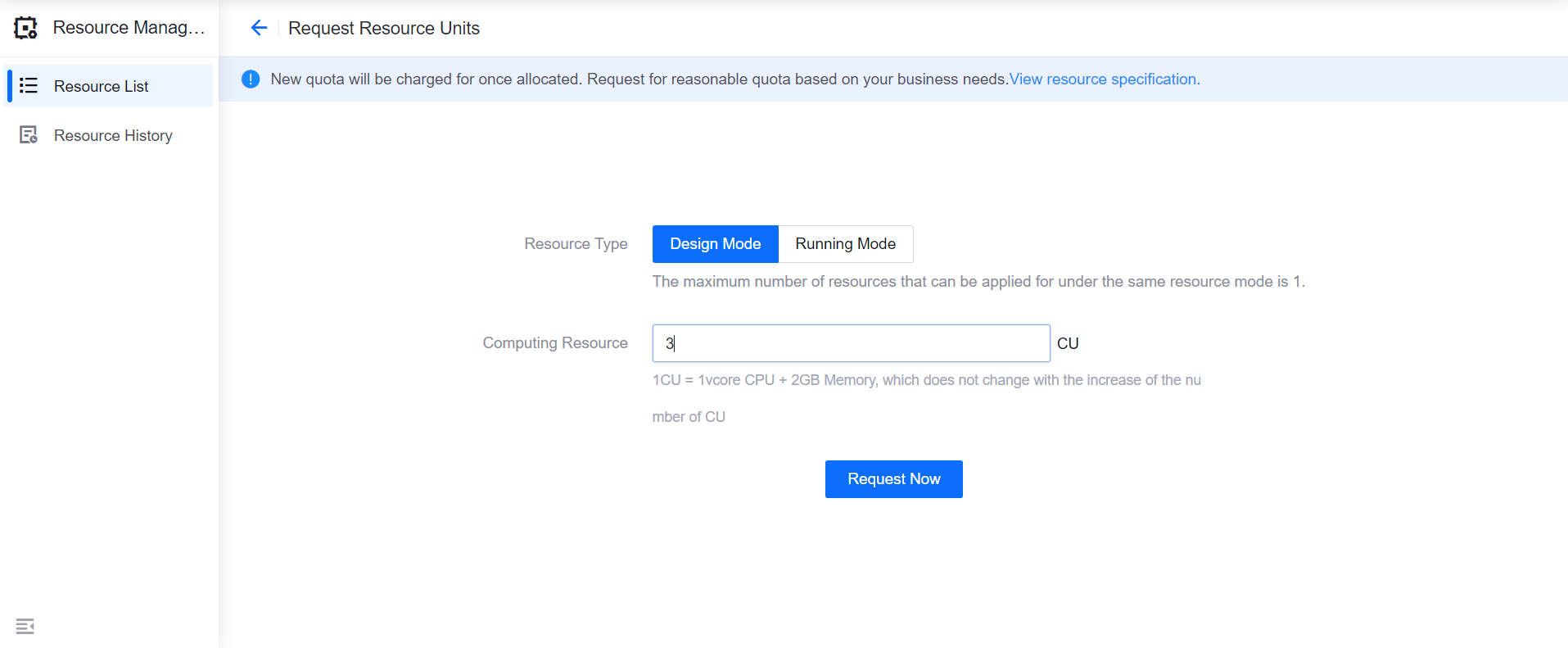
Under the Enterprise Data Platform tab, click the Request Resource button for the Batch Processing - Container resource.
Select a resource type and the needed resource specification (supporting 1~100 CU) and click the Request Now button.
After the container resource request is approved, the status of the requested resource will be Allocated, and the runtime status of the Design Mode resource will be Running. You can then start running your batch data processing tasks with the requested resources.
Deleting the Container Resource¶
If you do not need to run batch data processing tasks, you can stop all your tasks and then delete the requested container resource on the Resource Management page of EnOS Management Console to save costs.

Note
Before deleting the Design Mode resource, you need to click Stop icon first.
Batch Processing - Queue Resource¶
Before using features of the Batch Data Processing service in the following scenarios, you need to request for the Batch Processing - Queue resource on the EnOS Management Console.
Using HiveSQL or submitting Hadoop yarn jobs in Python or Shell task nodes of batch processing workflows.
Using data synchronization task nodes in batch processing workflows for synchronizing structured data, and the data source or target of the synchronization task is HIVE.
The Batch Processing - Queue resource provides the following computing specifications:
Computing-Intensive: If the jobs require higher CPU usage, choose the Computing-Intensive specification.
Memory-Intensive: If the jobs require higher memory usage, choose the Memory-Intensive specification.
For more information about the scenarios that require the Batch Processing - Queue resource, see Batch Processing - Queue Resource Usage.
Requesting for or Deleting the Queue Resource¶
The steps about requesting for or deleting the Batch Processing - Queue resource is similar with that of the Batch Processing - Container resource.