大数据队列资源使用说明¶
在以下场景中使用批数据处理服务时,需要通过 资源管理 页面申请 批数据处理 - 大数据队列 资源。
在批数据处理任务流中使用 Python 或 Shell 任务节点,且使用到 HiveSQL 或需要提交 Hadoop yarn 任务时。
批数据处理任务流里使用到数据同步任务节点,同步的数据为结构化数据,且数据同步任务节点里配置的数据源或目标为 HIVE 时。
存量结构化数据同步任务或批数据处理任务流中有结构化数据同步任务节点时,如未指定大数据队列,系统会默认使用 default 队列,但不能保证资源的可用性。应更新数据同步任务或批数据处理任务流的配置,指定队列资源。
批数据处理任务流中有 Python 或 Shell 任务节点时,如未指定队列资源(可能是存量任务流或新开发的任务流),系统会默认使用 default 队列,但不能保证资源的可用性。应更新批数据处理任务流的配置,指定队列资源。
在 EnOS 2.2.0 版本中,如果没有在以上业务场景中指定队列资源,系统会使用大数据平台缺省的队列资源。缺省的队列资源为不同组织共用,可能由于缺省队列资源不足而运行报错,也可能由于缺省队列不存在而报错,无法保证任务运行的稳定性。请在升级 EnOS 2.3.0 版本之前,手动更新批数据处理任务流的配置,指定通过资源管理申请的队列资源。
申请 批数据处理 - 大数据队列 资源的方法,以及在批数据处理和数据同步功能中配置大数据队列的方法如下。
申请大数据队列资源¶
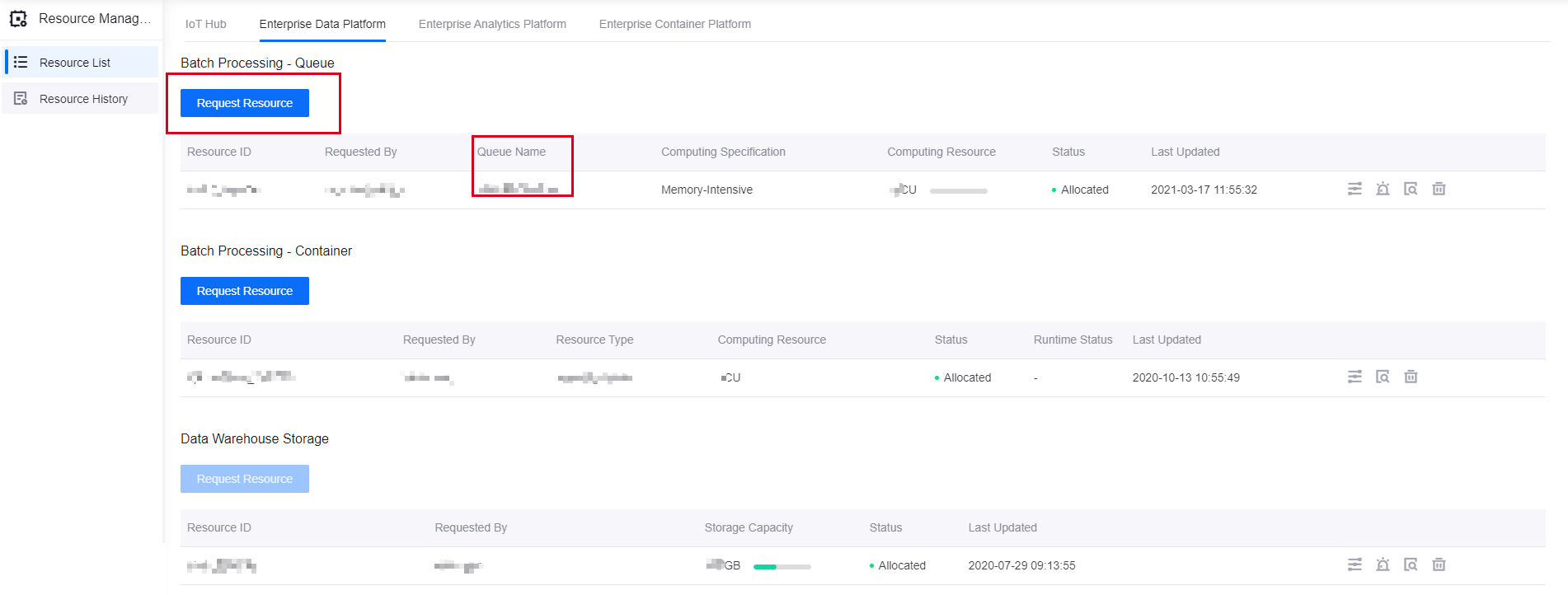
登录 EnOS 管理控制台,进入 资源管理 > 资源列表 页面,在 数据管理 分类下的 批数据处理-大数据队列 一栏中申请队列资源。如下图所示:
配置数据同步任务流¶
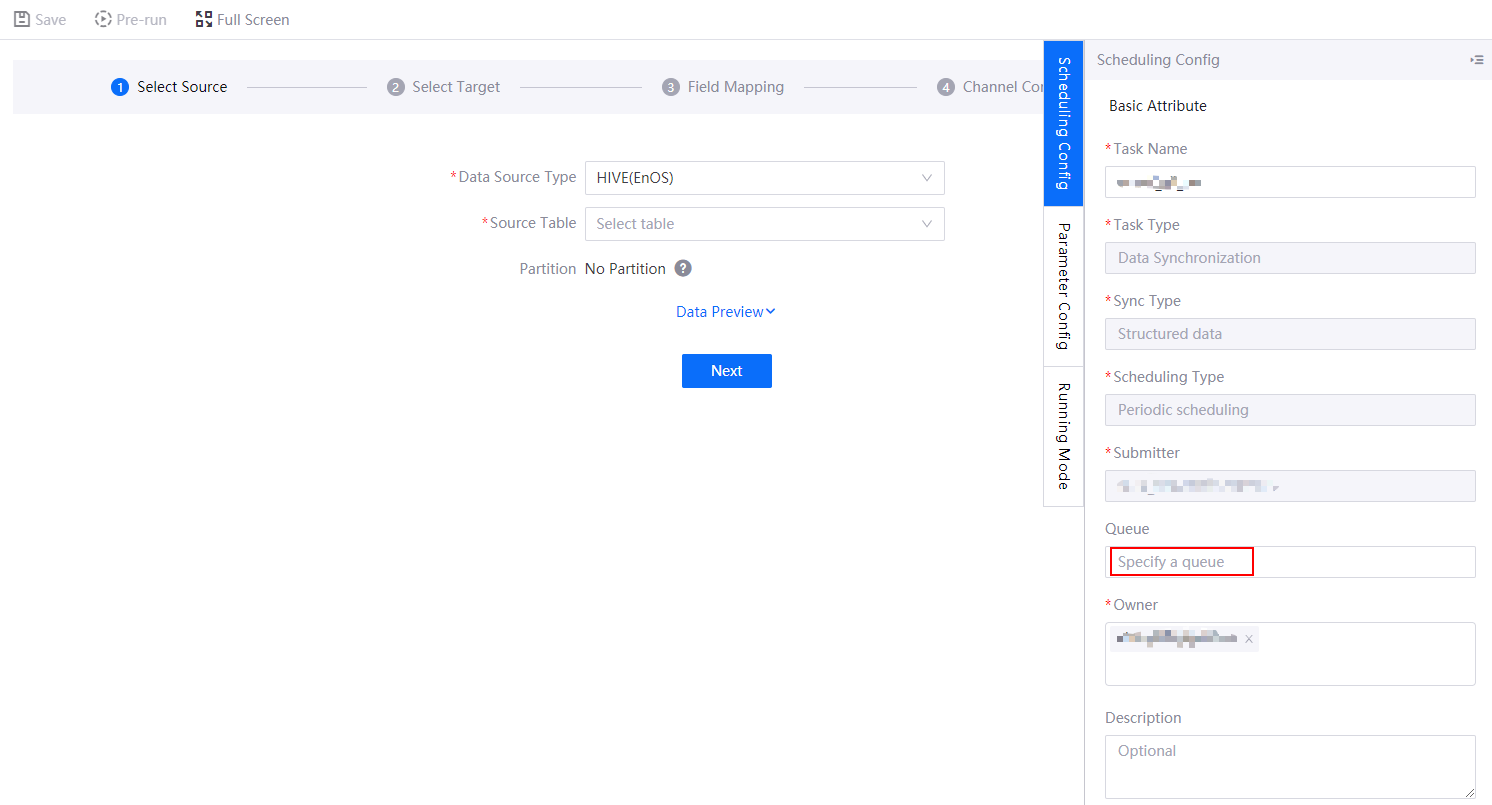
在数据同步任务的调度配置中,配置使用的队列资源。如下图所示:
配置批数据处理任务流¶
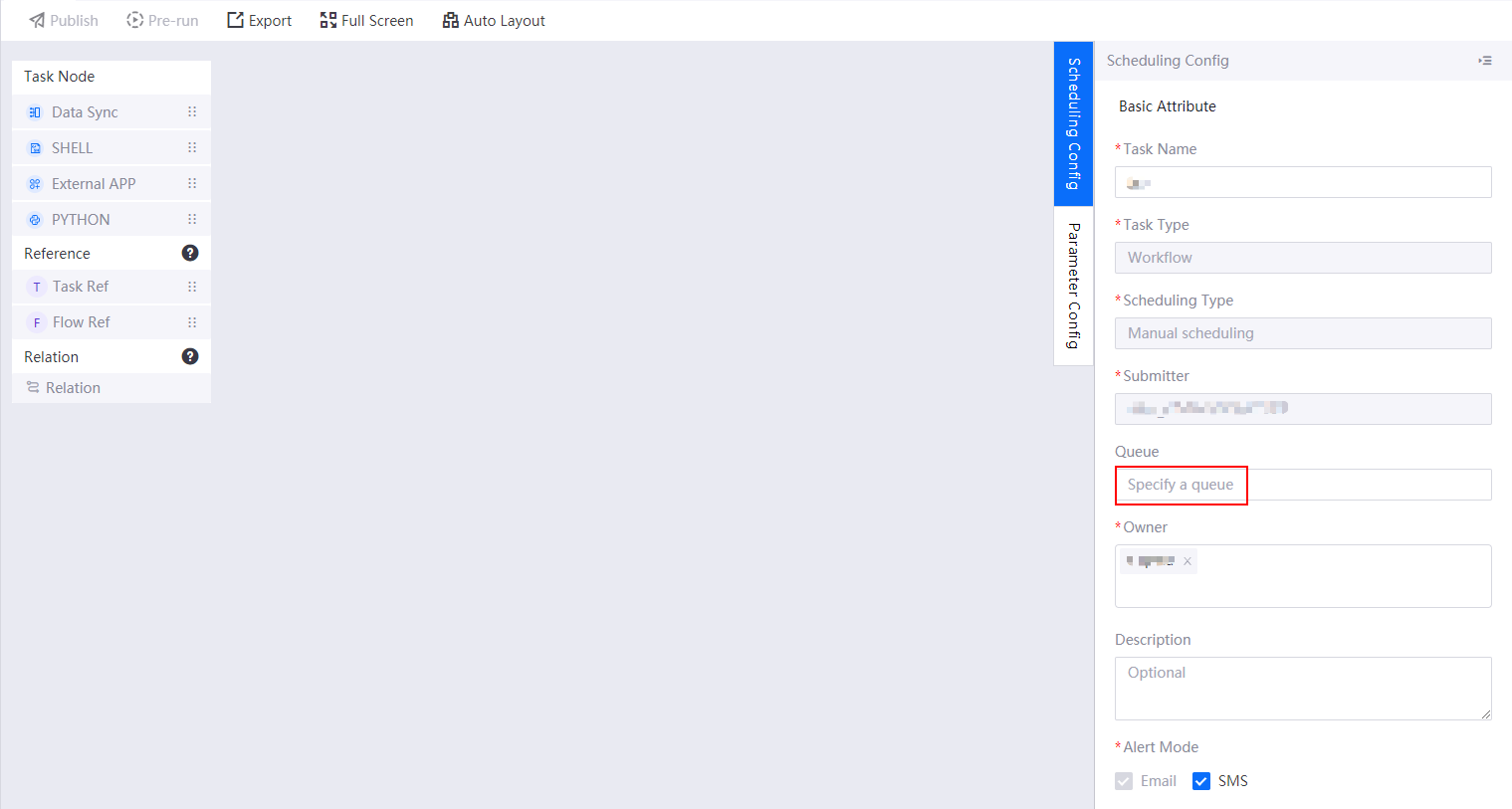
在批数据处理任务流中,为数据同步任务节点配置使用的队列资源。如下图所示:
Shell / Python 任务节点中使用队列资源¶
Shell 脚本队列设置参考¶
canaanhive -str "set mapred.job.queue.name=root.xxx;insert into tablename vaules() ......"
Python 代码中设置队列参考¶
hive.execute('''set mapreduce.job.queuename=root.xxx''')
rc= hive.execute('''create table t1 as select * from t2''')
rs=hive.executeQuery('''select * from t1''')
补充说明¶
在 EnOS 2.3.0中,当数据同步任务或数据同步任务节点配置中的数据源或目标使用 Hive 时,大数据队列配置将调整为必填项。同时取消原来在任务流调度配置中的队列设置。 在 EnOS 2.2.0 版本中,任务流的调度配置里已配置的大数据队列会在升级到 EnOS 2.3.0 时无缝迁移。 在升级到 EnOS 2.3.0 版本前未在任务流的调度配置里配置队列资源的任务流将无法完成自动迁移。
基于以上说明,总结如下:
已有数据同步任务流里数据源或目标使用 Hive、或批数据处理任务流中包含的数据同步任务节点的数据源或目标使用到 Hive 时,请在任务流的调度配置中使用通过资源管理页面申请的大数据队列资源。
数据同步任务流或批数据处理数据同步任务节点数据源和目标的配置中未使用 Hive 时,无须考虑队列资源配置。
批数据处理里通过 Shell 或 Python 任务节点运行 HiveSQL 时,请在 HiveSQL 中指定通过资源管理页面申请的大数据队列资源。
如有任何疑问,请及时反馈至 EnOS 产品团队。