Unit 3: Stream Processing¶
Pipeline 1: Converting the DCM Data Format to the Measurement Data Format¶
Creating a New Advanced Stream Processing Task¶
Note
Before creating a new advanced stream processing task, you need to ensure that your organization has applied for the EDP_INPUT_FORMAT and EDP_OUTPUT_FORMAT resources of Stream Processing - Message Queue Resource through the Resource Management service.
Log in to the EnOS Management Console and select Stream Processing > Pipeline Designer.
Click the Add Stream icon
 .
.In the Add Stream pop-up window, select the following:
Pipeline Type: tick
AdvancedMethod: tick
NewName: enter
tutorial_demo_1Operator Version: select
EDH Streaming Calculator Library 0.4.0
Designing Stream Processing Tasks¶
On the stream processing task design page, click Stage Library
 in the upper right corner of the page and find the operator you need to use from the drop-down menu. Click the data processing operator (such as Point Selector) to add it to the pipeline edit page.
in the upper right corner of the page and find the operator you need to use from the drop-down menu. Click the data processing operator (such as Point Selector) to add it to the pipeline edit page.Operators set by default are
EDH Kafka ConsumerandEDH Kafka Producer.In sequence, add the operators
Record Formatter,Data Viewer 1, andData Viewer 2.Note
The operators with an asterisk
 are unique operators in the 0.4.0 version of the operator library and support new data formats. If there are two operators available under the same name, tick the operator with an asterisk.
are unique operators in the 0.4.0 version of the operator library and support new data formats. If there are two operators available under the same name, tick the operator with an asterisk.Drag the stage and the connecting lines to arrange the new stage as shown below. Select the operators to add and set the operator parameters in the configuration options.
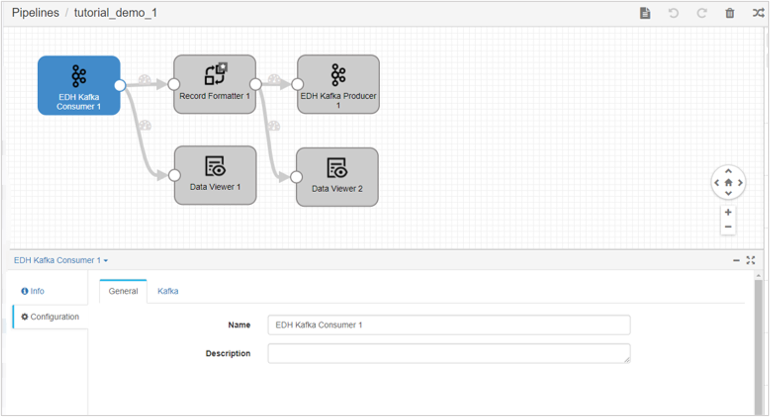
For the added operator, set the following parameters in configuration:
EDH Kafka Consumer: configure the operator and set the input topic.
Click the Configuration - Kafka tab:
Topic: select
MEASURE_POINT_ORIGIN_{OUID}Kafka Configuration:
auto.offset.reset: enter
earliestdefault.api.timeout.ms: default is
600000
Record Formatter: configure this operator to convert the DCM data format to the measurement data format.
Click the Configuration - Basic tab:
Input Format: select
DCM FormatOutput Format: select
EDP <MeasurementID> FormatAsset Tag Groups: enter
DcmModel(enter the tag group ID, which is used to associate corresponding device tags for the entered data)Measurement Tag Groups: enter
MyHaystack(enter the tag group ID you create, which is used to associate corresponding measurement tags for the entered data)
EDH Kafka Producer User: configure the operator and set the output topic.
Click the Configuration - Kafka tab:
Topic: select
EDP_INPUT_FORMAT_{OUID}Partition Expression: default is
${record:valueOrDefault("/assetId", record:value("/payload/assetId"))}Kafka Configuration:
retries: default is
2147483647max.in.flight.requests.per.connection: default is
1retry.backoff.ms: default is
100delivery.timeout.ms: default is
600000
Click Save at the top of the page to save the configuration information of the stream processing task.
After completing the operator configuration, click Validate
 in the upper right corner of the page to check whether the pipeline and operator parameter configurations are correct, and then modify the configuration according to the inspection results.
in the upper right corner of the page to check whether the pipeline and operator parameter configurations are correct, and then modify the configuration according to the inspection results.Click Publish at the top of the page to publish the stream processing task online.
Pipeline 2: Calculates the Average CO₂ Emissions Per Minute Above the First Floor of a Designated Building¶
Creating a New Advanced Stream processing Task¶
Log in to the EnOS Management Console and select Stream Processing > Stream Development.
Click the Add Stream icon
.In the Add Stream pop-up window, select the following:
Pipeline Type: tick
AdvancedMethod: tick
NewName: enter
tutorial_demo_2,Operator Version: select
EDH Streaming Calculator Library 0.4.0
Designing stream processing Tasks¶
On the stream processing task design page, click Stage Library
in the upper right corner of the page and find the operator you need to use from the drop-down menu. Click the data processing operator (such as Point Selector) to add it to the pipeline edit page.Operators set by default are
EDH Kafka ConsumerandEDH Kafka Producer.In sequence, add the operators
Record Filter,Off Limit Tagger,Fixed Time Window Aggregator,Data Viewer 1,Data Viewer 2,Data Viewer 3, andData Viewer 4.Note
The operators with an asterisk
are unique operators in the 0.4.0 version of the operator library and support new data formats. If there are two operators available under the same name, tick the operator with an asterisk.Drag the stage and the connecting lines to arrange the new stage as shown below. Select the operators to add and set the operator parameters in the configuration options.
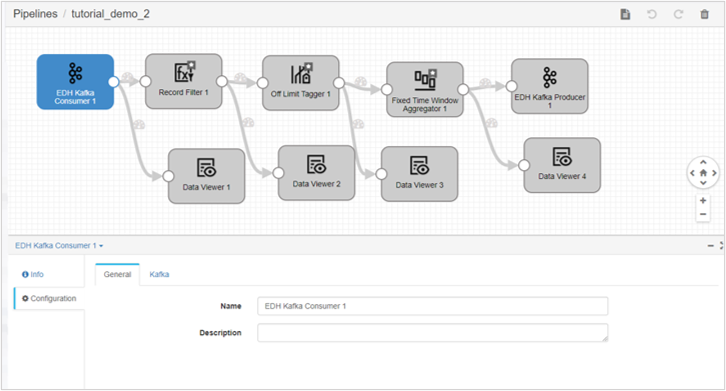
For the added operator, set the following parameters in configuration:
EDH Kafka Consumer: configure this operator, then select the last output topic of pipeline 1 as the input of pipeline 2.
Click the Configuration - Kafka tab:
Topic: select
EDP_INPUT_FORMAT_{OUID}Kafka Configuration:
auto.offset.reset: default is
latestdefault.api.timeout.ms: default is
600000
Record Filter: configure the operator to obtain the required data based on the tag.
Click the Configuration - Input/Output tab:
Filter Expression: enter:
seq.contains_key(record.assetTags.DcmModel, 'DcmModel:Test_SGBuilding') && #`record.measurementTags.MyHaystack.MyHaystack:zone.floor` > 1
Output Measurement ID: enter
Test_SGBuilding::ZoneCO2
Off Limit Tagger: Configure this operator to filter the data within the range of (0, 90), and output it as a temporary calculation point of Test_SGBuilding::ZoneCO2_a.
Click the Configuration - Input/Output tab:
Input Measurement: enter
Test_SGBuilding::ZoneCO2OpenClose: select
(x,y)Min-Max: enter
0,90.00Output Measurement: enter
Test_SGBuilding::ZoneCO2_a
Fixed Time Window Aggregator: Configure this operator to calculate the 1-minute average value and output it as a temporary calculation point for Test_SGBuilding::ZoneCO2_b.
Click Configuration - TriggerConfig tab:
Latency (Minute): select
0
Click the Configuration - Input/Output tab:
Input Measurement: enter
Test_SGBuilding::ZoneCO2_aFixed Window Size: enter
1Fixed Window Unit: select
minuteAggregator Policy: select
avgOutput Measurement: enter
Test_SGBuilding::ZoneCO2_b
Click Configuration - ExtraConfig tab:
Output Data Type: select
From Catalog Service
EDH Kafka Producer User: configure the operator and set the output topic.
Click the Configuration - Kafka tab:
Topic: select
EDP_OUTPUT_FORMAT_{OUID}Partition Expression: default is
${record:valueOrDefault("/assetId", record:value("/payload/assetId"))}Kafka Configuration:
retries: default is
2147483647max.in.flight.requests.per.connection: default is
1retry.backoff.ms: default is
100delivery.timeout.ms: default is
600000
Click Save at the top of the page to save the configuration information of the stream processing task.
After completing the operator configuration, click Validate
in the upper right corner of the page to check whether the pipeline and operator parameter configurations are correct, and then modify the configuration according to the inspection results.Click Publish at the top of the page to publish the stream processing task online.
Pipeline 3: Converts the Measurement Data Format Back to DCM Data Format and Outputs It¶
Creating a New Advanced Stream Processing Task¶
Log in to the EnOS Management Console and select Stream Processing > Stream Development.
Click the Add Stream icon
.In the Add Stream pop-up window, select the following:
Pipeline Type: tick
AdvancedMethod: tick
NewName: enter
tutorial_demo_3,Operator Version: select
EDH Streaming Calculator Library 0.4.0
Designing Stream Processing Tasks¶
On the stream processing task design page, click Stage Library
in the upper right corner of the page and find the operator you need to use from the drop-down menu. Click the data processing operator (such as Point Selector) to add it to the pipeline edit page.Operators set by default are
EDH Kafka ConsumerandEDH Kafka Producer.In sequence, add the operators
Asset Lookup,JavaScript 1,JavaScript 2,Point Lookup,Record Formatter,Data Viewer 1,Data Viewer 2,Data Viewer 3,Data Viewer 4,Data Viewer 5, andData Viewer 6.Note
The operators with an asterisk
are unique operators in the 0.4.0 version of the operator library and support new data formats. If there are two operators available under the same name, tick the operator with an asterisk.Drag the stage and the connecting lines to arrange the new stage as shown below. Select the operators to add and set the operator parameters in the configuration options.
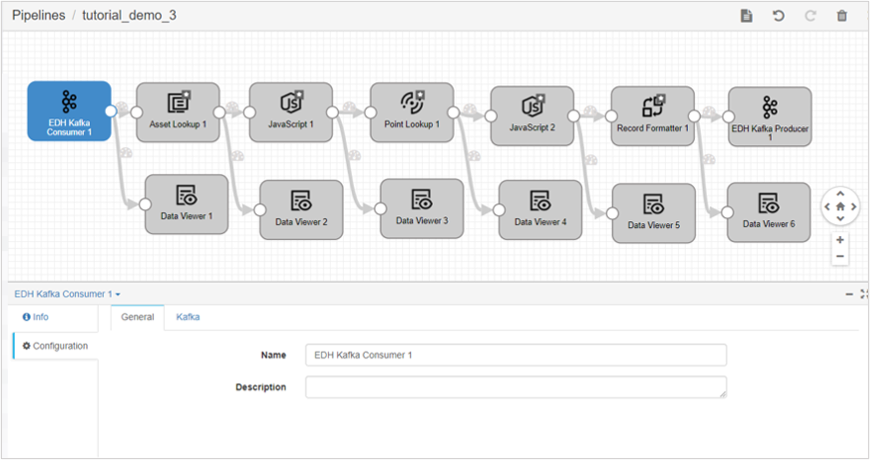
For the added operator, set the following parameters in configuration:
EDH Kafka Consumer: configure this operator, then select the last output topic of pipeline 2 as the input of pipeline 3.
Click the Configuration - Kafka tab:
Topic: select
EDP_OUTPUT_FORMAT_{OUID}Kafka Configuration:
auto.offset.reset: default is
latestdefault.api.timeout.ms: default is
600000
Asset Lookup: configure this operator to search for devices.
Click the Configuration - Input/Output tab:
Input Measurement: enter
Test_SGBuilding::ZoneCO2_cOutput Measurement: enter
Test_SGBuilding::ZoneCO2_d
Click Configuration - Criteria tab:
Attribute: select
AllTag: select
AllExtra: select
All
JavaScript 1: configure the operator and determine the modelId, modelIdPath and pointId.
Click the Configuration - Input/Output tab:
Input Measurement: enter
Test_SGBuilding::ZoneCO2_dOutput Measurement: enter
Test_SGBuilding::ZoneCO2_e
Click Configuration - JavaScript tab:
Script: enter:
for (var i = 0; i < records.length; i++){
try{
var record = records[i];
if(record.value['measurementId'] == 'Test_SGBuilding::ZoneCO2_d'){
//Fill in the query result
record.value['measurementId'] = 'Test_SGBuilding::ZoneCO2_e';
record.value['modelId'] = record.value['attr']['tslAssetLookup']['extra']['modelId'];
record.value['modelIdPath'] = record.value['attr']['tslAssetLookup']['extra']['modelIdPath'];
//Manually fill in
record.value['pointId'] = 'temp_avg';
}
output.write(record);
}catch(e){
// trace the exception
error.trace(e);
error.write(records[i], e);
}
}
Point Lookup: configure this operator to search for measurement points based on JavaScript
Click the Configuration - Input/Output tab:
Input Measurement: enter
Test_SGBuilding::ZoneCO2_eOutput Measurement: enter
Test_SGBuilding::ZoneCO2_f
Click Configuration - Criteria tab:
Tag: select
AllExtra: select
All
JavaScript 2: configure this operator to determine the quality level.
Click the Configuration - Input/Output tab:
Input Measurement: enter
Test_SGBuilding::ZoneCO2_fOutput Measurement: enter
Test_SGBuilding::ZoneCO2_g
Click Configuration - JavaScript tab:
Script: enter:
for (var i = 0; i < records.length; i++){
try{
var record = records[i];
if(record.value['measurementId'] == 'Test_SGBuilding::ZoneCO2_f'){
record.value['measurementId'] = 'Test_SGBuilding::ZoneCO2_g';
//Setting for quality indicator query. Support custom specification.
record.value['hasQuality'] = record.value['attr']['tslPointLookup']['extra']['hasQuality'];
}
output.write(record);
}catch(e){
// trace the exception
error.trace(e);
error.write(records[i], e);
}
}
Record Formatter: configure this operator to convert the measurement data format back to the DCM data format.
Click the Configuration - Basic tab:
Input Format: select
EDP <MeasurementID> FormatOutput Format: select
DCM Format
EDH Kafka Producer User: configure the operator and set the output topic.
Click the Configuration - Kafka tab:
Topic: select
MEASURE_POINT_CAL_{OUID}Partition Expression: default is
${record:valueOrDefault("/assetId", record:value("/payload/assetId"))}Kafka Configuration:
retries: default is
2147483647max.in.flight.requests.per.connection: default is
1retry.backoff.ms: default is
100delivery.timeout.ms: default is
600000
Click Save at the top of the page to save the configuration information of the stream processing task.
After completing the operator configuration, click Validate
in the upper right corner of the page to check whether the pipeline and operator parameter configurations are correct, and then modify the configuration according to the inspection results.Click Publish at the top of the page to publish the stream processing task online.
Click on the left navigation bar and select Stream OM, then click Start ![]() at the end of the three stream processing tasks shown above in sequence to start the stream processing task.
at the end of the three stream processing tasks shown above in sequence to start the stream processing task.
On the Stream OM page, you can view Stream Task Running Results.
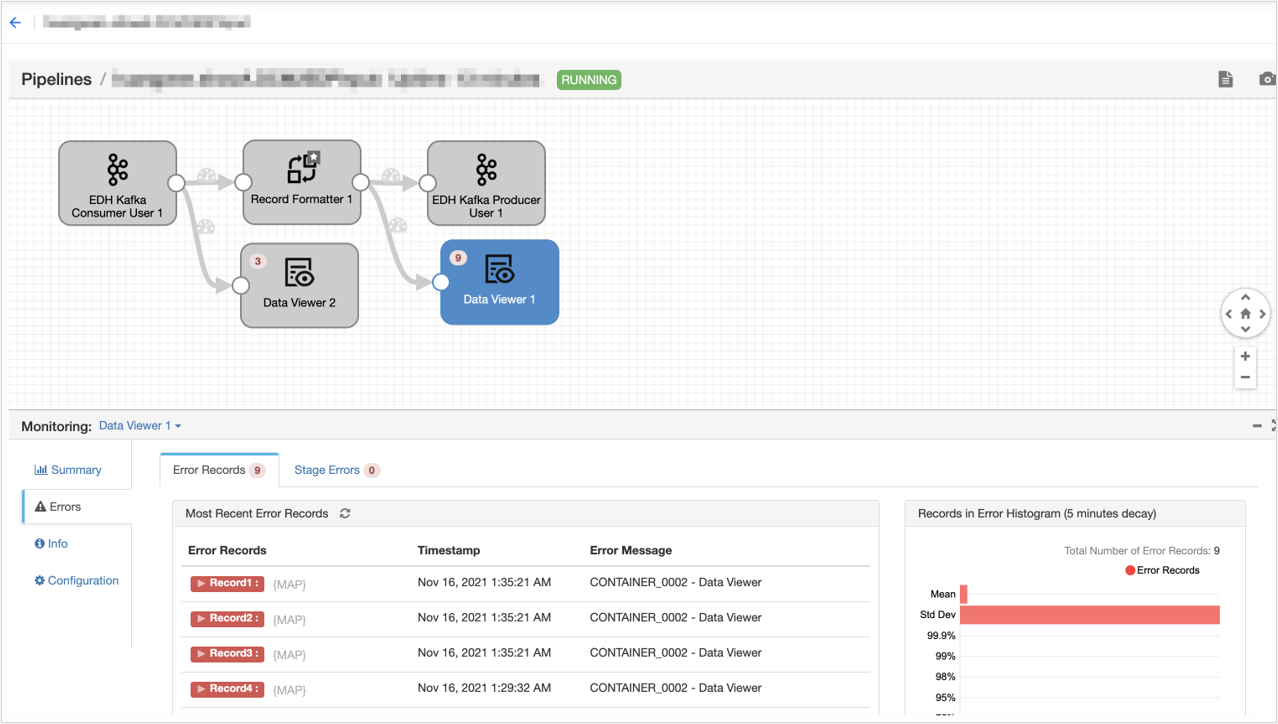
For more information about the operation of high-level flow data processing tasks, see Developing Advanced Pipelines.