SQL Statement Samples¶
The Federation Query product supports querying data from data sources by entering SQL statements. The SQL statements must comply with the ANSI/SQL2003 standard. Commonly used SQL statements are:
show schemas: View the schemas of all data sources that are defined by the data federation channels.describe {full_table_path}: Query the table structure (if the tables are not of csv format, it might not be able to display the structure).select {* / column_name} from {table_name} where {column_name} operator {value}: Query the rows and columns in a table.Note: For differnt channel types, the table name syntax is different. When the channel type is READ, for single source query, the table name syntax is
databaseName.tableName; for multiple source querey, the table name syntax isdataSourceName.databaseName.tableName. When the channel type is DOWNLOAD, the table name syntax isdatabaseName.tableName.
Usage Limit¶
Because the file system supports
varchartype by default, only COUNT, MAX, and MIN functions are supported. If you need to use other functions, you need to useCAST (xxxx AS type)to convert the data type.Some tables in Redis have fixed names, so you need to define alias names for the tables.
JOINmust have conditions.CROSS JOINis not supported.When using
BETWEEN ... AND, you also need to useCAST (xxxx AS type)to convert the data type.
SQL Statement Samples¶
The following table shows SQL statement samples for querying data from various data sources:
Data Source |
Table Structure |
Sample Configuration |
SQL Samples |
|---|---|---|---|
MySQL |
data_source.database.table |
|
|
Hive |
data_source.database.table |
|
|
Redis |
data_source.db.type |
|
|
HDFS |
data_source.folder0.folder1.file0 (The file sysytem is different from that of databases. The file structure is data source, folders, and files.) |
|
|
S3/Blob |
data_source.bucket.folder1.file0 (S3 and Blob are also file systems, but with buckets.) |
|
|
Kafka |
data_source.topic (Kafka is different from other data sources. It has data source and topics only.) |
|
|
Commonly Used select Example¶
select {* / column_name} from {table_name} where {column_name} operator {value}
select * from stock_information where stockid = str(nid)
stockname = 'str_name'
stockname like '% find this %'
or stockpath = 'stock_path'
or stocknumber < 1000
and stockindex = 24
not stock*** = 'man'
stocknumber between 20 and 100
stocknumber in(10,20,30)
order by stockid desc(asc)
order by 1,2
stockname = (select stockname from stock_information where stockid = 4)
select distinct column_name form table_name
select stocknumber , (stocknumber + 10)`stocknumber+10` from table_name
select stockname , (count(*)`count` from table_name group by stockname
having count(*) = 2
select *
from table1, table2
where table1.id = table2.id
select stockname from table1
union [all]
select stockname from table2
Commonly Used Functions¶
Statistical Functions¶
AVG
COUNT
MAX
MIN
SUM
STDEV()
STDEVP()
VAR()
VARP()
Arithmetic Functions¶
Trigonometric Functions
SIN(float_expression)
COS(float_expression)
TAN(float_expression)
COT(float_expression)
Functions for INTEGER/MONEY/REAL/FLOAT
EXP(float_expression)
LOG(float_expression)
LOG10(float_expression)
SQRT(float_expression)
Functions for Approximate Values
CEILING(numeric_expression)
FLOOR(numeric_expression)
ROUND(numeric_expression)
ABS(numeric_expression)
SIGN(numeric_expression)
PI()
RAND([integer_expression])
String Functions
ASCII()
CHAR()
LOWER()
UPPER()
STR()
Data Functions
DAY()
MONTH()
YEAR()
DATEADD(
, , )
HDFS Query Rules¶
Before querying data in HDFS across organizations through a data federation channel, ensure that the corresponding HDFS access permissions have been added through the Data Asset Authorization page.
HDFS query does not support wildcards. If wildcards are used when authorizing data assets in HDFS paths, you need to type the complete HDFS path in the SQL statement. Otherwise, the SQL statement running will report errors.
Samples for Aggregating Data in TSDB¶
Taking the following data stored in TSDB as example, the samples below show how to query and aggregate data stored in TSDB through a data federation channel.
Devices: “hiGNjDBJ”, “9wmyXxKf”
Measurement points: “ai_point_1”,”ai_point_2”,”ai_point_3”,”ai_point_4”,”ai_point_5”
Data density: 1 data record per second
Query time range: “2020-11-01 00:00:00” to “2020-12-01 00:00:00” (86400 data records/point)
Federation channel type: READ - Multiple Sources
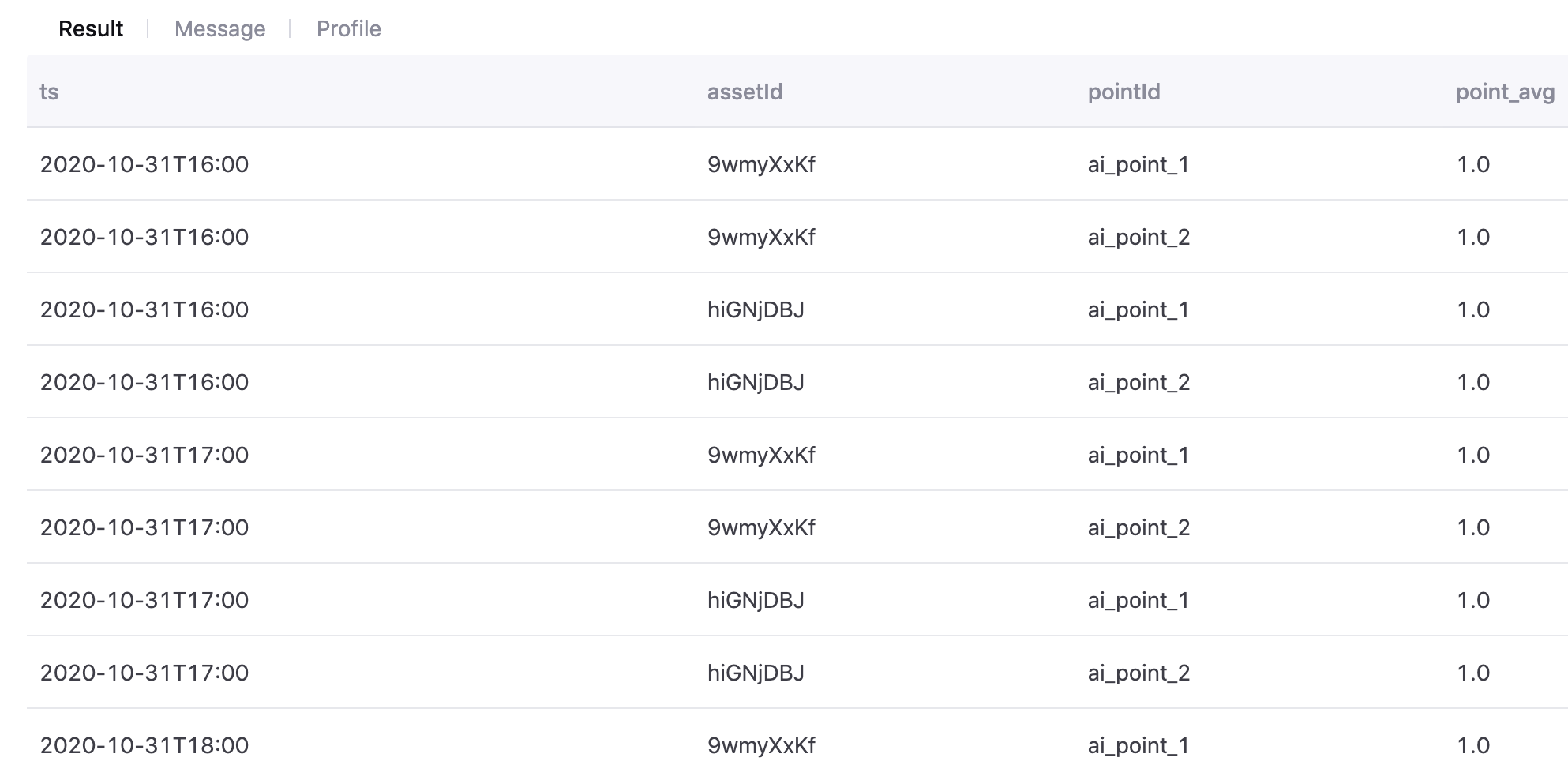
Multiple Devices and Multiple Points¶
Use the following SQL statement to aggregate data of multiple devices and multiple measurement points in 1 day and calculate the average value:
select cast((`timestamp`/3600000) * 3600000 as timestamp) as ts , assetId, pointId, avg(value) as point_avg from tsdb.o15504722874071.eniot where assetId in ('hiGNjDBJ', '9wmyXxKf') and pointId in('ai_point_1','ai_point_2')and local_time >= '2020-11-01 00:00:00' and local_time < '2020-11-02 00:00:00' GROUP BY (`timestamp`/3600000), assetId,pointId
The aggregation result is as follows:
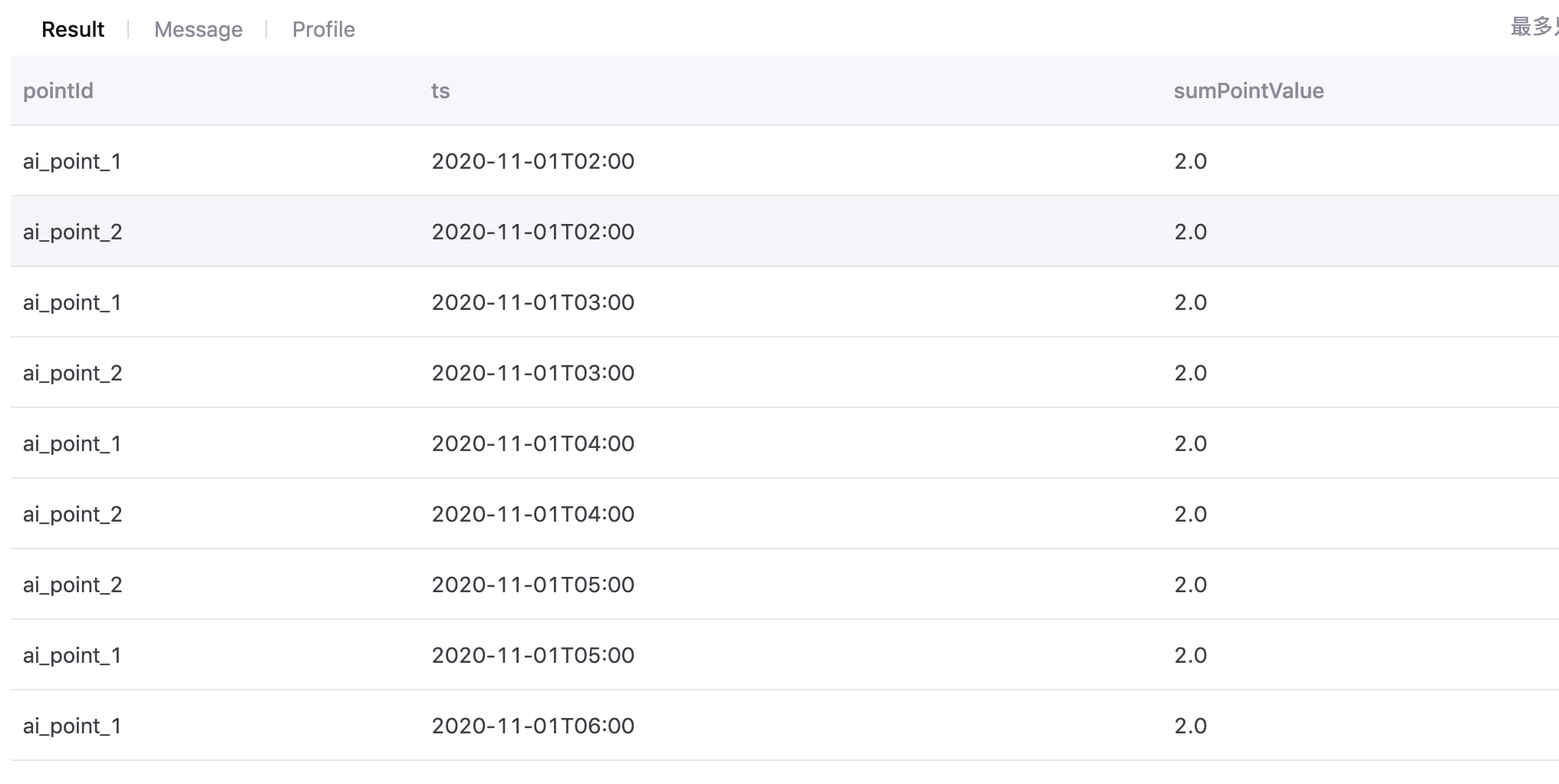
Multiple Devices and Single Point¶
Use the following SQL statement to aggregate data of a single measurement point of multiple devices on the section after aggregation:
point_x=sum(device.point_x)
with t as (select cast((`timestamp`/3600000) * 3600000 as timestamp) as ts , assetId, pointId, avg(value) as value from tsdb.o15504722874071.eniot where assetId in ('hiGNjDBJ', '9wmyXxKf') and pointId in('ai_point_1','ai_point_2')and local_time >= '2020-11-01 00:00:00' and local_time < '2020-11-02 00:00:00' GROUP BY (`timestamp`/3600000), assetId,pointId) select t.pointId,t.ts,sum(t.value) as sumPointValue from t where t.pointId in('ai_point_1','ai_point_2') group by t.ts, t.pointId ORDER BY ts
The aggregation result is as follows:
Single Device and Multiple Points¶
Use the following SQL statement to aggregate data of 2 measurement points of the same device:
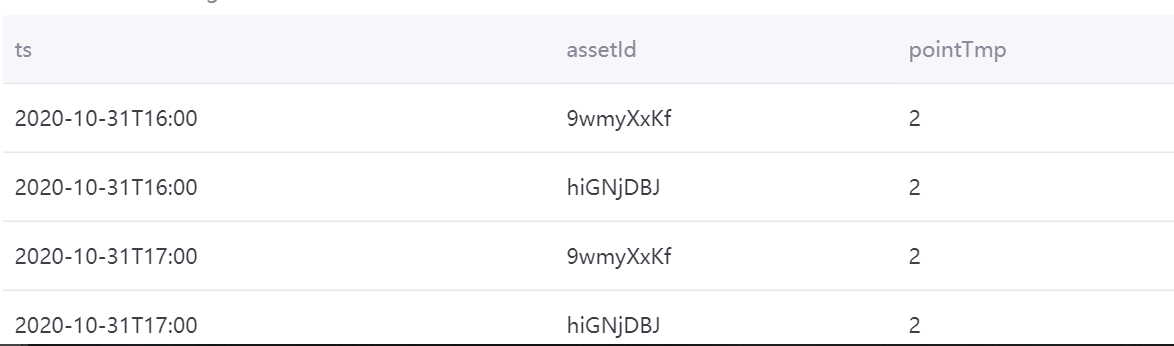
device.pointTmp=device.sum(ai_point_1+ai_point_2)
with t as (select cast((`timestamp`/3600000) * 3600000 as timestamp) as ts , assetId, pointId, avg(value) as value from tsdb.o15504722874071.eniot where assetId in ('hiGNjDBJ', '9wmyXxKf') and pointId in('ai_point_1','ai_point_2')and local_time >= '2020-11-01 00:00:00' and local_time < '2020-11-02 00:00:00' GROUP BY (`timestamp`/3600000), assetId,pointId) select t.ts, t.assetId, sum(CASE WHEN t.pointId in ('ai_point_1','ai_point_2') THEN 1 ELSE 0 END) as pointTmp from t group by t.ts,t.assetId
The aggregation result is as follows:
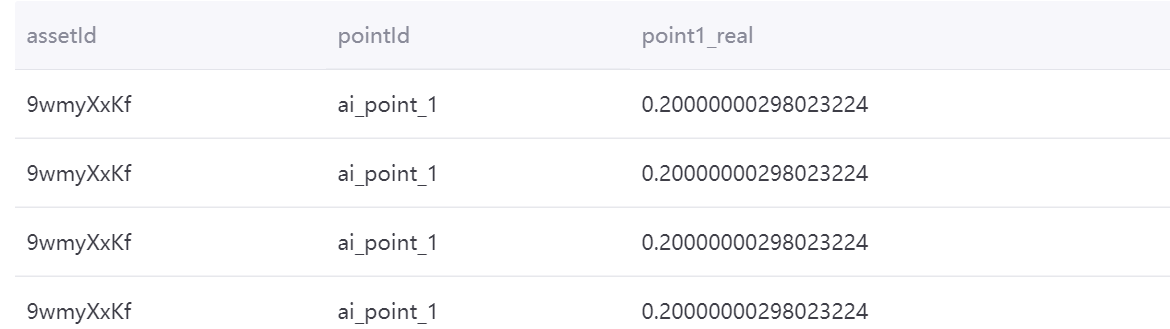
Aggregating Data with Dimension Tables in MySQL¶
Use the following SQL statement to aggregate data with dimension tables in MySQL:
point1_real= ai_point_1*ai_point_1_coefficient
with t as (select cast((`timestamp`/3600000) * 3600000 as timestamp) as ts , assetId, pointId, avg(value) as value from tsdb.o15504722874071.eniot where assetId in ('hiGNjDBJ', '9wmyXxKf') and pointId in('ai_point_1')and local_time >= '2020-11-01 00:00:00' and local_time < '2020-11-02 00:00:00' GROUP BY (`timestamp`/3600000), assetId,pointId) select t.assetId, t.pointId, t.value*m.ai_point_1_coefficient as point1_real from mysql196.test.device m join t on m.dev_id=t.assetId
The aggregation result is as follows: