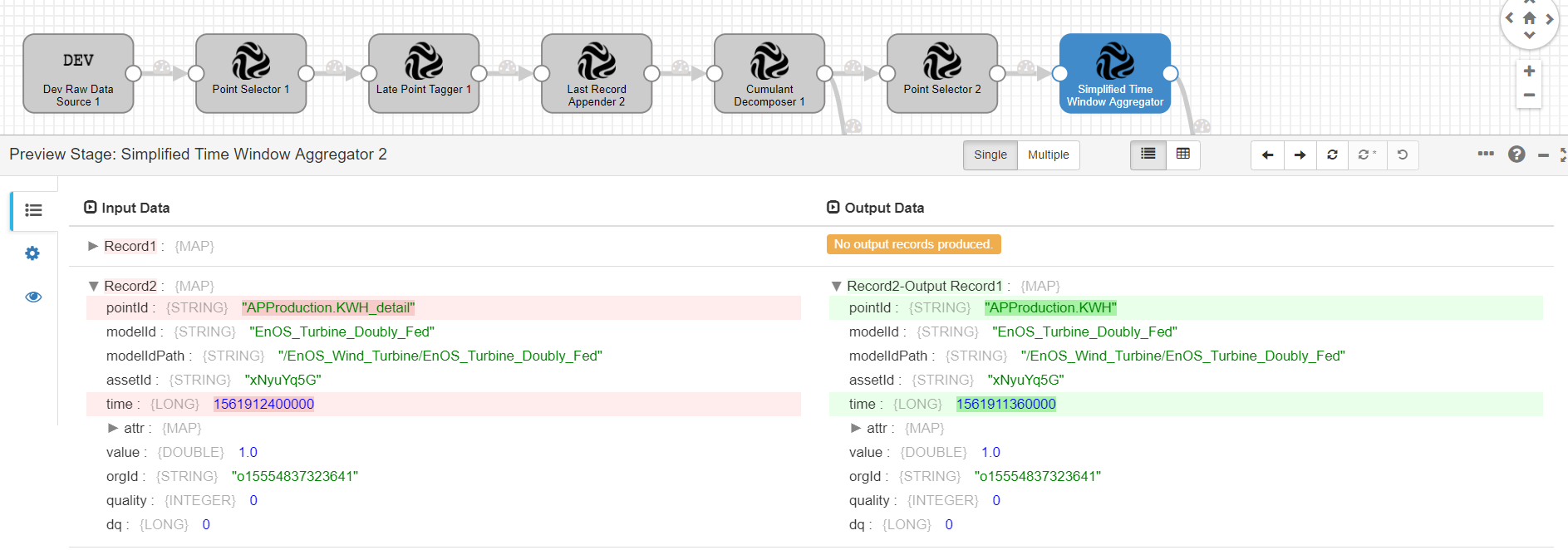
Simplified Time Window Aggregator¶
This stage aggregates records arriving in a specified time window and output the sum of all records. The arrival of a record will trigger the calculation. This stage is used for calculating electric energy data. This stage cannot guarantee idempotence of the calculation results due to failure retries caused by any reasons, such as cluster node exceptions.
Configuration¶
The configuration tabs for this stage are General, Basic, Input/Output, and CacheConfig.
General¶
Name |
Required? |
Description |
|---|---|---|
Name |
Yes |
The name of the stage. |
Description |
No |
The description of the stage. |
Stage Library |
Yes |
The streaming operator library to which the stage belongs. |
Required Fields |
No |
The fields that the data records must contain. If the specified fields are not included, the record will be filtered out. |
Preconditions |
No |
The conditions that must be satisfied by the data records. Records that do not meet the conditions will be filtered out. For example, |
On Record Error |
Yes |
The processing method for error data.
|
Basic¶
Name |
Required? |
Description |
|---|---|---|
Quality Filter |
No |
Filter the data according to the data quality. Only records that meet the quality conditions will be processed by this stage. |
Input/Output¶
Name |
Required? |
Description |
|---|---|---|
Input Point |
Yes |
Specify the input point of the records, using the format {modelId}::{pointId}. For the same configuration row, the modelId must be the same, and the input point and the output point must be different. |
Aggregate Window |
Yes |
Select the duration of the time window, that is, the time interval for the aggregated result output. |
Output Point |
Yes |
Specify the output point of records, using the format {modelId}::{pointId}. For a same configuration row, the modelId must be the same, and the input point and the output point must be different. |
CacheConfig¶
Name |
Required? |
Description |
|---|---|---|
Cache Type |
Yes |
Select the storage type for cache data. Options are Redis and Local storage.
|
Output Results¶
The aggregated output results of this stage are included in the attr struct.
Output Example¶