概述¶
什么是流处理?¶
流处理是一种大数据处理技术。在流处理中,输入数据不受限制,并且没有预定的开始或结束,它只是形成一系列的事件。这些事件以连续‘流’形式进入处理引擎,并进行实时计算。例如,流处理可以检测到包含数百万合法购买的流中的单个欺诈性交易,充当推荐引擎来确定特定客户在实际购物时要显示什么广告或促销,对设备日志文件进行的分析,或者可以通过查询来自温度传感器的数据流并检测温度何时达到冻结点来接收警报。
EnOS 流处理服务¶
EnOS 流数据处理服务是一种基于 Apache Spark™ Streaming 流处理框架的,具有高可扩展性、高吞吐量、和高容错性等优点的流式计算处理平台。EnOS流处理服务的优势在于沉淀了 IoT 领域的流处理常用算法,开发者可通过简单的模板配置,即可完成流数据处理任务的开发。此外,流数据处理服务还提供了多套能源领域计算模板及通用算子,帮助数据开发者无需编码即可快速开发真实业务场景数据处理解决方案,例如:计算风场每日产电量和碳排放量,根据传感器数据的实时分析结果调整机器的参数用户使用EnOS流处理服务可大幅提升数据开发效率,降低开发门槛。
EnOS 流数据处理服务的架构,如下图所示:
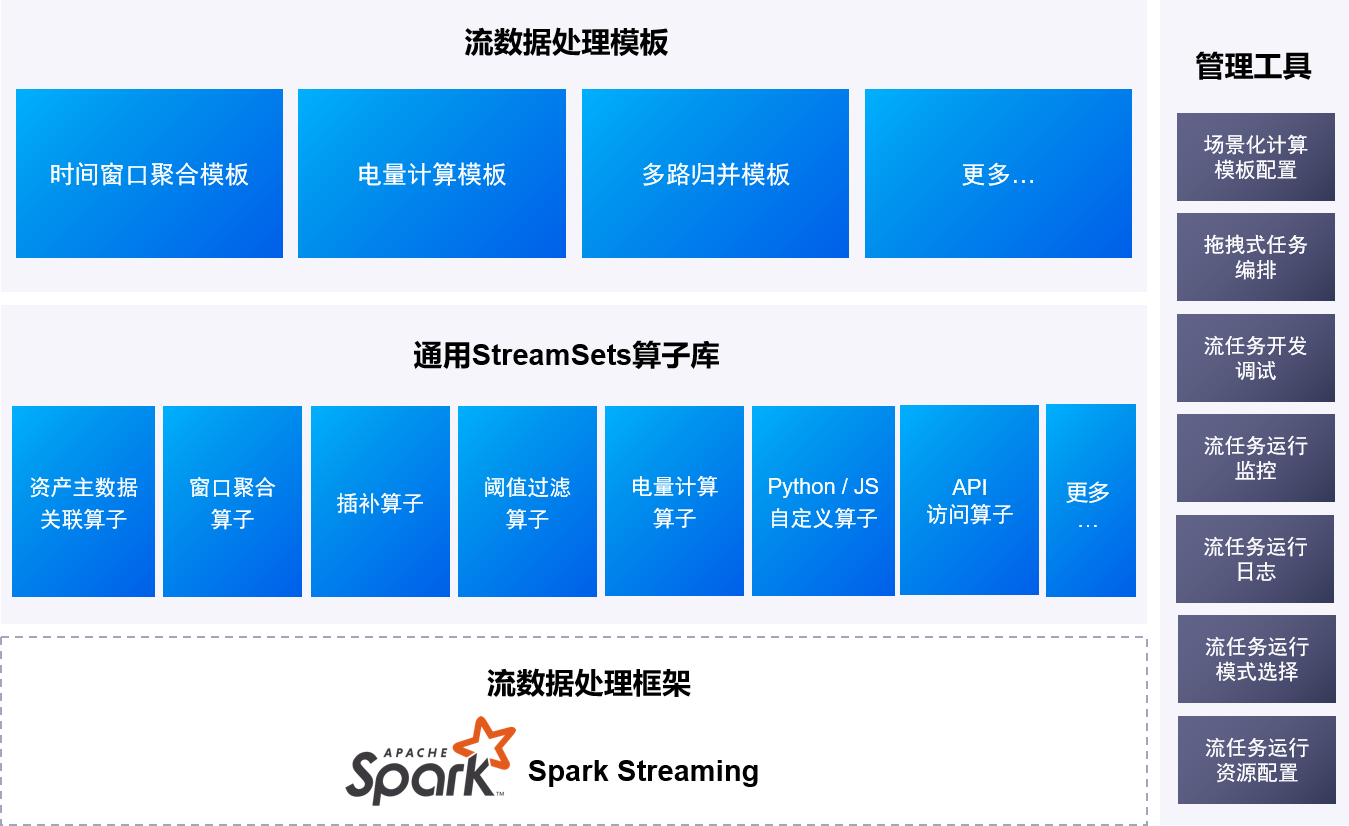
EnOS 流数据处理服务基于底层的 Spark Streaming 流数据处理框架,通过拖拽式的任务编排配置流处理任务。用户通过拖拽算子,给算子输入场景化的配置信息就可轻松便捷的开发流数据处理任务。流数据处理服务还集成了流任务的开发调试,运行监控和查看日志等管理模块,帮助用户全局管理开发监控流数据处理任务。对于不同的业务流程,平台提供了单机模式和集群模式的运行选择,并配以不同的资源,实现了定制化的资源配比,高效利用计算资源。
流数据处理流程¶
EnOS 流数据处理服务的流程如下:
原始数据处理
测点原始数据通过 EnOS 连接层发送到 Kafka。流计算服务对接收到的测点信息进行分析。在处理之前,数据按指定的阈值进行过滤。超过阈值范围的数据将通过插值算法进行处理。
数据计算
经过阈值过滤之后的数据,由数据处理策略中定义的算法进行聚合计算。
输出计算结果
经流数据处理模块处理之后的数据会流入内存数据库(IMDB)和 Kafka,下游模块继续订阅Kafka的所有数据,并按照预先配置的存储策略,将其记录到时序数据库(TSDB)或其它目标存储系统中。用户可通过 EnOS API 查询存储的数据。