Point Selector¶
从每个 OU 对应的 Kafka 中选取流数据处理需要处理的测点,具体功能如下:
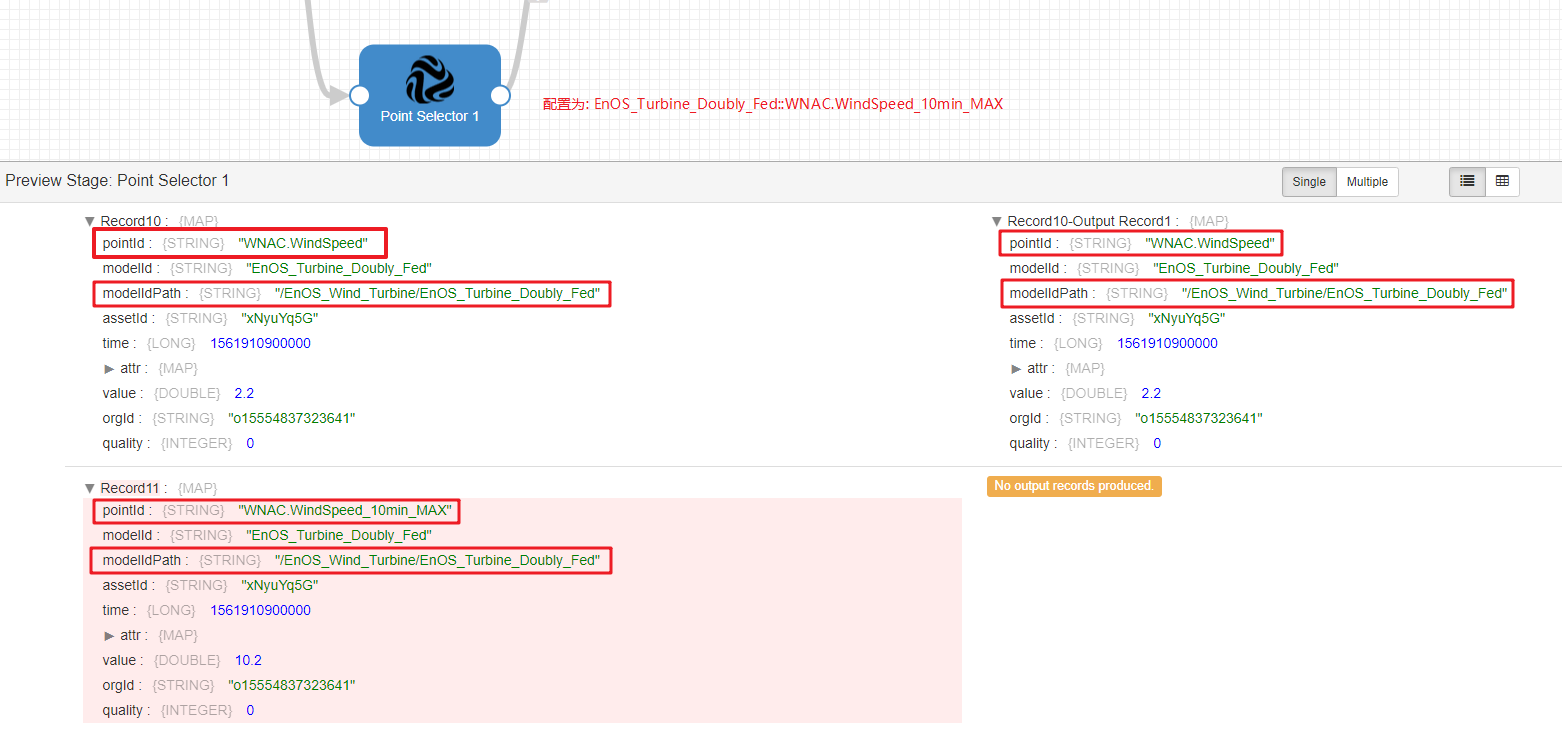
根据配置的模型和测点条件进行选择
支持多条模型测点条件设置,如果输入的数据在配置的模型测点列表中,则输出
如果输入的数据不在配置的模型测点列表中,则不输出
不支持血缘注册
配置详情¶
该算子的配置包括 General,Basic,Input/Output 的详细信息,各字段的配置如下:
General¶
名称 |
是否必须 |
描述 |
|---|---|---|
Name |
Yes |
算子名称 |
Description |
No |
算子描述 |
Stage Library |
Yes |
算子所属的库 |
Required Fields |
No |
数据必须包含的字段,如果未包含指定字段,则 record 将被过滤掉 |
Preconditions |
No |
数据必须满足的前提条件,如果不满足指定条件,则 record 将被过滤掉。例如: |
On Record Error |
Yes |
对错误数据的处理方式,可选:
|
Basic¶
名称 |
是否必须 |
描述 |
|---|---|---|
Quality Filter |
No |
根据数据质量过滤处理数据,只有符合质量条件的 record 才会进行此次处理 |
Input/Output¶
名称 |
是否必须 |
描述 |
|---|---|---|
Input Point |
Yes |
输入当前 pipeline 需要处理的数据输入点,格式为:{模型标识}::{测点标识} |
输出结果¶
该算子的输出结果为经过 pointId 及 modelIdPath 过滤后的 Streaming Records。
输出示例¶