Unit 4. Designing Mechanism for Monitoring Data Arrival¶
The data is required for both model training and model inference, and new data is generated at a non-fixed frequency every day. Therefore, the pipeline needs to be triggered as soon as the data arrives.
This section describes how to design the pipeline of data arrival monitoring and event triggering.
Data Preparation¶
Before orchestrating a pipeline, a status_tbl table should be created in Hive through the following command to record the daily data update:
create table status_tbl(masterid string, updatetime timestamp, flag int);
The structure and fields of the status_tbl table are shown as follows:
Field name |
Description |
|---|---|
masterid |
Site ID |
updatetime |
Data insertion time |
flag |
Status: 1 stands for that the data is written, while 0 stands for the data is used |
Designing Pipelines¶
When the source data is updated, a record can be inserted in the status_tbl table to indicate that the data update of a certain site has been completed. After the pipeline identifies that the data in the status table is updated, it will process the data of the site. After the processing is completed, the status of the site will be updated to 0, indicating that the data of the site on that day has been used.
The real-time monitoring of the status table can be implemented by adding the Recursion operator before the pipeline. The specific process is given as follows:
The pipeline starts running, using the data of the monitoring status table.
The system judges whether the obtained status meets the exit condition, and if it is not met, the polling continues to query the status table.
When the exit condition is met (where you can insert a record that meets the exit condition in the Hive table), it indicates that the data has been updated and it is allowed to perform the subsequent processing.
After adding the Recursion operator in front of the pipeline, the pipeline after orchestration is shown in the figure below:
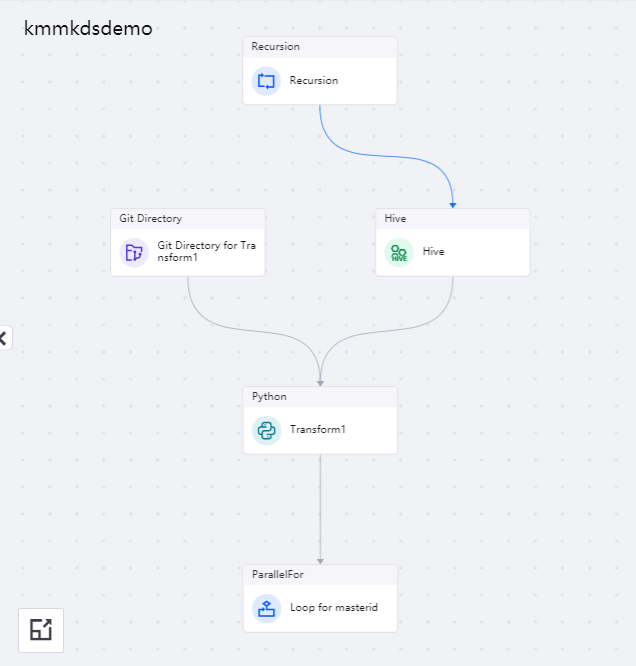
In the sub-canvas of the Recursion operator, use the following operators to orchestrate the pipeline:
Hive operator: query the status table data from Hive and get the keytab and kerberos profiles required by the Hive operator
Git Directory operator: get the file
transform3.pyfrom the Git directory and use it as input of Python operatorPython operator: format the input file
Drag the operators to the editing canvas, and the pipeline after orchestration is shown in the figure below:
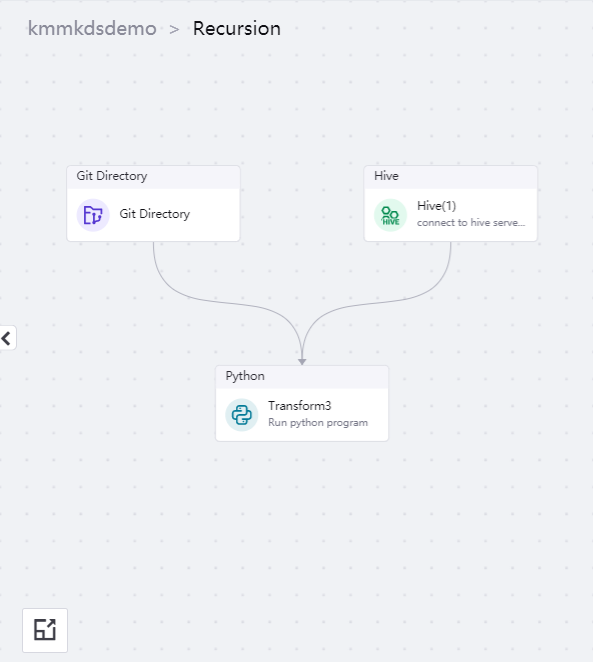
The configuration instructions for each operator orchestrated in the pipeline are given as follows:
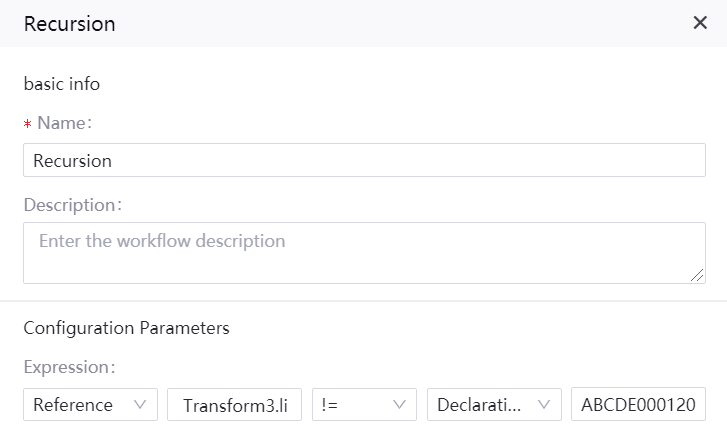
Recursion Operator¶
Name: Recursion
Description: monitor the data arrival and trigger corresponding event
Configuration parameters
The expression format of the Recursion operator is given as follows:
Reference | Transform3.list_output1 | != | Declaration | ABCDE00012020-06-221
An sample of operator configuration is given as follows:
Hive Operator¶
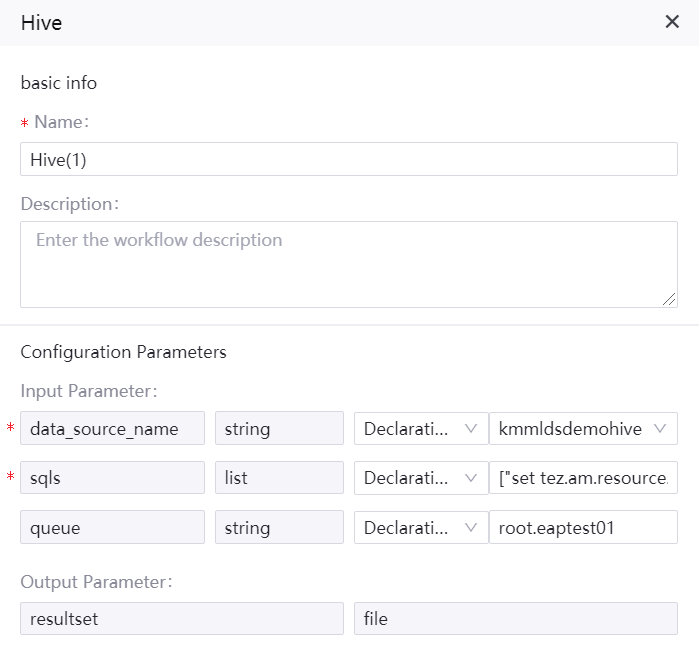
Name: Hive(1)
Description: query status table data, keytab, and krb5 profiles from Hive
Input parameters
Parameter Name |
Data type |
Operation Type |
Value |
|---|---|---|---|
data_source_name |
String |
Declaration |
Name of the registered Hive data source |
sqls |
List |
Declaration |
[“set tez.am.resource.memory.mb=1024”,”select masterid, date(updatetime) as updatetime, flag from status_tbl”] |
queue |
String |
Declaration |
root.eaptest01 (Name of the big data queue applied for through resource management) |
Output parameters
Parameter Name |
Value |
|---|---|
resultset |
File |
An sample of operator configuration is given as follows:
Git Directory operator¶
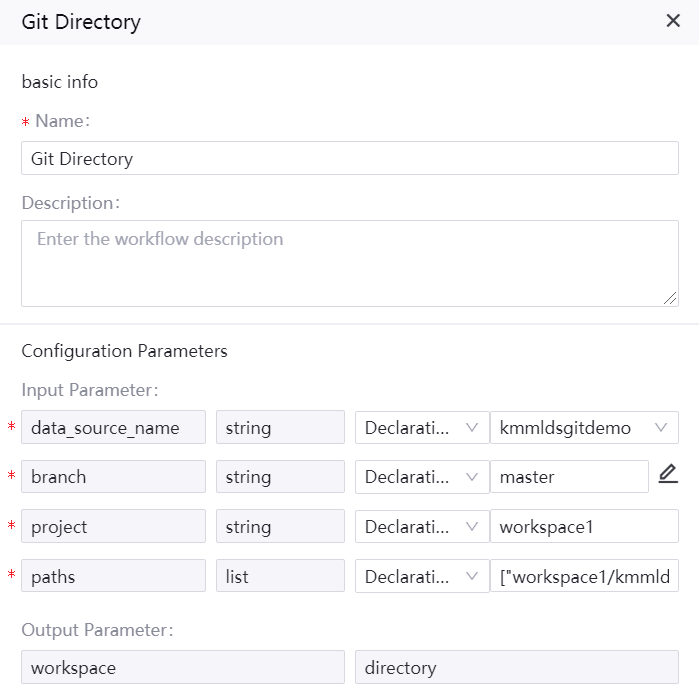
Name: Git Directory
Description: pull the Python code file from the Git directory
Input parameters
Parameter Name |
Data type |
Operation Type |
Value |
|---|---|---|---|
data_source_name |
String |
Declaration |
Name of the registered Git data source |
branch |
String |
Declaration |
master |
project |
String |
Declaration |
workspace1 |
paths |
List |
Declaration |
[“workspace1/kmmlds/transform3.py”] |
Output parameters
Parameter Name |
Value |
|---|---|
workspace |
directory |
paths |
list |
An sample of operator configuration is given as follows:
Python Operator¶
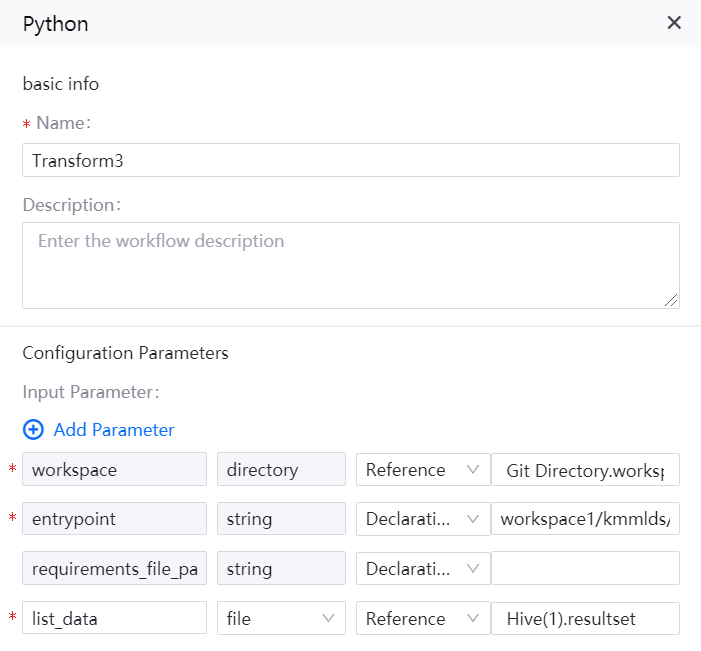
Name: Transform3
Description: format the input file
Input parameters
Parameter Name |
Data type |
Operation Type |
Value |
|---|---|---|---|
workspace |
Directory |
Reference |
Git Directory.workspace |
entrypoint |
String |
Declaration |
workspace1/kmmlds/transform3.py |
requirements_file_path |
String |
Declaration |
|
list_data |
File |
Reference |
Hive(1).resultset |
Output parameters
Parameter Name |
Value |
|---|---|
list_output1 |
String |
An sample of operator configuration is given as follows: