Deploy a Model Version¶
After the model version is staged, it can be deployed to the corresponding container to run.
You can deploy the first version of the model online by following these steps:
In the model list, click a model name to open the Model Version Management page.
Under the Online Instance tab, click New Instance.
Enter the following information:
Instance name: enter the deployment instance name
Resource Pool: select the created resource pool
Tag: enter the deployment instance tags
Description: enter the description of the deployment instance
Click Confirm to complete the deployment instance creation. The newly created deployment instance will be displayed in the Deployment Instance list.
Click the deployment instance name to enter the model deployment page. The model deployment page is mainly composed of editing canvas, deployment configuration bar, and deployment log bar. The cards in the editing canvas can represent models, model versions, and traffic routers. After clicking to select a card, the corresponding configuration items will be displayed in the deployment configuration column. After clicking to select a model version card, the deployment log of the model version will be displayed in the deployment log column.
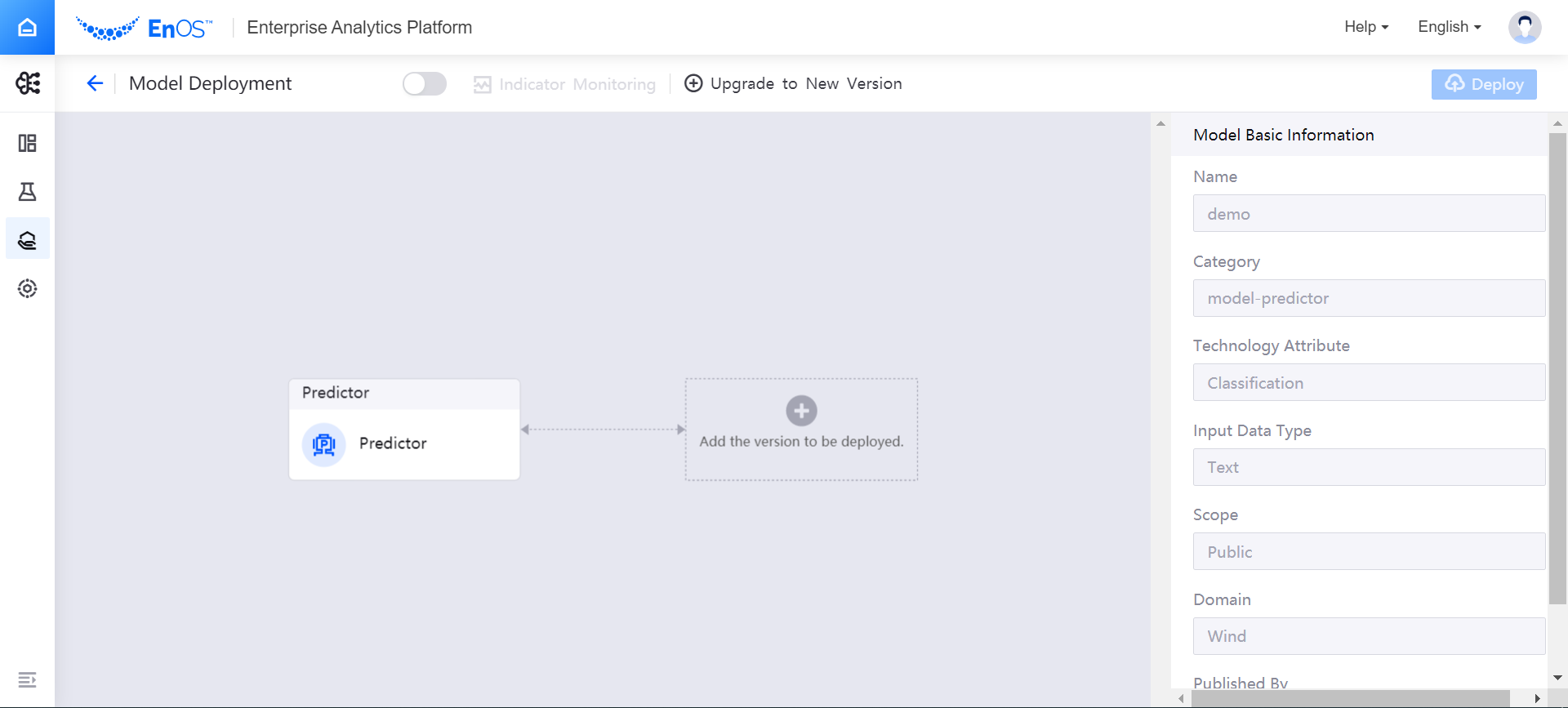
In the editing canvas, click Configure, and then click Add the version to be deployed, select a model version in the pop-up window and click OK.
The added model version will be displayed as a Version card in the editing canvas. Select the Version card, and then configure the resources for running the model version in the Deployment Configuration window on the right side:
Object Resources: displays the container resources for deploying the model version
In the Resource Request section, enter the CPU and memory required to run the model version
In the Resource Limit section, enter the upper limit of CPU and memory for running the model version
If GPUs are available, you can choose whether to use GPUs.
If you need to automatically scale up or down the resources required to run the model service based on the busy rate indicator of the model service, you can turn on Enable Auto Scale and complete the following configuration:
In the Pod Replicas section, enter the minimum and maximum values of Pod replicas
In the Scaling Metrics section, select the trigger indicator (CPU or memory) that initiates the elastic scaling and enter the target average utilization
Click Deploy in the upper right corner of the page, and the system will deploy the model version according to the set resource configuration. Unfold the deployment log to view the progress of the model version deployment.
After the model version is successfully deployed, select the Predictor card in the editing canvas bar on the left side of the model deployment page, and you can view the calling method and calling address of the model service on the right side.
In the Timeout input box, set the
timeoutlimit for accessing the model service API. The minimum time can be set to 1000ms, and the maximum time can be set to 600000ms.Under the Online Test tab, select the Service Calling Test type, and enter the test parameters in the Input box, and then click Test to test and verify the model service.
Under the Online Test tag, select the Feedback Test type, and enter the test parameters in the Input input box, and then click Test to test and verify the model feedback.
Return to the Model Version Management page, and you can check that the status of the model version has changed to
Productionunder the Version Management tab.