单元 2. 设计任务流¶
EAP 智能任务流产品提供了逻辑、文件、模型等类型的算子,满足多种模型训练过程和场景的业务需求。本单元介绍了如何使用算子编排任务流,开发风场发电功率预测模型。
开始前准备¶
编排任务流前,通过以下步骤在智能任务流产品中新建实验:
登录EnOS控制台,从左侧导航栏中选择 企业分析平台 > 机器智能中心 > 智能任务流,打开 实验列表 首页。
点击 新建实验,输入实验的名称(kmmkdsdemo)和描述。
点击 确定,创建实验,打开实验的 线下设计 页面,进行任务流的设计和开发。
设计任务流¶
本教程需要使用以下算子编排任务流:
Hive 算子:从 Hive 中查询出需要训练的场站清单(分区或字段查询),以及获取 Hive 算子所需的 keytab 和 kerberos 配置文件。
Git Directory 算子:从 Git 目录获取
transform1.py文件,用于 Python 算子的输入Python 算子:对输入文件做格式化处理,用于 ParallelFor 算子的输入
ParallelFor 算子:实现对每个场站的循环处理
将算子拖到编辑画布,完成编排后的任务流如下图所示:
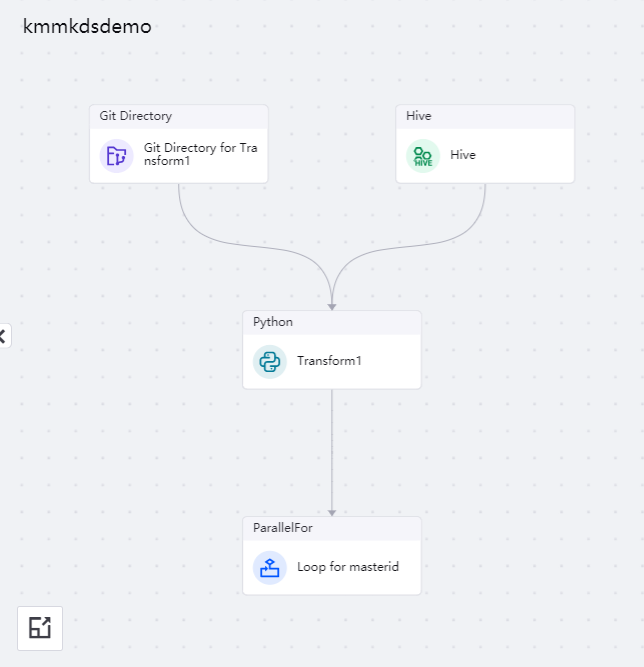
任务流中编排的每个算子的配置说明如下:
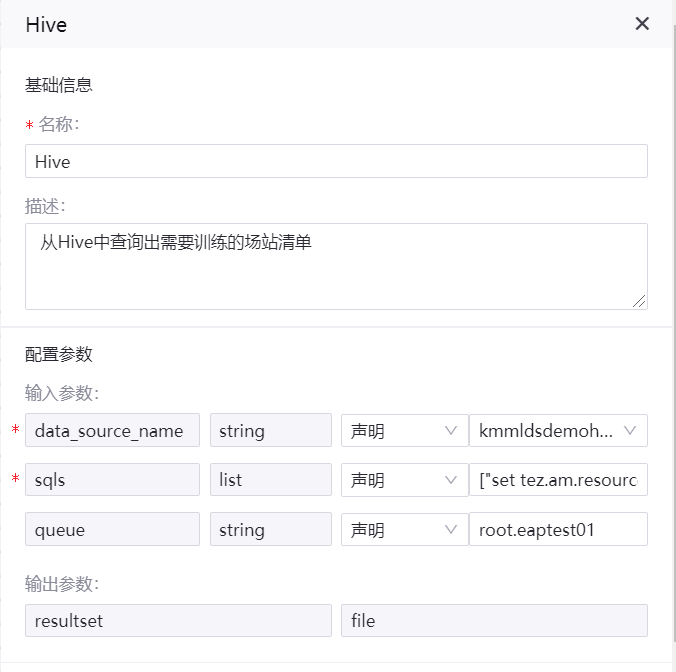
Hive 算子¶
名称:Hive
描述:从Hive中查询出需要训练的场站清单、keytab、和 krb5 配置文件
输入参数
参数名称 |
数据类型 |
操作类型 |
值 |
|---|---|---|---|
data_source_name |
String |
声明 |
注册的 Hive 数据源名称 |
sqls |
List |
声明 |
[“set tez.am.resource.memory.mb=1024”,”select distinct lower(masterid) as masterid from kmmlds1”] |
queue |
String |
声明 |
root.eaptest01(通过资源管理申请的大数据队列名称) |
输出参数
参数名称 |
值 |
|---|---|
resultset |
file |
算子配置示例如下图所示:
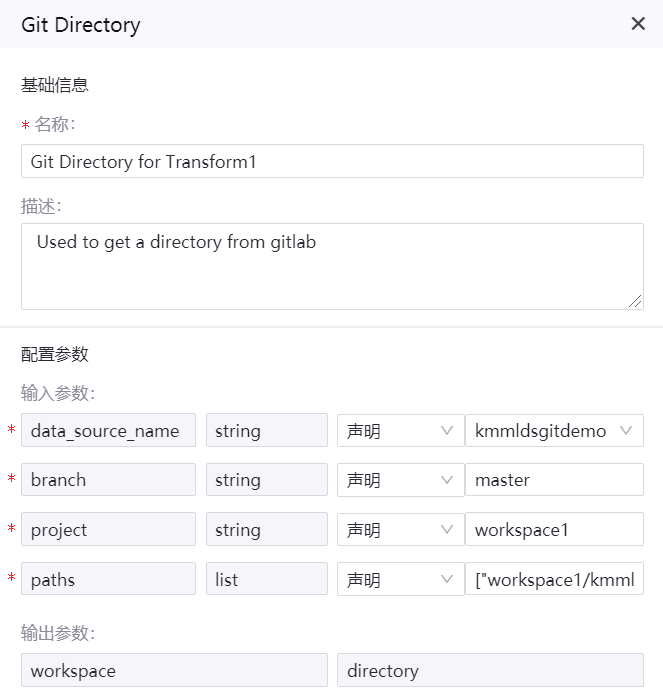
Git Directory 算子¶
名称:Git Directory for Transform1
描述:从 Git 目录拉取 Python 代码文件 transform1.py
输入参数
参数名称 |
数据类型 |
操作类型 |
值 |
|---|---|---|---|
data_source_name |
String |
声明 |
注册的 Git 数据源名称 |
branch |
String |
声明 |
master |
project |
String |
声明 |
workspace1 |
paths |
List |
声明 |
[“workspace1/kmmlds/transform1.py”] |
输出参数
参数名称 |
值 |
|---|---|
workspace |
directory |
paths |
list |
算子配置示例如下图所示:
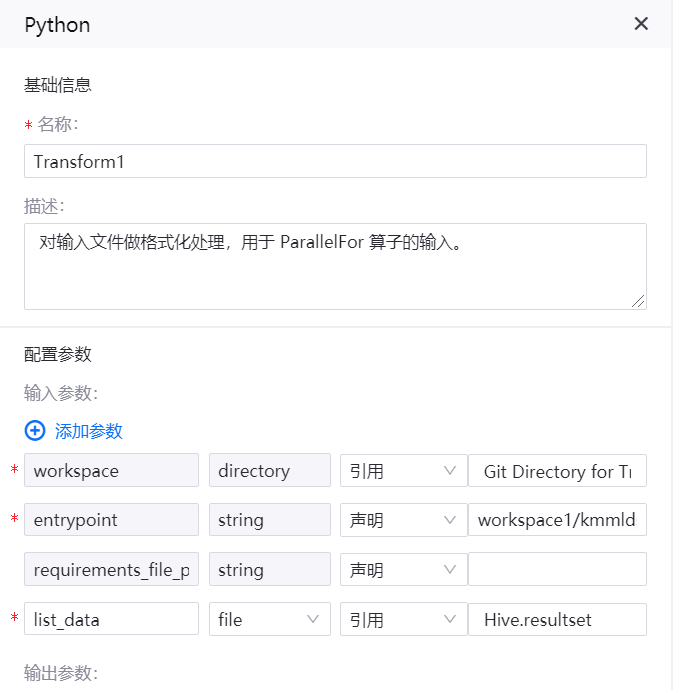
Python 算子¶
名称:Transform1
描述:对输入文件做格式化处理,用于 ParallelFor 算子的输入。Hive查询输出的格式为:[[], [["abcde0001"], ["cgnwf0046"]]],不能直接被 ParallelFor 算子使用,需要通过 Python算子进行格式转换,转换后的格式为:["abcde0001", "cgnwf0046"]。
输入参数
参数名称 |
数据类型 |
操作类型 |
值 |
|---|---|---|---|
workspace |
Directory |
引用 |
Git Directory for Transform1.workspace |
entrypoint |
String |
声明 |
workspace1/kmmlds/transform1.py |
requirements_file_path |
String |
声明 |
|
list_data |
file |
引用 |
Hive.resultset |
输出参数
参数名称 |
值 |
|---|---|
output_list |
list |
算子配置示例如下图所示:
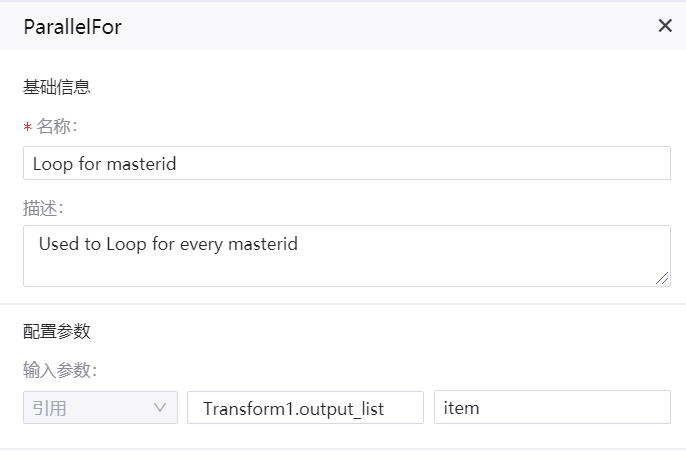
ParallelFor 算子¶
名称:Loop for masterid
描述:在子画布里编排任务流,对每个场站进行处理
输入参数
参数名称 |
操作类型 |
值 |
|---|---|---|
Transform1.output_list |
引用 |
item |
算子配置示例如下图所示: