批数据处理概述¶
数据开发者可使用批数据处理服务通过开发任务流处理离线数据。批数据处理服务还提供脚本开发、任务资源管理、任务运维等功能,帮助你高效地完成数据分析任务。
主要概念
任务流开发过程涉及以下主要概念:
任务流
任务流是一种自动数据处理流,包括任务,_引用_和关系。任务流为有向无环图(DAG),任务流不可为环形任务流。你可以设置一次性或周期性运行的任务流。
任务
任务是任务流的基本要素。任务定义了如何处理数据。运行任务即运行了与任务关联的资源。批数据处理服务提供了以下任务类型:
数据同步任务:数据同步任务将外部数据源中的数据同步到EnOS Hive中。更多信息,参考 数据同步。
SHELL任务:运行 Shell 脚本的任务。
外部应用:运行外部应用类型的任务节点。
PYTHON任务:运行 Python 脚本的任务。
引用
引用是一种作为其后续任务的先决条件的任务或任务流。引用必须是任务流的根节点。一个任务流可以有多个引用。无论任务调度如何设置,任务不会在其引用运行之前运行。
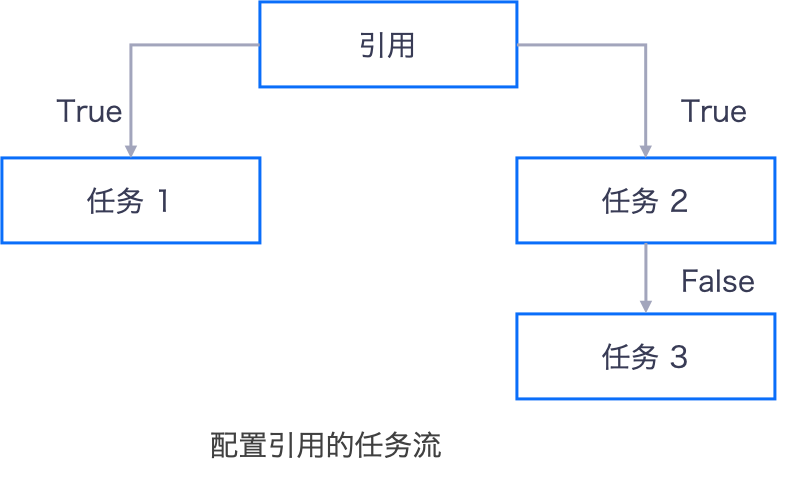
下图显示了引用的任务流。在此示例中包含以下事实:
在引用执行之前,任务1和任务2不会运行。
如果为周期性任务流,则所有任务都在调度参数定义的周期运行。
True和False只会在运维阶段重新运行一个任务时有效。True表示后续任务在运行。False表示后续任务未运行。
关系
上游任务通过关系连接到下游任务,关系是单向的。
资源
资源是由 SHELL 或 PYTHON 类型的任务运行的脚本。支持的资源格式包括:sh,jar,sql,hql,xml,zip,tar,tar.gz,和 py。
任务流开发阶段
任务流开发包含以下几个方面。
配置
在配置阶段,需创建一个包含运行任务的任务流,并通过预跑来验证任务流是否按设计运行。
运行
在运行阶段,任务流会根据调度参数运行。
运维
在运维阶段,你可以重新运行单个任务节点,或重新运行一个节点和它的后续节点以查明任务流中存在的问题。
主要功能
批数据处理工具包提供以下主要功能:
脚本开发
批数据处理服务提供的脚本开发功能支持在线编辑、运行、调试脚本,以及脚本版本管理。开发完成的脚本可在批数据处理任务流中调用。
任务流开发
根据你的业务需求,可设计包含多个任务的任务流,每个任务都会对你的数据执行相关操作。
任务资源
你可以将脚本注册为资源并管理资源的版本。然后,资源可以被任务流中的任务引用。
任务流运维
任务流发布后,任务流可根据配置的参数自动运行,任务流也可通过手动触发预跑运行。运行后,可在任务运维页面查看任务流运行状态并进行相应运维操作。
资源准备¶
批数据处理 - 容器
配置批数据处理任务流之前,需确保OU已经通过 EnOS管理门户 > 资源管理 页面申请 批数据处理 - 容器 资源。有关申请 批数据处理 - 容器 资源的详细说明,参见 容器计算资源准备。