单元 3: 流数据处理¶
Pipeline 1:将 DCM 数据格式转换为 Measurement 数据格式¶
新建高阶流数据处理任务¶
备注
新建高阶流数据处理任务之前,需确保组织已通过 资源管理 服务申请名称为 EDP_INPUT_FORMAT 和 EDP_OUTPUT_FORMAT 的 流数据处理-消息队列 资源。
登录 EnOS 管理控制台,从左侧导航栏中选择 流数据处理 > 流开发。
点击 添加流 图标
 。
。在弹出的 添加流 对话框中,选择或填写以下信息:
流类型:勾选
高阶方式:勾选
新建名称:输入
tutorial_demo_1算子版本:选择
EDH Streaming Calculator Library 0.4.0
设计流数据处理任务¶
在流数据处理任务设计页面中,点击页面右上角的 Stage Library
 ,从下拉菜单中找到需要使用的算子。点击数据处理算子(如 Point Selector),将其添加到 Pipeline 编辑页面。
,从下拉菜单中找到需要使用的算子。点击数据处理算子(如 Point Selector),将其添加到 Pipeline 编辑页面。默认已有算子
EDH Kafka Consumer和EDH Kafka Producer。依次添加算子
Record Formatter、Data Viewer 1、Data Viewer 2。备注
带星号
 的算子为 0.4.0 版本算子库中特有算子,支持新数据格式。如同一名称下有两个算子可选,勾选带星号的算子。
的算子为 0.4.0 版本算子库中特有算子,支持新数据格式。如同一名称下有两个算子可选,勾选带星号的算子。拖拽 Stage 和连接线,将添加的 Stage 按下图所示编排。选中添加的算子,在配置项中完成对该算子的参数配置。
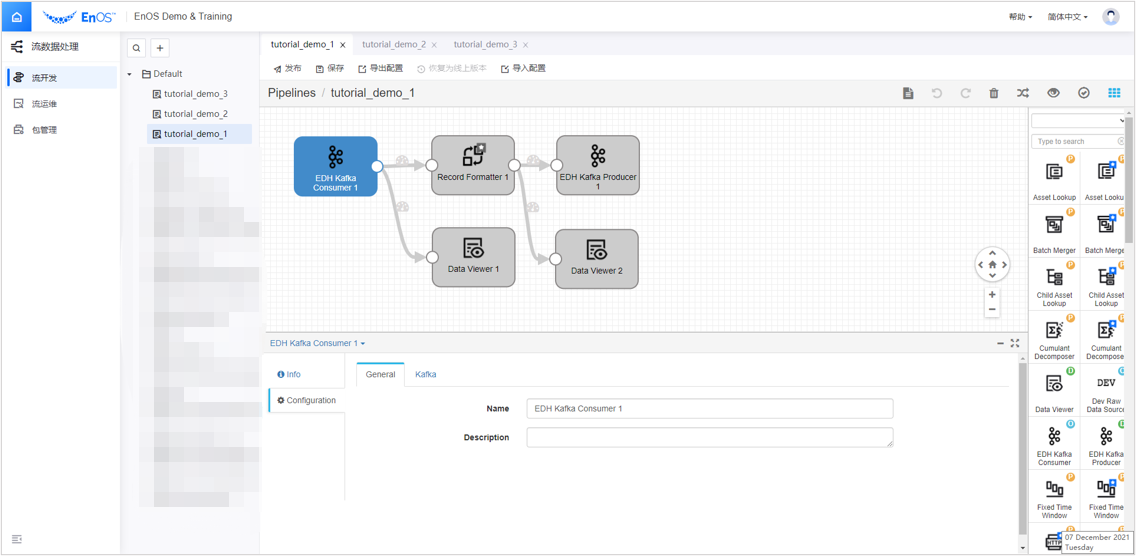
对于添加的算子,在配置项中配置以下参数:
EDH Kafka Consumer:配置该算子,设置输入 Topic。
点击 Configuration - Kafka 页签:
Topic:选择
MEASURE_POINT_ORIGIN_{OUID}Kafka Configuration:
auto.offset.reset:输入
earliestdefault.api.timeout.ms:默认为
600000
Record Formatter:配置该算子,将 DCM 数据格式转换为 Measurement 数据格式。
点击 Configuration - Basic 页签:
Input Format:选择
DCM FormatOutput Format:选择
EDP <MeasurementID> FormatAsset Tag Groups:输入
DcmModel(输入标签组 ID,用于为输入的数据关联相应的设备标签)Measurement Tag Groups:输入
MyHaystack(输入自行创建的标签组 ID,用于为输入的数据关联相应的 Measurement标签 )
EDH Kafka Producer User:配置该算子,设置输出 Topic。
点击 Configuration - Kafka 页签:
Topic:选择
EDP_INPUT_FORMAT_{OUID}Partition Expression:默认为
${record:valueOrDefault("/assetId", record:value("/payload/assetId"))}Kafka Configuration:
retries:默认为
2147483647max.in.flight.requests.per.connection:默认为
1retry.backoff.ms:默认为
100delivery.timeout.ms:默认为
600000
点击页面上方的 保存,保存流数据处理任务的配置信息。
完成算子配置后,点击页面右上角的 Validate
 ,检查 Pipeline 和算子参数配置是否正确,并按照检查结果修改配置。
,检查 Pipeline 和算子参数配置是否正确,并按照检查结果修改配置。点击页面上方的 发布,将流数据处理任务发布上线。
Pipeline 2:计算指定楼宇 1 层以上的每分钟 CO₂ 排放均值¶
新建高阶流数据处理任务¶
登录 EnOS 管理控制台,从左侧导航栏中选择 流数据处理 > 流开发。
点击 添加流 图标
。在弹出的 添加流 对话框中,选择或填写以下信息:
流类型:勾选
高阶方式:勾选
新建名称:输入
tutorial_demo_2,算子版本:选择
EDH Streaming Calculator Library 0.4.0
设计流数据处理任务¶
在流数据处理任务设计页面中,点击页面右上角的 Stage Library
,,从下拉菜单中找到需要使用的算子。点击数据处理算子(如 Point Selector),将其添加到 Pipeline 编辑页面。默认已有算子
EDH Kafka Consumer和EDH Kafka Producer。依次添加算子
Record Filter、Off Limit Tagger、Fixed Time Window Aggregator、Data Viewer 1、Data Viewer 2、Data Viewer 3、Data Viewer 4。备注
带星号
的算子为 0.4.0 版本算子库中特有算子,支持新数据格式。如同一名称下有两个算子可选,勾选带星号的算子。拖拽 Stage 和连接线,将添加的 Stage 按下图所示编排。选中添加的算子,在配置项中完成对该算子的参数配置。
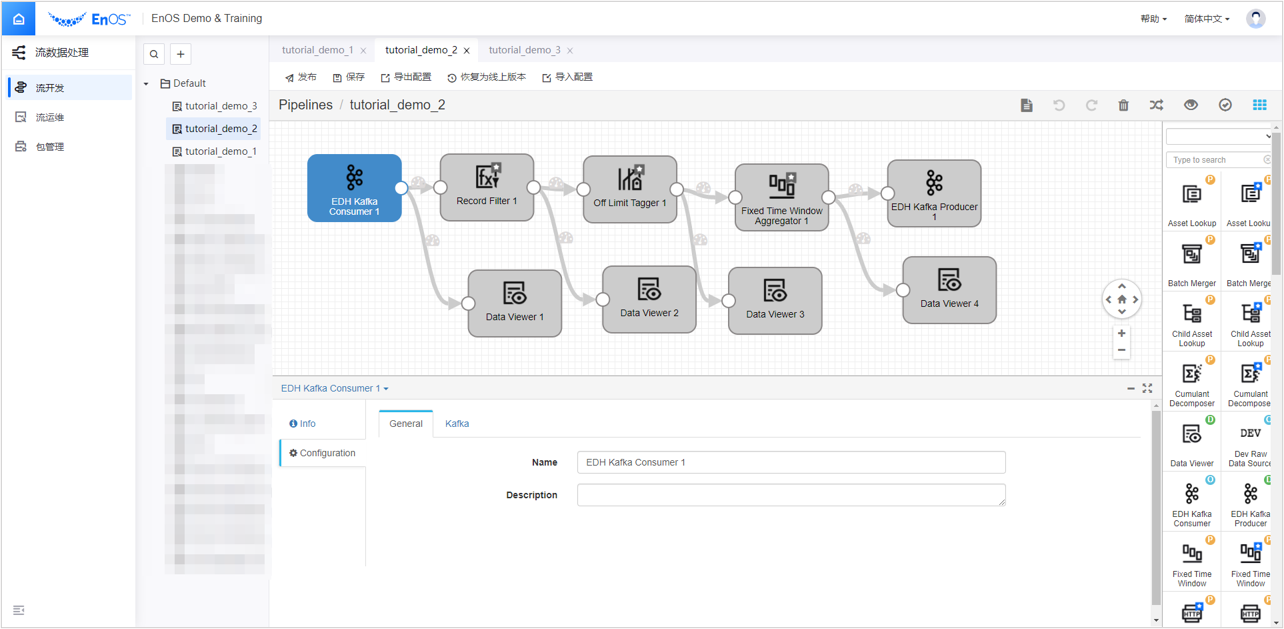
对于添加的算子,在配置项中配置以下参数:
EDH Kafka Consumer:配置该算子,选择 Pipeline 1 最后输出的 Topic 作为 Pipeline 2 的输入。
点击 Configuration - Kafka 页签:
Topic:选择
EDP_INPUT_FORMAT_{OUID}Kafka Configuration:
auto.offset.reset:默认为
latestdefault.api.timeout.ms:默认为
600000
Record Filter:配置该算子,根据标签获得所需数据。
点击 Configuration - Input/Output 页签:
Filter Expression:输入 :
seq.contains_key(record.assetTags.DcmModel, 'DcmModel:Test_SGBuilding') && #`record.measurementTags.MyHaystack.MyHaystack:zone.floor` > 1
Output Measurement ID:输入
Test_SGBuilding::ZoneCO2
Off Limit Tagger:配置该算子,过滤数值在(0,90)范围内的数据,作为 Test_SGBuilding::ZoneCO2_a 临时计算点输出。
点击 Configuration - Input/Output 页签:
Input Measurement:输入
Test_SGBuilding::ZoneCO2OpenClose:选择
(x,y)Min-Max:输入
0,90.00Output Measurement:输入
Test_SGBuilding::ZoneCO2_a
Fixed Time Window Aggregator:配置该算子,计算 1 分钟平均值,作为 Test_SGBuilding::ZoneCO2_b 临时计算点输出。
点击 Configuration - TriggerConfig 页签:
Latency (Minute):选择
0
点击 Configuration - Input/Output 页签:
Input Measurement:输入
Test_SGBuilding::ZoneCO2_aFixed Window Size:输入
1Fixed Window Unit:选择
minuteAggregator Policy:选择
avgOutput Measurement:输入
Test_SGBuilding::ZoneCO2_b
点击 Configuration - ExtraConfig 页签:
Output Data Type:选择
From Catalog Service
EDH Kafka Producer User:配置该算子,设置输出 Topic。
点击 Configuration - Kafka 页签:
Topic:选择
EDP_OUTPUT_FORMAT_{OUID}Partition Expression:默认为
${record:valueOrDefault("/assetId", record:value("/payload/assetId"))}Kafka Configuration:
retries:默认为
2147483647max.in.flight.requests.per.connection:默认为
1retry.backoff.ms:默认为
100delivery.timeout.ms:默认为
600000
点击页面上方的 保存,保存流数据处理任务的配置信息。
完成算子配置后,点击页面右上角的 Validate
,检查 Pipeline 和算子参数配置是否正确,并按照检查结果修改配置。点击页面上方的 发布,将流数据处理任务发布上线。
Pipeline 3:将 Measurement 数据格式转换回 DCM 数据格式输出¶
新建高阶流数据处理任务¶
登录 EnOS 管理控制台,从左侧导航栏中选择 流数据处理 > 流开发。
点击 添加流 图标
。在弹出的 添加流 对话框中,选择或填写以下信息:
流类型:勾选
高阶方式:勾选
新建名称:输入
tutorial_demo_3,算子版本:选择
EDH Streaming Calculator Library 0.4.0
设计流数据处理任务¶
在流数据处理任务设计页面中,点击页面右上角的 Stage Library
,,从下拉菜单中找到需要使用的算子。点击数据处理算子(如 Point Selector),将其添加到 Pipeline 编辑页面。默认已有算子
EDH Kafka Consumer和EDH Kafka Producer。依次添加算子
Asset Lookup、JavaScript 1、JavaScript 2、Point Lookup、Record Formatter、Data Viewer 1、Data Viewer 2、Data Viewer 3、Data Viewer 4、Data Viewer 5、Data Viewer 6。备注
带星号
的算子为 0.4.0 版本算子库中特有算子,支持新数据格式。如同一名称下有两个算子可选,勾选带星号的算子。拖拽 Stage 和连接线,将添加的 Stage 按下图所示编排。选中添加的算子,在配置项中完成对该算子的参数配置。
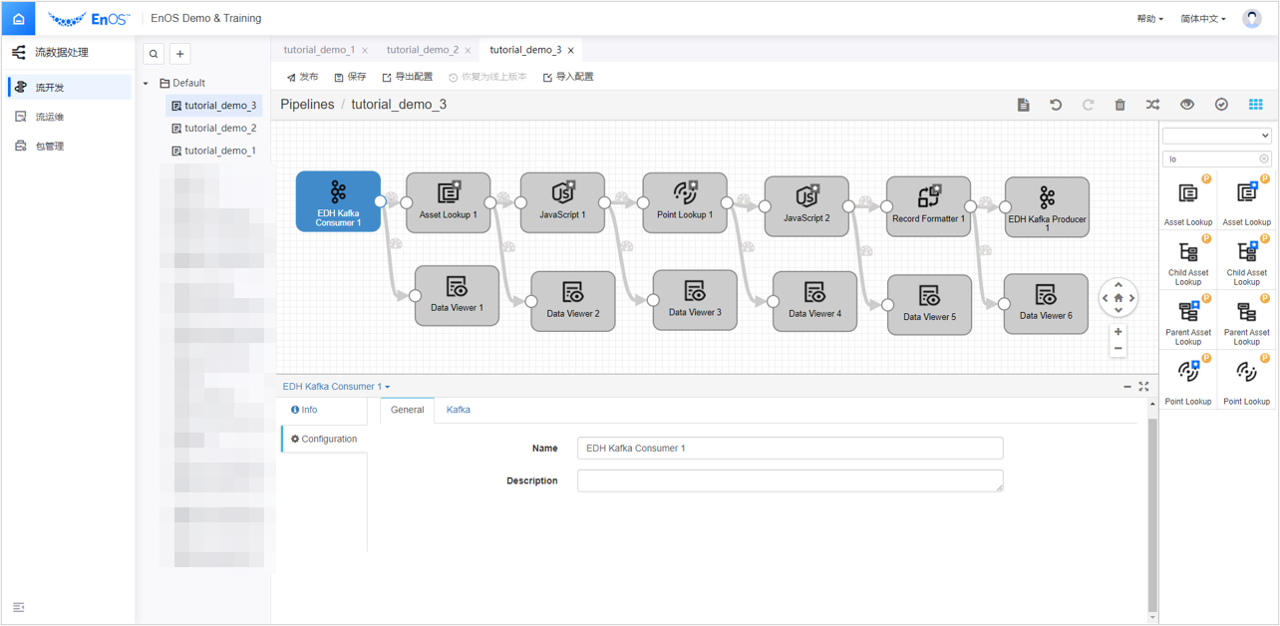
对于添加的算子,在配置项中配置以下参数:
EDH Kafka Consumer:配置该算子,选择 Pipeline 2 最后输出的 Topic 作为 Pipeline 3 的输入。
点击 Configuration - Kafka 页签:
Topic:选择
EDP_OUTPUT_FORMAT_{OUID}Kafka Configuration:
auto.offset.reset:默认为
latestdefault.api.timeout.ms:默认为
600000
Asset Lookup:配置该算子,进行设备查找。
点击 Configuration - Input/Output 页签:
Input Measurement:输入
Test_SGBuilding::ZoneCO2_cOutput Measurement:输入
Test_SGBuilding::ZoneCO2_d
点击 Configuration - Criteria 页签:
Attribute:选择
AllTag:选择
AllExtra:选择
All
JavaScript 1:配置该算子,确定 modelId、modelIdPath 和 pointId。
点击 Configuration - Input/Output 页签:
Input Measurement:输入
Test_SGBuilding::ZoneCO2_dOutput Measurement:输入
Test_SGBuilding::ZoneCO2_e
点击 Configuration - JavaScript 页签:
Script:输入:
for (var i = 0; i < records.length; i++){
try{
var record = records[i];
if(record.value['measurementId'] == 'Test_SGBuilding::ZoneCO2_d'){
//查询出来填写
record.value['measurementId'] = 'Test_SGBuilding::ZoneCO2_e';
record.value['modelId'] = record.value['attr']['tslAssetLookup']['extra']['modelId'];
record.value['modelIdPath'] = record.value['attr']['tslAssetLookup']['extra']['modelIdPath'];
//手动填写
record.value['pointId'] = 'temp_avg';
}
output.write(record);
}catch(e){
// trace the exception
error.trace(e);
error.write(records[i], e);
}
}
Point Lookup:配置该算子,根据 JavaScript 进行测点的查找
点击 Configuration - Input/Output 页签:
Input Measurement:输入
Test_SGBuilding::ZoneCO2_eOutput Measurement:输入
Test_SGBuilding::ZoneCO2_f
点击 Configuration - Criteria 页签:
Tag:选择
AllExtra:选择
All
JavaScript 2:配置该算子,确定质量位。
点击 Configuration - Input/Output 页签:
Input Measurement:输入
Test_SGBuilding::ZoneCO2_fOutput Measurement:输入
Test_SGBuilding::ZoneCO2_g
点击 Configuration - JavaScript 页签:
Script:输入:
for (var i = 0; i < records.length; i++){
try{
var record = records[i];
if(record.value['measurementId'] == 'Test_SGBuilding::ZoneCO2_f'){
record.value['measurementId'] = 'Test_SGBuilding::ZoneCO2_g';
//质量位查询设置,也可以自己指定
record.value['hasQuality'] = record.value['attr']['tslPointLookup']['extra']['hasQuality'];
}
output.write(record);
}catch(e){
// trace the exception
error.trace(e);
error.write(records[i], e);
}
}
Record Formatter:配置该算子,将 Measurement 数据格式转换回 DCM 数据格式。
点击 Configuration - Basic 页签:
Input Format:选择
EDP <MeasurementID> FormatOutput Format:选择
DCM Format
EDH Kafka Producer User:配置该算子,设置输出 Topic。
点击 Configuration - Kafka 页签:
Topic:选择
MEASURE_POINT_CAL_{OUID}Partition Expression:默认为
${record:valueOrDefault("/assetId", record:value("/payload/assetId"))}Kafka Configuration:
retries:默认为
2147483647max.in.flight.requests.per.connection:默认为
1retry.backoff.ms:默认为
100delivery.timeout.ms:默认为
600000
点击页面上方的 保存,保存流数据处理任务的配置信息。
完成算子配置后,点击页面右上角的 Validate
,检查 Pipeline 和算子参数配置是否正确,并按照检查结果修改配置。点击页面上方的 发布,将流数据处理任务发布上线。
点击左侧导航栏中选择 流运维, 逐个点击上述三个流数据处理任务行末的 启动 ![]() ,启动流数据处理任务。
,启动流数据处理任务。
在 流运维 页面中,可以查看到 流任务运行结果。
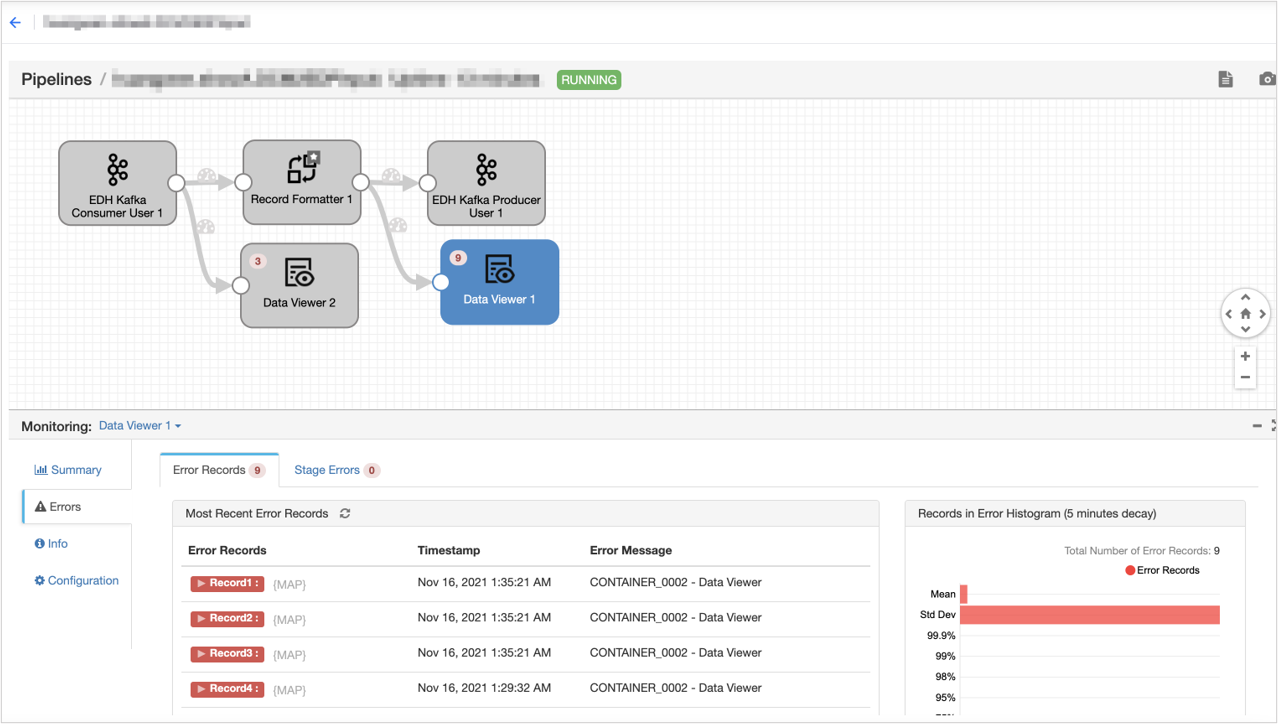
更多有关高阶流数据处理任务的操作,参考 开发高阶流数据处理任务。