Getting Started: Querying Data Quality Report¶
This guide intends to help you learn how to use the StreamSets operators for data quality tagging to mark data with quality level tags and then query a data quality report.
Prerequisites¶
- You have applied for the stream computing resources and TSDB storage resources through Resource Management.
- You have permission to access the Data Quality module and the StreamSets feature of the Stream Data Processing module.
- Devices are connected and uploading data to the EnOS cloud.
Goals and Data Preparation¶
Goal
The goal of this guide is to mark the AI type measuring point test_raw with quality level tags, and query the quality report of this measuring point.
Data Preparation
- Model configuration: The model used in this guide (testModel) is configured as follows:
| Feature Type | Name | Identifier | Point Type | Data Type |
| Measuring Point | test_raw | test_raw | AI | DOUBLE |
| Measuring Point | test_raw_filter | test_raw_filter | AI | DOUBLE |
| Measuring Point | test_raw_dq | test_raw_dq | AI | DOUBLE |
Note
- The test_raw measuring point is for ingesting raw data, the test_raw_filter measuring point is for receiving the data that is filtered by the specified threshold, and the test_raw_dq point is for receiving the output of raw data being processed by the stream processing engine with data quality tags.
- Ensure that the both the input point and output point are of AI type.
- Data connection: See Device Connection to complete the data ingestion for the test_raw measuring point.
Procedure¶
The steps for marking data quality tags and generating quality reports are as follows:
- Create and develop a stream processing job to mark the raw data with quality level tags
- Save, publish, and start the stream processing job
- View the data quality report
Step 1: Create and develop a stream processing job to mark the raw data with quality level tags¶
- Go to the EnOS Console > Stream Data Processing > StreamSets menu to create and edit a stream data processing job.
- Click the Create New Pipeline button to add a stream data processing job.
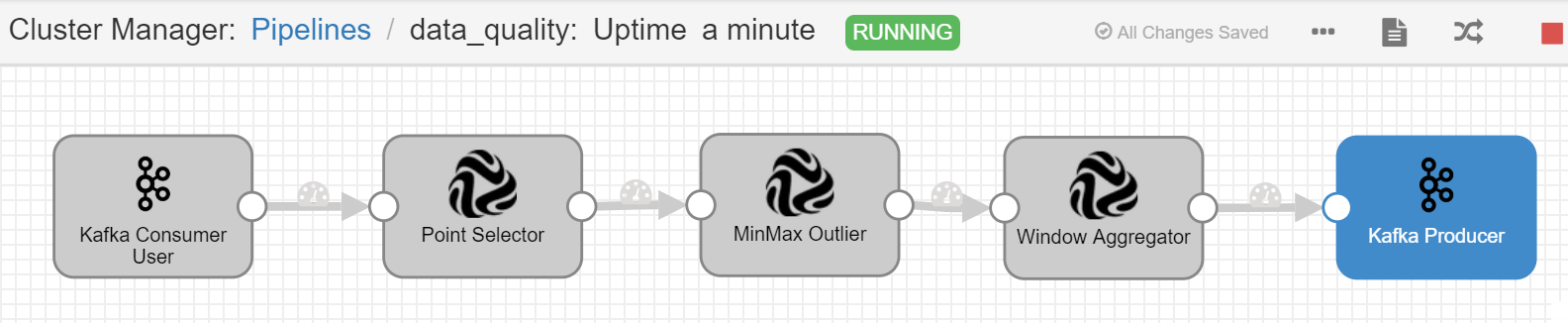
- Enter the editor and use the following StreamSets operators to edit the stream data processing job. Configuration of the Stages are as follows:
| No. | StreamSets Stage | Parameter Configuration | Description |
| 1 | Kafka Consumer User | Topic: MEASURE_POINT_INTERNAL; Data Format: JSON | Configure the data source. | |
| 2 | Point Selector | Select Policy: testModel::test_raw | Select the measuring point to be processed by the stream data processing job. |
| 3 | MinMax Outlier | Model Point: testModel::test_raw; OpenClose: (x,y); Min-Max: 0,90.00; Output PointId: test_raw_filter | Configure the threshold rules for the raw data: the threshold values for the input point is (0, 90.00), and the output point is test_raw_filter. |
| 4 | Window Aggregator | Aggregation Window Type: Fixed Window Aggregator; Fixed Window Unit: minute; Fixed Window Size: 2; Latency (Minute): 0; Model::PointIn: testModel::test_raw_filter; Aggregator Policy: avg; PointOut: test_raw_dq | Configure the window aggregation rules: the window type is fixed window, the window size is set as 2 min, the latency is set as 0, and the aggregation algorithm is set as avg. |
| 5 | Kafka Producer | Topic: MEASURE_POINT_INTERNAL; Data Format: JSON | Configure the data output. |
The figure below shows the configuration of the stream data processing job:
Step 2: Save, publish, and start the stream processing job¶
After configuring the stream data processing job, click the Start icon to start the job. Return to the job list page to view the job running status.
Step 3: View the data quality report¶
Go to the EnOS Console > Data Quality module and enter the query conditions (model: testModel; measuring points: test_raw_filter and test_raw_dq) to query the data quality report of the measuring points. For details of the data quality report, see Viewing Data Quality Report.