SQL编写范例¶
数据联邦服务下的联邦查询支持输入SQL语句查询数据源中的数据。输入的SQL语句需要遵循 ANSI/SQL2003 标准,常用的SQL语句包括:
show schemas:查看所有添加的数据源结构describe {表的完整路径}:查询表结构(如果文件不是csv结构,可能无法展示其结构)select {* / 列名} from {表名} where {column_name} operator {value}:检索数据库表中的数据行和列注意:通道类型不同,表名的编写规则不同。当通道类型为 READ 时,单源查询表名由
库名称.表名称构成;跨源查询表名称由数据源名称.库名称.表名称构成。当通道类型为 DOWNLOAD 时,表名由库名称.表名称构成。
使用限制¶
由于文件系统读取默认为 varchar 类型,只支持COUNT,MAX,MIN这三个函数。如果需要使用其他函数,需要使用
CAST (xxxx AS type)对数据类型进行转换。Redis中有的表是固定的名字,因此在使用
JOIN时需要定义表名字的别名。JOIN一定要有条件。不支持
CROSS JOIN。使用
BETWEEN ... AND时,也需要使用CAST (xxxx AS type)对数据类型进行转换。
数据查询SQL范例¶
下表列出从各类数据源查询数据的SQL语句范例。
数据源 |
表结构 |
范例配置 |
SQL范例 |
|---|---|---|---|
MySQL |
data_source.database.table |
|
|
Hive |
data_source.database.table |
|
|
Redis |
data_source.db.type |
|
|
HDFS |
data_source.folder0.folder1.file0(文件系统区别于数据库类型,访问时结构为数据源、文件夹、文件) |
|
|
S3/Blob |
data_source.bucket.folder1.file0(S3/Blob同样是文件系统,但是需要增加bucket) |
|
|
Kafka |
data_source.topic(Kafka区别于所有数据源,只有数据源和Topic两级) |
|
|
常用Select语法¶
select {* / 列名} from {表名} where {column_name} operator {value}
select * from stock_information where stockid = str(nid)
stockname = 'str_name'
stockname like '% find this %'
--------- 只能在使用like关键字的where子句中使用通配符)
or stockpath = 'stock_path'
or stocknumber < 1000
and stockindex = 24
not stock*** = 'man'
stocknumber between 20 and 100
stocknumber in(10,20,30)
order by stockid desc(asc) --------- 排序,desc-降序,asc-升序
order by 1,2 --------- by列号
stockname = (select stockname from stock_information where stockid = 4)
--------- 子查询
--------- 除非能确保内层select只返回一个行的值,
--------- 否则应在外层where子句中用一个in限定符
select distinct column_name form table_name --------- distinct指定检索独有的列值,不重复
select stocknumber , (stocknumber + 10)`stocknumber+10` from table_name
select stockname , (count(*)`count` from table_name group by stockname
--------- group by 将表按行分组,指定列中有相同的值
having count(*) = 2 --------- having选定指定的组
select *
from table1, table2
where table1.id = table2.id
select stockname from table1
union [all] ----- union合并查询结果集,all-保留重复行
select stockname from table2
常用函数¶
统计函数¶
AVG:求平均值
COUNT:统计数目
MAX:求最大值
MIN:求最小值
SUM:求和
STDDEV():返回表达式中所有数据的标准差
STDDEV_POP():返回总体标准差
VARIANCE():返回表达式中所有值的统计变异数
VAR_POP():返回总体变异数
算数函数¶
三角函数
SIN(float_expression):返回以弧度表示的角的正弦
COS(float_expression):返回以弧度表示的角的余弦
TAN(float_expression):返回以弧度表示的角的正切
COT(float_expression):返回以弧度表示的角的余切
INTEGER/MONEY/REAL/FLOAT类型
EXP(float_expression):返回表达式的指数值
LOG(float_expression):返回表达式的自然对数值
LOG10(float_expression):返回表达式的以10 为底的对数值
SQRT(float_expression):返回表达式的平方根
取近似值函数
CEILING(numeric_expression):返回大于等于表达式的最小整数,返回的数据类型与表达式相同
FLOOR(numeric_expression):返回小于等于表达式的最小整数,返回的数据类型与表达式相同
ROUND(numeric_expression):返回以 integer_expression 为精度的四舍五入值
ABS(numeric_expression):返回表达式的绝对值返回的数据类型与表达式相同
SIGN(numeric_expression):测试参数的正负号返回0 零值1 正数或-1 负数返回的数据类型
PI():返回值为π,即3.1415926535897936
RAND([integer_expression]):用任选的[integer_expression]做种子值得出0-1之间的随机浮点数
字符串函数
ASCII():返回字符表达式最左端字符的ASCII码值
CHAR():用于将ASCII码转换为字符,如果没有输入0 ~ 255之间的ASCII码值,CHAR函数会返回一个NULL值
LOWER():把字符串全部转换为小写
UPPER():把字符串全部转换为大写
日期函数
DAY():返回date_expression中的日期值
MONTH():返回date_expression中的月份值
YEAR():返回date_expression中的年份值
HDFS 查询语法规则¶
通过数据联邦通道跨组织访问 HDFS 中的数据之前,需通过 数据资产权限 页面添加跨组织访问 HDFS 的权限策略。
HDFS 查询不支持通配符。若以通配符授权 HDFS 中的访问路径,运行 SQL 会报错,需要在查询 SQL 中编写具体的 HDFS 路径。
对 TSDB 数据的聚合示例¶
本示例以存储在TSDB中的以下数据为例,介绍如何通过联邦通道对数据进行查询和聚合处理:
设备:”hiGNjDBJ”, “9wmyXxKf”
测点:”ai_point_1”,”ai_point_2”,”ai_point_3”,”ai_point_4”,”ai_point_5”
数据密度:每秒1个测点值
查询时间范围:”2020-11-01 00:00:00” “2020-12-01 00:00:00” (86400条数据/point)
通道类型:Read - 跨源分析
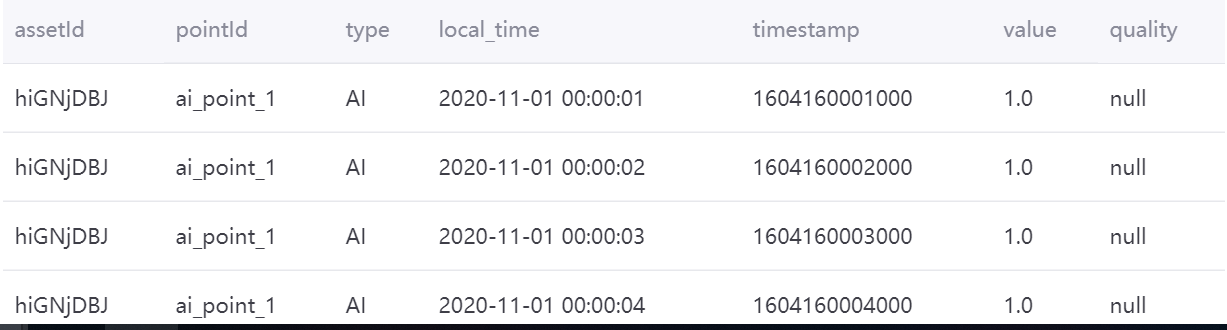
多设备多测点¶
使用以下查询语句,对多个设备多个测点在一天时间内的数据进行小时级聚合,并求均值:
select cast((`timestamp`/3600000) * 3600000 as timestamp) as ts , assetId, pointId, avg(value) as point_avg from tsdb.o15504722874071.eniot where assetId in ('hiGNjDBJ', '9wmyXxKf') and pointId in('ai_point_1','ai_point_2')and local_time >= '2020-11-01 00:00:00' and local_time < '2020-11-02 00:00:00' GROUP BY (`timestamp`/3600000), assetId,pointId
聚合结果如下图所示:
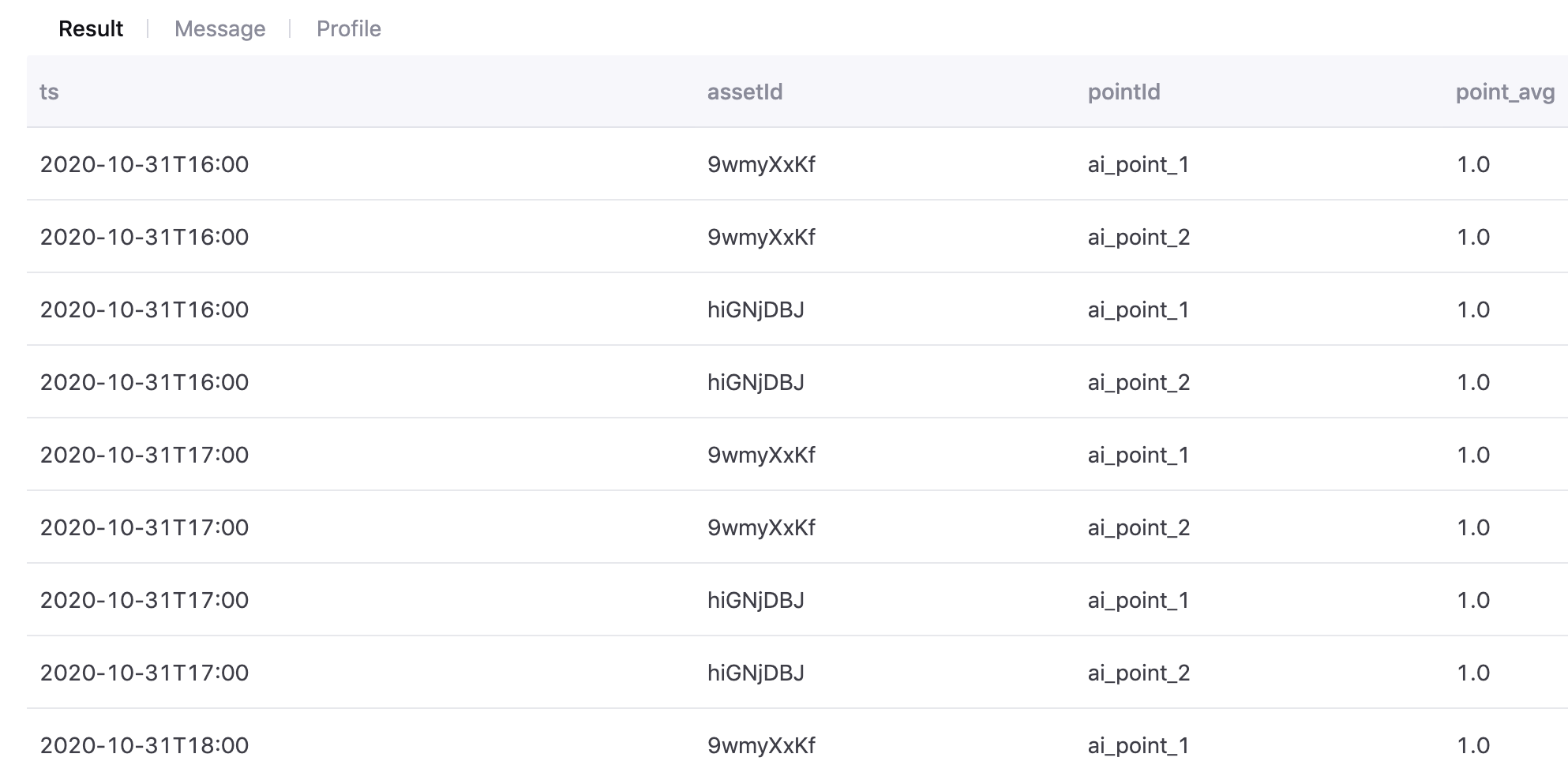
多设备单测点¶
使用以下查询语句,对多个设备单个测点的数据在聚合后进行切面上的聚合计算:
point_x=sum(device.point_x)
with t as (select cast((`timestamp`/3600000) * 3600000 as timestamp) as ts , assetId, pointId, avg(value) as value from tsdb.o15504722874071.eniot where assetId in ('hiGNjDBJ', '9wmyXxKf') and pointId in('ai_point_1','ai_point_2')and local_time >= '2020-11-01 00:00:00' and local_time < '2020-11-02 00:00:00' GROUP BY (`timestamp`/3600000), assetId,pointId) select t.pointId,t.ts,sum(t.value) as sumPointValue from t where t.pointId in('ai_point_1','ai_point_2') group by t.ts, t.pointId ORDER BY ts
聚合结果如下图所示:
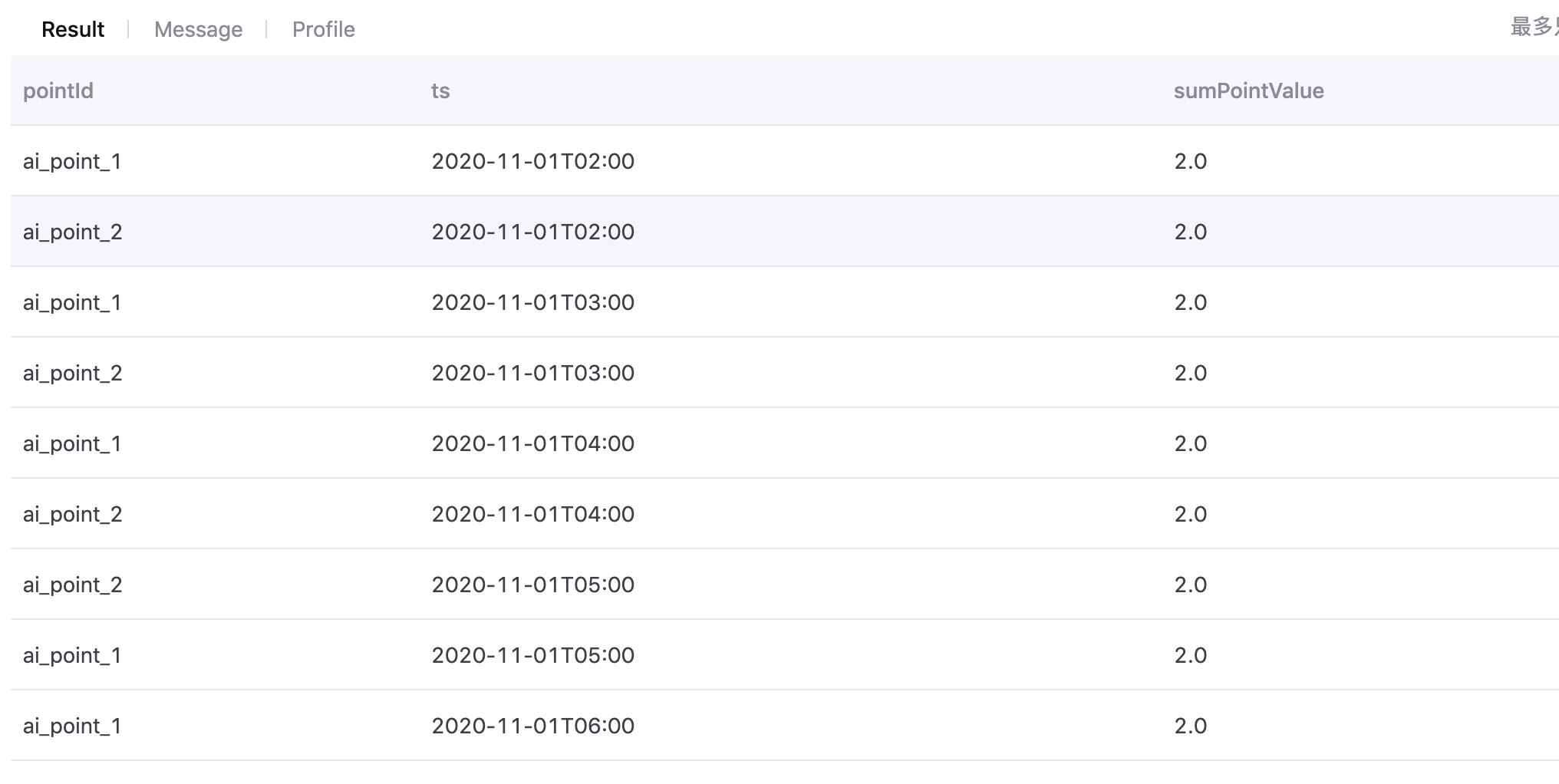
单设备多测点¶
使用以下查询语句,对同一设备的两个测点数据进行聚合计算:
device.pointTmp=device.sum(ai_point_1+ai_point_2)
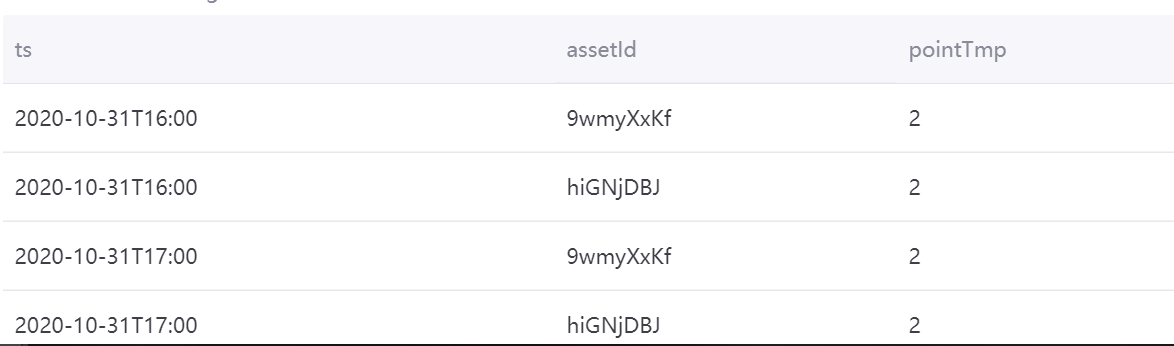
with t as (select cast((`timestamp`/3600000) * 3600000 as timestamp) as ts , assetId, pointId, avg(value) as value from tsdb.o15504722874071.eniot where assetId in ('hiGNjDBJ', '9wmyXxKf') and pointId in('ai_point_1','ai_point_2')and local_time >= '2020-11-01 00:00:00' and local_time < '2020-11-02 00:00:00' GROUP BY (`timestamp`/3600000), assetId,pointId) select t.ts, t.assetId, sum(CASE WHEN t.pointId in ('ai_point_1','ai_point_2') THEN 1 ELSE 0 END) as pointTmp from t group by t.ts,t.assetId
聚合结果如下图所示:
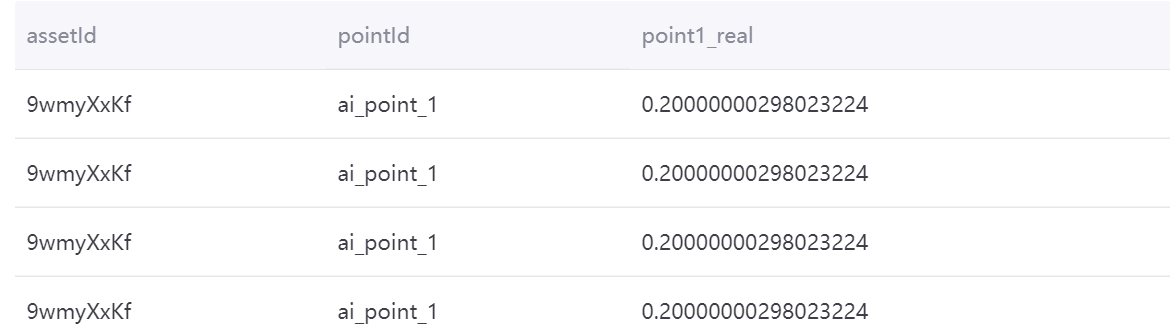
与MySQL中的维度表进行聚合计算¶
使用以下查询语句,与MySQL中的维度表进行聚合计算:
point1_real= ai_point_1*ai_point_1_coefficient
with t as (select cast((`timestamp`/3600000) * 3600000 as timestamp) as ts , assetId, pointId, avg(value) as value from tsdb.o15504722874071.eniot where assetId in ('hiGNjDBJ', '9wmyXxKf') and pointId in('ai_point_1')and local_time >= '2020-11-01 00:00:00' and local_time < '2020-11-02 00:00:00' GROUP BY (`timestamp`/3600000), assetId,pointId) select t.assetId, t.pointId, t.value*m.ai_point_1_coefficient as point1_real from mysql196.test.device m join t on m.dev_id=t.assetId
聚合结果如下图所示: