创建从外部数据库同步数据到 Hive 库的周期调度的任务¶
本文描述了如何从零开始创建从外部数据库同步数据到 Hive 库的周期调度的任务。
开始前准备
你必须已创建用于存放同步数据的目标 Hive 表。
步骤1:创建数据同步任务
登录 EnOS 管理控制台,选择 数据同步。
点击目录树上方的 +,或点击空白页中的 新建数据同步任务。
在 新建数据同步任务 窗口中,完成数据同步任务的基本设置。
方式:选择 新建,从零开始创建集成任务。如果选择 导入任务配置,参考 基于已有任务创建新的集成任务。
名称:输入数据同步任务的名称。
同步类型:选择 结构化数据。
调度类型:选择 周期调度。
描述:输入对数据同步任务的描述性信息。
选择目录:选择保存数据同步任务的目录。
点击 确定 完成创建。
步骤2: 选择数据源
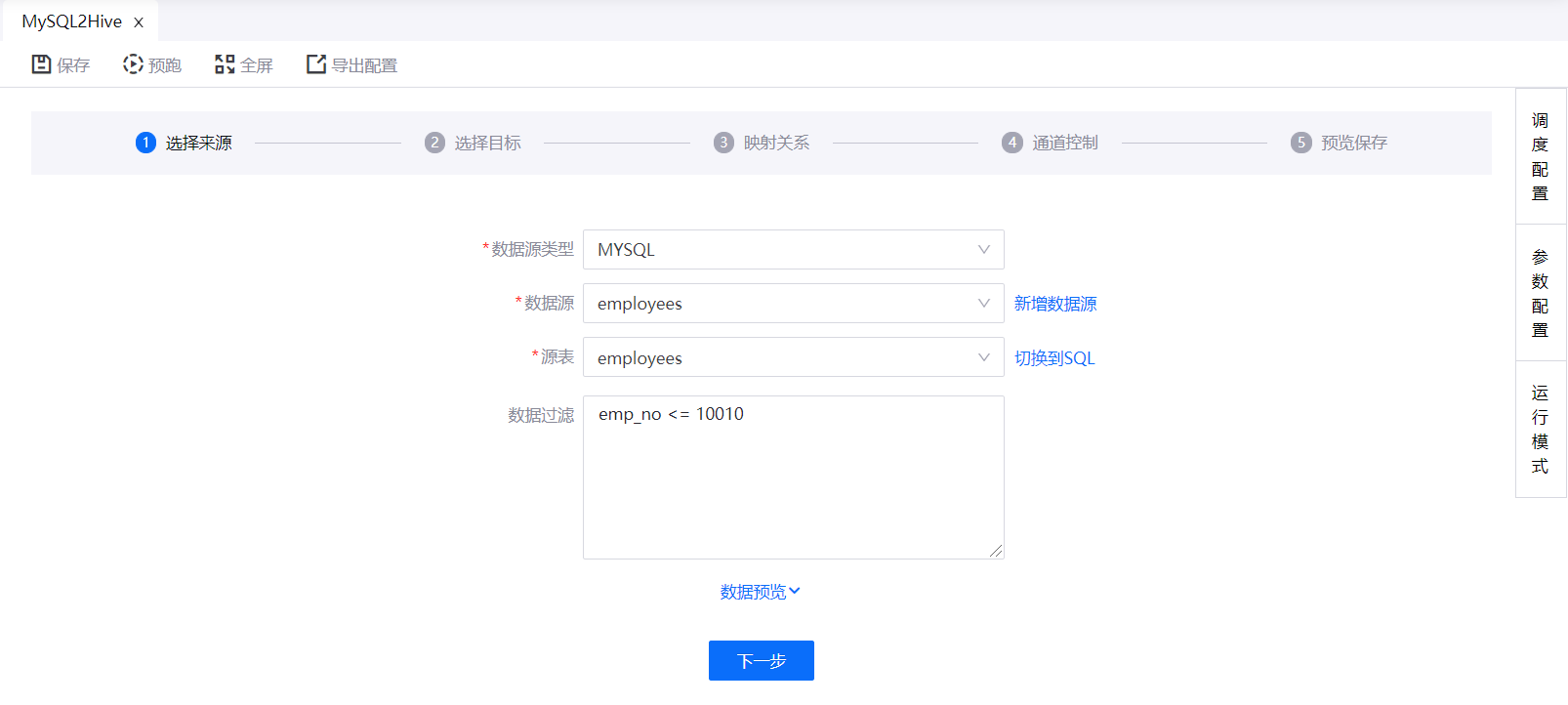
SQL Server、MySQL 或 Oracle 数据库
如选择从 MySQL、SQL Server 或 Oracle 数据库同步数据时,完成以下设置:
从已有的数据源列表中选择数据源或创建新数据源。更多信息,参考 数据源注册。
从数据库中选择需要同步的源表。
(可选)可提供 SQL 查询脚本筛选过滤需同步的数据。
备注
脚本中不需要输入
where,例如:emp_no <= 10010(可选)点击 数据预览,预览将被同步的数据,如下图所示:
点击 下一步。
备注
MySQL 数据库需要设置时区为 UTC,否则在数据同步里无法正常显示 MySQL 库里的表。
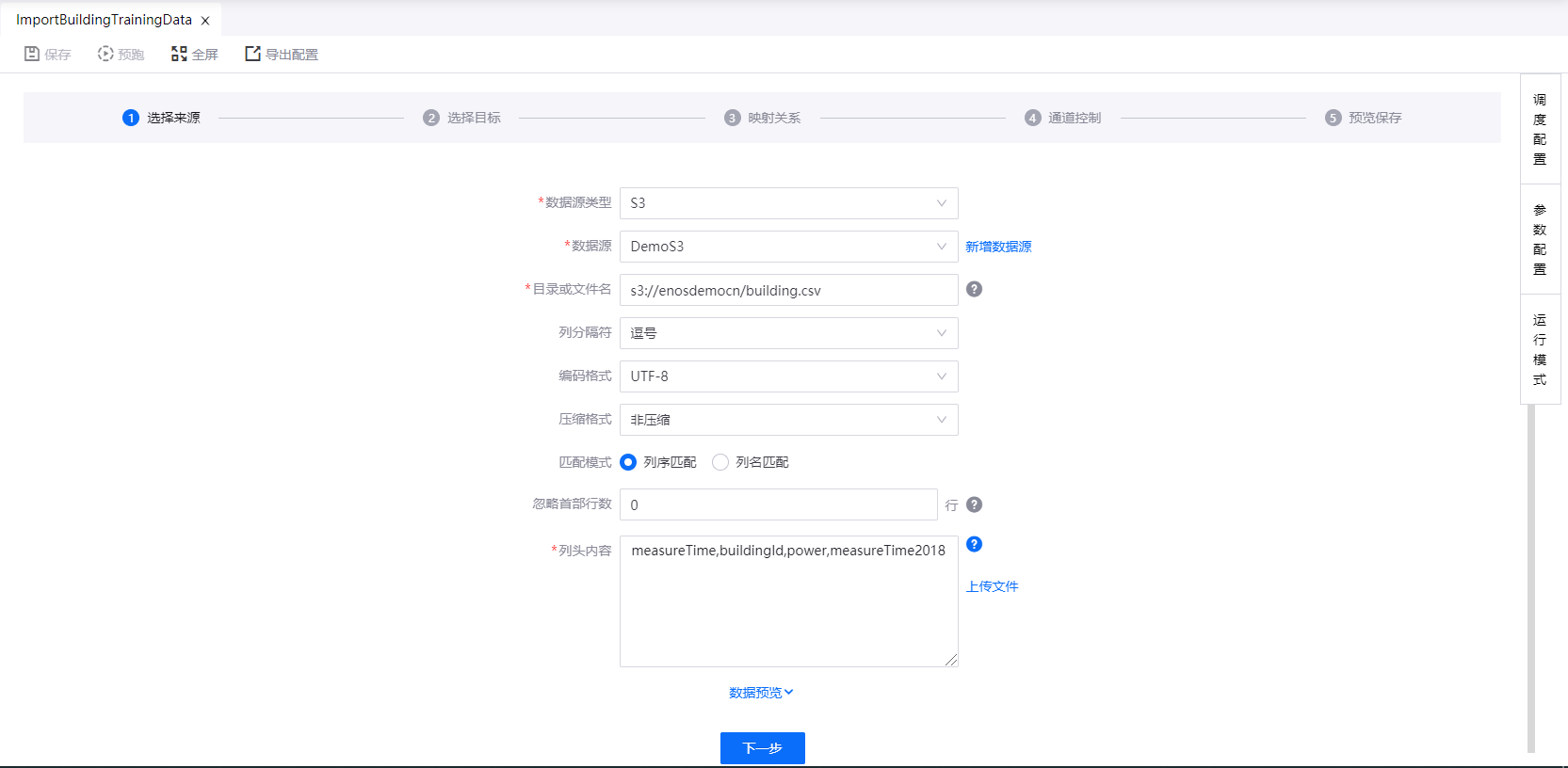
BLOB、FTP、SFTP 或 S3 文本数据库
如选择从 BLOB、FTP、SFTP 或 S3 文本数据库同步数据时,完成以下设置:
从已有的数据源列表中选择数据源或创建新数据源。更多信息,请参阅 数据源注册。
输入待同步的目录或文件名。当目录包含多个文件时,数据记录将被合并。在这种情况下,确保同一目录中的所有数据具有相同的列。
选择文本数据文件中使用的列分隔符,例如,Tab键、逗号、分号、空格或其他分隔符。
选择数据文件的编码格式:UTF-8、GBK、或 GB2312。
选择数据文件的压缩格式(非压缩、LZO、BZIP2、或 GZIP)。
选择数据匹配模式(按列序匹配或按列名匹配)。
选择加载数据时忽略首部的行数。
指定列头的名称,或上传列头文件。指定的列头将被作为数据源的列名与目标源中的列名匹配。
(可选)点击 数据预览,预览将同步的数据。
点击 下一步。
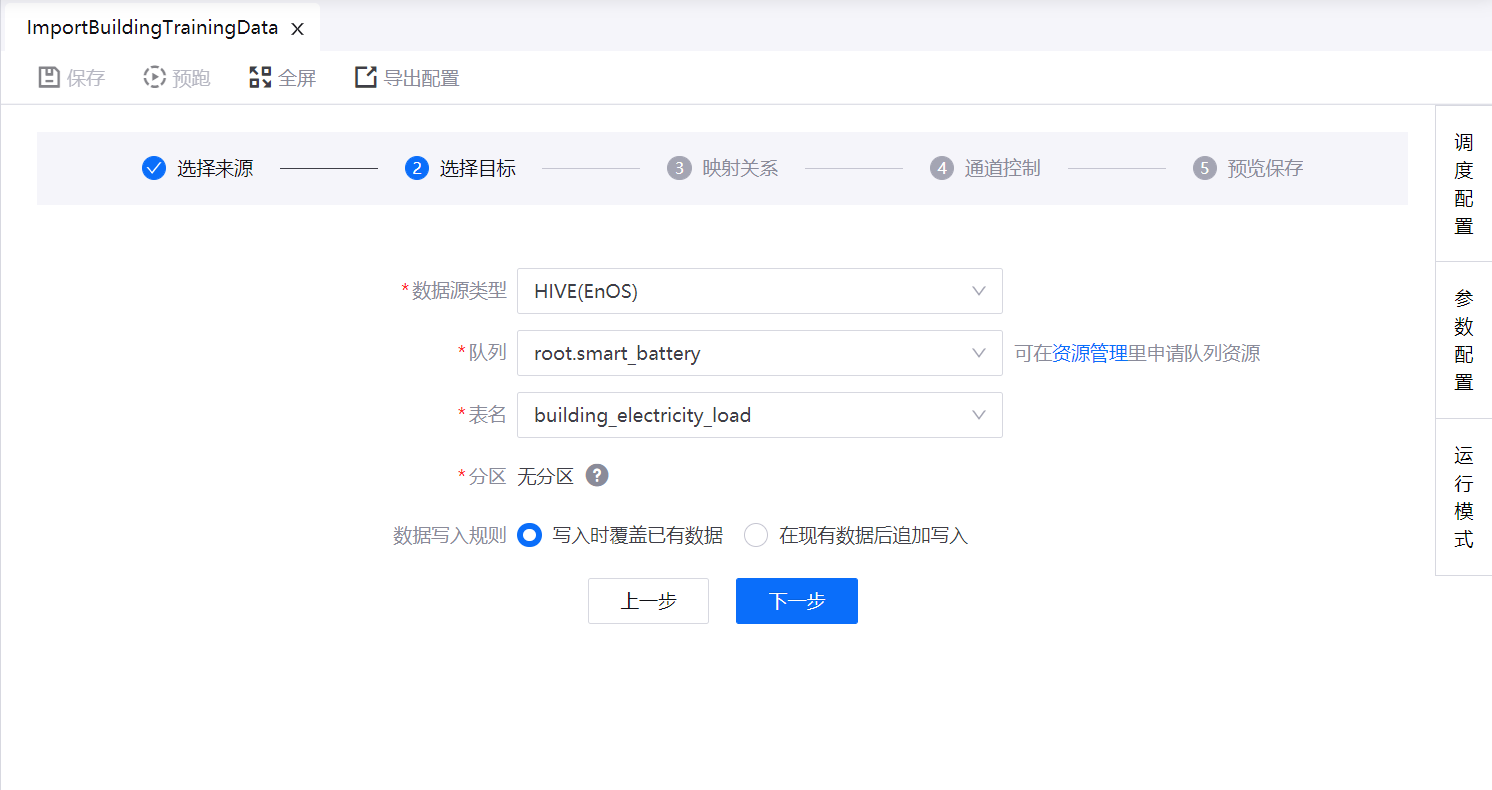
步骤3:选择目标源
目前仅支持 HIVE(EnOS) 类型的目标源,完成以下设置(以 S3 数据源为例)。
选择运行数据同步任务的 批数据处理-大数据队列 资源名称(可通过 资源管理 页面申请)。
选择已创建的 Hive 表名称。如果 Hive 表已分区,则会自动加载分区。
指定目标分区。可通过以下方法指定分区:
列名:系统将根据该列的每个值创建新分区(从右侧下拉框中选择对应的源列名)。例如:例名为日期,列值为
20180501和20180502,则系统会创建两个分区,一天一个分区。固定值:例如,输入2017-10-11,数据将自动同步到目标表的
2017-10-11分区。占位符:你可以使用系统提供的或自定义的参数。例如,系统变量
$ {cal_dt}。有关系统变量的更多信息,参考 系统变量列表。
设定数据写入的规则,覆盖目标表中已有数据或将数据添加到已有数据后。
点击 下一步。
步骤4:配置数据源与目标的映射关系
本步骤中,数据源中的指定的列名将与目标源中的列名匹配。也可手动更改数据源中的字段与目标源中的字段的映射关系。
点击页面左侧 来源字段 表中字段,将其添加到右侧 来源(配置映射关系) 列中,与 目标字段 列中的字段相匹配,完成映射关系设置。
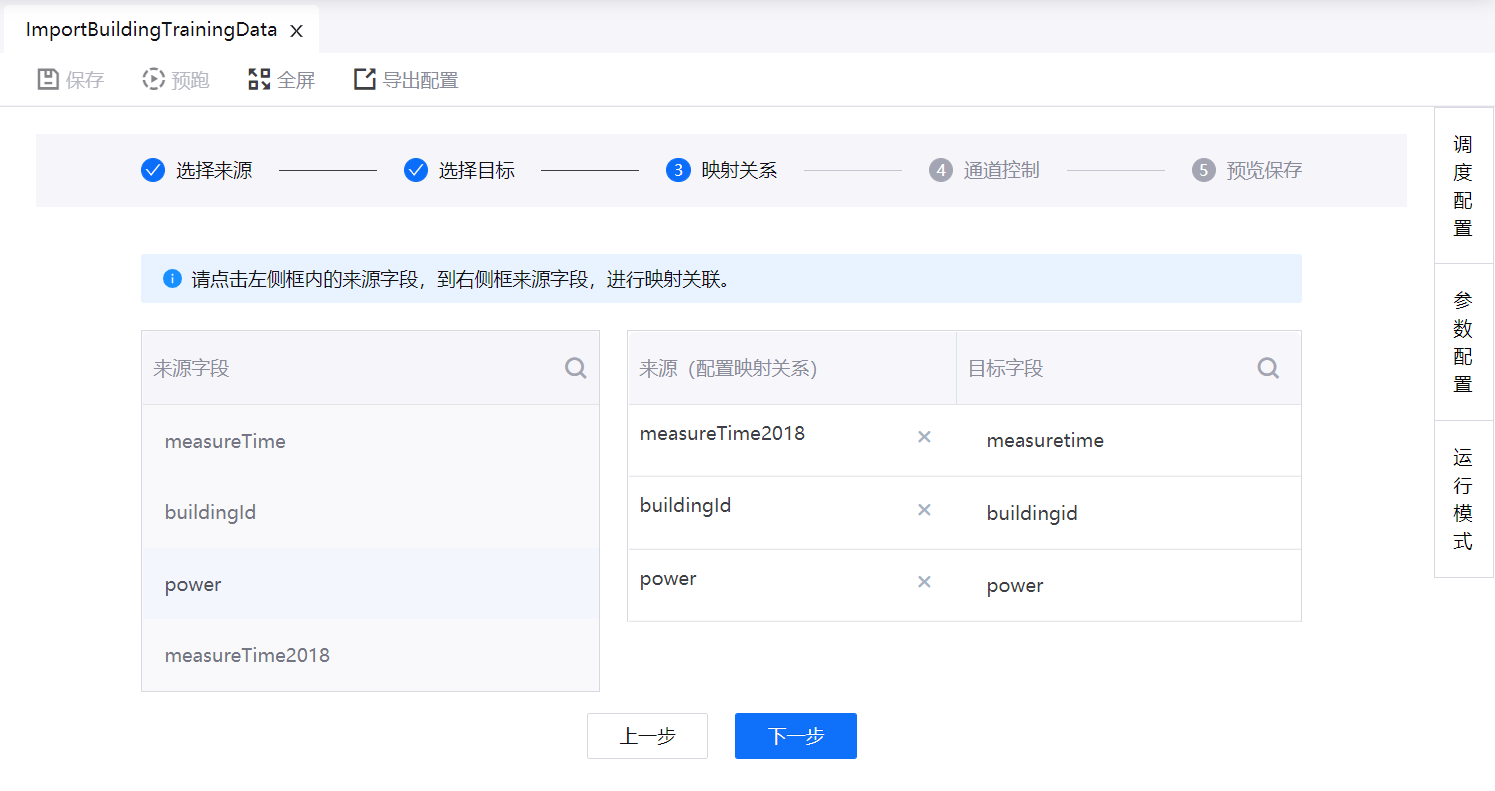
完成配置后,点击 下一步。
步骤5:配置调度
点击配置面板右侧边缘的 调度配置。
完成以下基本属性的配置:
任务名称:如需更新数据同步任务的名称,输入新的任务名称。
负责人:负责人可以是本组织中具有访问数据集权限的用户。默认为任务创建者。负责人设置规则如下:
作为任务创建者,无法删除自己。
可以在同一组织中添加其他负责人。
同一负责人不可再创建相同名称的另一个任务。
描述:(可选)输入对调度配置的说明。
预警方式:选择告警的方式。邮件为强制选择项。
邮件:当实例满足告警条件时,会向负责人发送告警电子邮件。
短信:必须是在用户注册期间通过短信认证的电话号码。当实例满足告警条件时,短信告警仅发送给负责人。
完成以下调度属性的配置:
生效日期:指定数据同步任务何时开始生效。
调度周期:指定调度周期,即运行任务的频率。例如,可以设定每天运行任务。可选择使用CronTab表达式。
具体时间:根据选择的周期,设置运行任务的确切时间。例如,可以设置在每天上午9:00运行任务。如果选择使用CronTab语法,请按7个字符的CronTab表达式输入。例如,值
59 59 23 * * ? *表示任务在每天23:59:59运行。有关CronTab的更多信息,参考http://cron.qqe2.com/。调度状态:(可选)可指定是否暂停任务调度。
超时时间:指定任务运行超时的时长。
重试次数:指定任务超时后尝试重新连接的次数。
重试间隔:指定每次重新连接尝试之间的时间间隔。
可否被依赖:(可选)设置该任务可否被其它任务引用。
步骤6:配置参数
为配置数据源和目标中使用的参数指定参数值。你可以为参数指定常量、系统变量、或自定义变量。步骤如下:
点击配置面板右侧边缘的 参数配置。
在 参数 输入框中,为每个使用到的参数指定参数值。
例如,你可以为S3数据源设置如下URL:
s3://history/log_solar_dt_change_inverter/${test_list}.each_valuetest_list为参数,你可以为该参数设置值:test_list=Array[20170515,20170516,20170517,20170518,20170519,20170520]EnOS将同步设置中指定目录下的所有数据。
你可以将参数值设定为系统变量。更多信息,参考 系统变量列表。
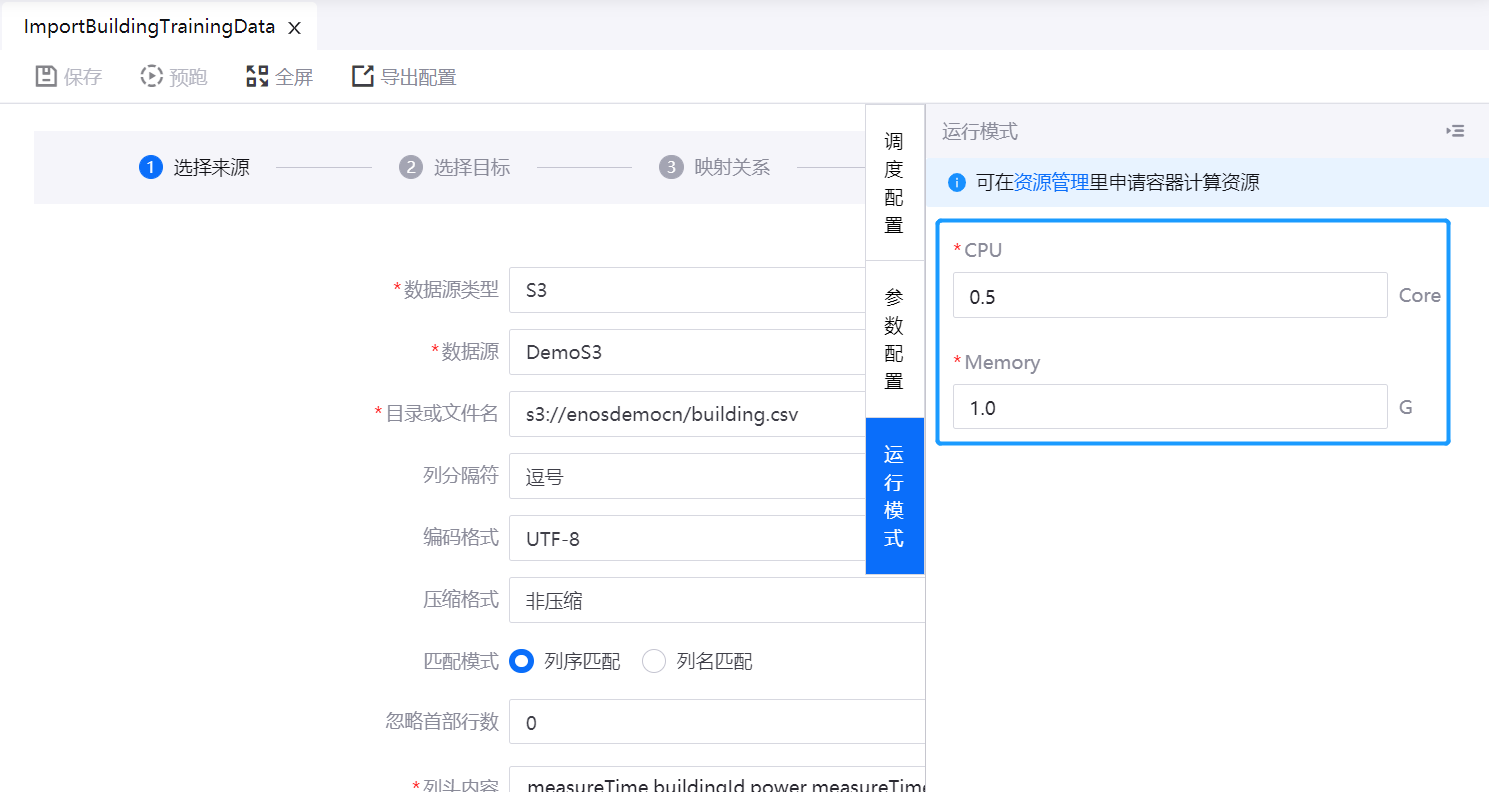
步骤7:配置运行模式¶
为数据同步任务配置容器计算资源。步骤如下:
点击配置面板右侧边缘的 运行模式。
输入运行数据同步任务所需的 CPU 和内存。
若 OU 尚未申请 批数据处理-容器计算 资源,可通过 资源管理 链接前往资源申请页面。
步骤8:配置并发数
选择要建立的并发连接数,然后点击 下一步。
如设置高并发数,数据库会承受更大的负载,当总传输速率固定时,单个连接的速率会变小。
步骤9:预览并保存配置
预览设置,如有需要可进行再编辑,然后点击 完成 保存配置。
后续操作
点击 预跑,测试任务,实例将在运行任务后产生。接着,你可在任务运维中跟踪有关实例的详细信息。更多信息,参考 任务运维。
从数据源同步数据后,你可以根据数据设置其他处理任务。更多信息,参考 批数据处理。