数据同步概述¶
EnOS 数据同步服务实现了在多种异构数据源之间的数据同步,可帮助数据开发人员进行如下数据同步任务:
同步结构化数据:将源数据库中的结构化数据(即可作为二维表抽象的数据)同步到 EnOS Hive 数据仓库,或将 EnOS Hive 数据仓库中的数据同步到目的数据库
同步文件流:将源数据库中的文件同步到 EnOS 文件存储 HDFS(目前支持 Azure BLOB 数据源)
数据同步任务流是一种特定类型的任务流。数据同步任务流的本质是包含单一数据同步任务类型的任务流,如下图所示:

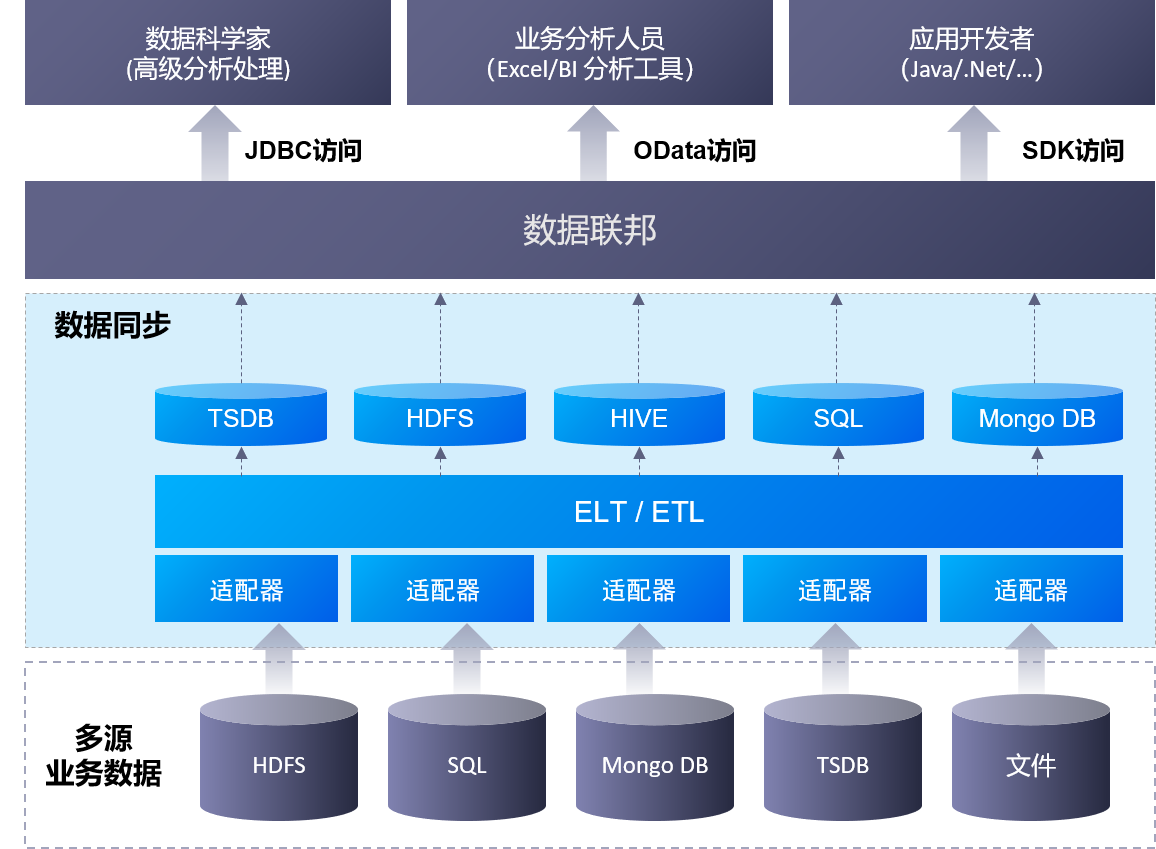
数据同步服务的主要功能组成和架构,如下图所示:
使用场景¶
数据同步包括以下典型的场景。
同步所有数据¶
同步所有数据通常使用在初次集成数据时,你可以一次性同步数据源中的完整数据至EnOS。更多信息,参考 创建从外部数据库同步数据到Hive库的手动调度的任务。
同步增量数据¶
同步增量数据场景通常运用于初次集成之后,此时你只需定期同步新数据或更新数据。你可以通过 where 语句指定要同步的增量数据。更多信息,参考 创建从外部数据库同步数据到Hive库的周期调度的任务。
同步文件¶
将文件从外部源数据库同步至 EnOS 文件存储 HDFS。更多信息,参考 从外部数据库同步文件到文件存储HDFS。
支持的数据源版本¶
数据同步服务支持的数据源版本如下:
数据源 |
版本 |
|---|---|
MYSQL |
8.0.16 |
Redis |
3.0.1 |
GitLab |
4.1.0 |
SQL Server |
4.0 |
S3 |
1.11.608 |
BLOB |
8.0.0 |
ORACLE |
10.2.0.4.0 |
Mongo DB |
3.12.7 |
FTP / SFTP |
N/A |
PostgreSQL |
42.2.8 |
资源准备¶
计算资源和存储资源
使用数据同步服务之前,需要准备以下资源:
批数据处理资源(大数据队列和容器计算资源):配置数据同步任务、使用 Hive、Spark 处理离线数据前,需申请批数据处理资源。
数据仓库存储资源:运行离线数据分析任务、创建 Hive 表并将数据写入 Hive 表前,需申请数据仓库存储资源。
文件存储 HDFS 资源:运行数据分析任务将文件存储到 HDFS 前,需申请文件存储 HDFS 资源。
OU 管理员可通过 EnOS 管理控制台 > 资源管理 页面,根据业务需要,申请相应规格的资源。有关申请 计算资源和存储资源 的详细信息,参见 资源规格说明。
当业务不再需要运行数据同步任务时,可通过 资源管理 页面删除和释放已申请的资源,降低资源使用成本。