使用算子进行开发¶
EnOS流数据处理服务提供一整套底层封装好的算子,供开发者基于业务需求开发定制化的流数据处理任务。
算子简介¶
EnOS流数据处理提供拖拽式的可视化流数据任务设计界面,开发者不需要写代码,通过编排算子组合成流数据处理任务,实现数据采集、数据过滤,数据处理、和数据存储等任务。
流数据处理任务(Pipeline)一般由多个阶段(Stage)和连线连接而成,组成有序的通路,数据会通过这个通路按顺序进行有序的流转。每一个阶段代表了对数据进行的一次读写或者操作。这样的流程构成了一条流数据处理任务。一条流数据处理任务一般包含以下几种类型的 Stage:
数据源(Source)
用于指定数据来源的 Stage,数据可从不同的数据源抽取,并将数据输出传递给后面的阶段,例如 Kafka Consumer。
处理器(Processor)
用于进行数据转化的 Stage,对输入的数据进行规范化或者流转处理(过滤、分流、计算等)。
目标源(Destination)
用于数据存储的 Stage,将数据处理完后存入目标系统或者转入另一个 Pipeline 进行再次处理。
新建流数据处理任务¶
前提条件
EnOS流数据处理服务提供多个版本的算子库,在设计流数据处理任务前,需要先安装对应版本的算子库。详细信息,参见 安装算法模板和算子库。
通过以下步骤,使用算子开发流数据处理任务:
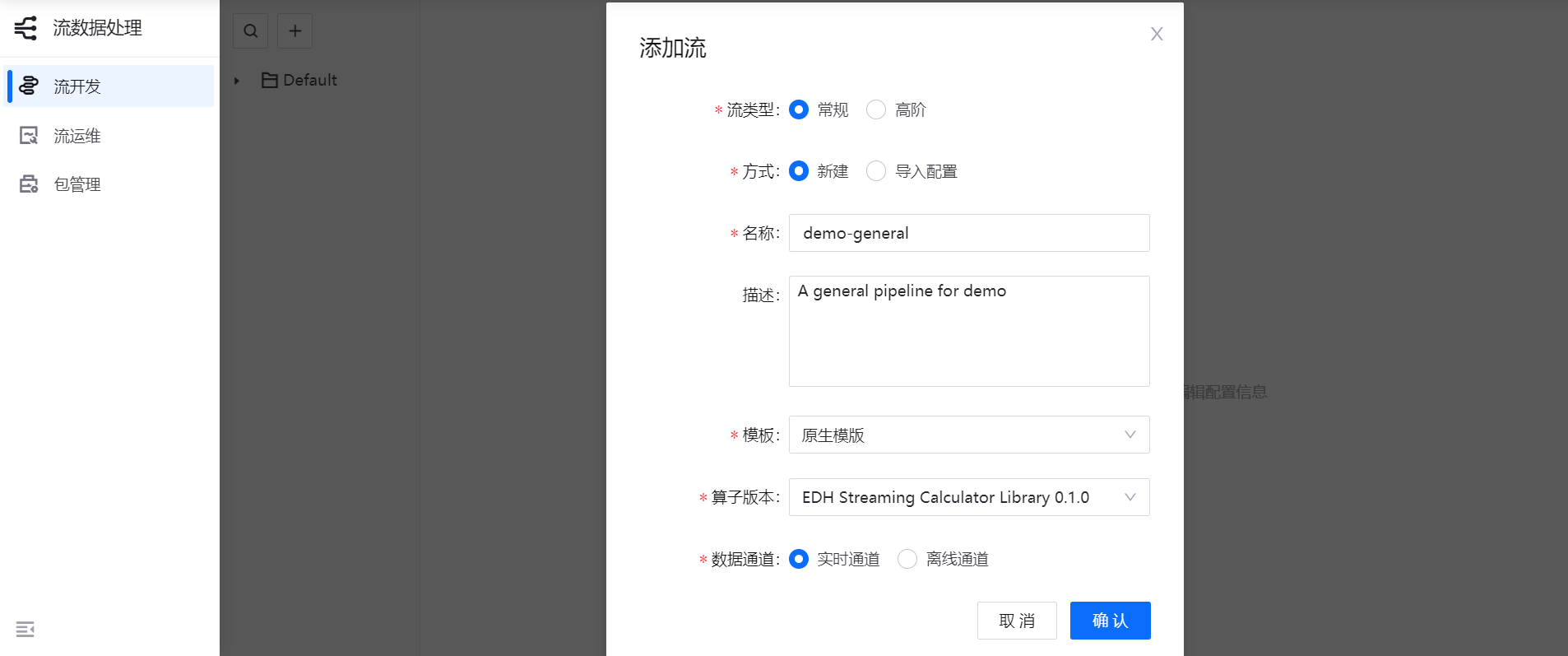
登录 EnOS 管理控制台,选择 流数据处理 > 流开发,点击任务列表上方的 + 图标。
在 添加流 窗口中,选择 新建 方式。也可通过导入配置文件快速创建流数据处理任务。
输入流数据处理任务的名称和描述。
从 模板 下拉菜单中,选择 原生模板。
从 算子版本 下拉菜单中,选择已安装的算子库版本。
在 数据通道 栏中,选择待处理的流数据类型:
若数据为接入设备上送的数据,选择 实时通道
若数据为通过消息集成模块导入的数据,选择 离线通道
点击 确认,进入数据处理任务设计页面。
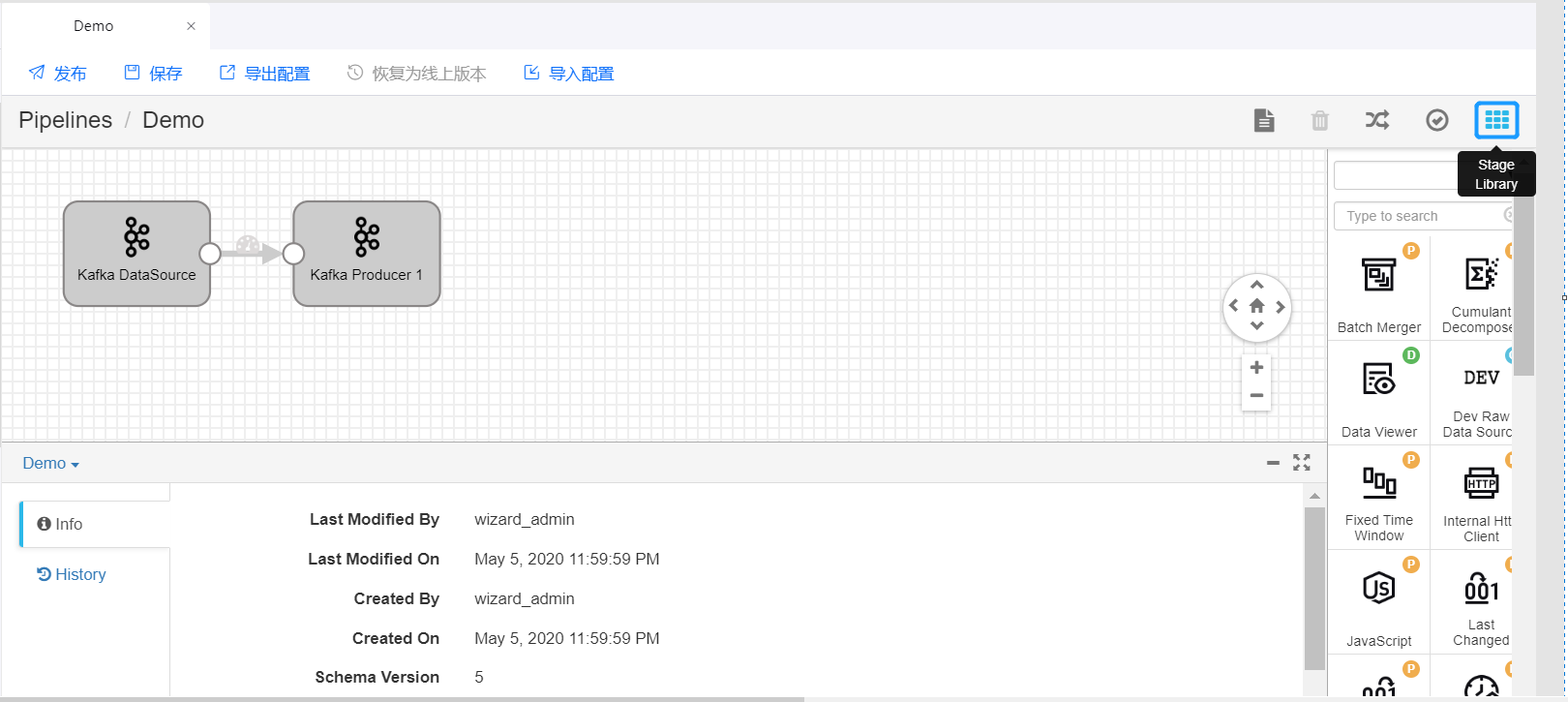
设计流数据处理任务¶
通过以下步骤,按业务需求使用算子设计流数据处理任务:
在流数据处理任务设计页面中,点击页面右上角的 Stage Library,从下拉菜单中找到需要使用的算子。点击数据处理算子(如 Point Selector),将其添加到 Pipeline 编辑页面。
拖拽 Stage 和连接线,将添加的 Stage 编排进 Pipeline 中。选中添加的算子,在配置项中完成对该算子的参数配置。
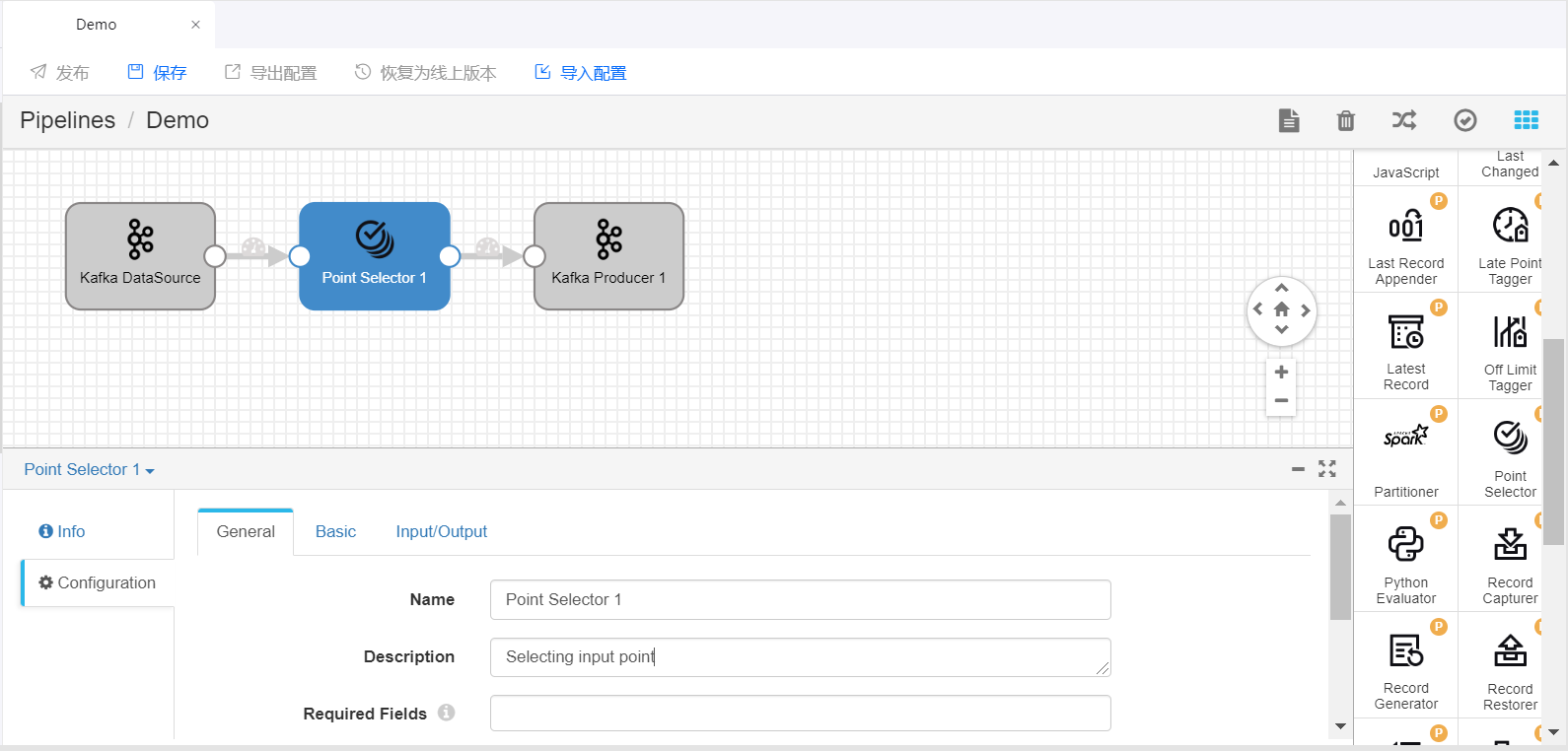
重复步骤1、2,将其他算子编排进 Pipeline 中,并完成各个 Stage 的参数配置。
点击任务栏中的 保存,保存流数据处理任务的配置信息。
完成算子配置后,点击工具栏中的 Validate 图标,检查 Pipeline 和算子参数配置是否正确,并按照检查结果修改配置。
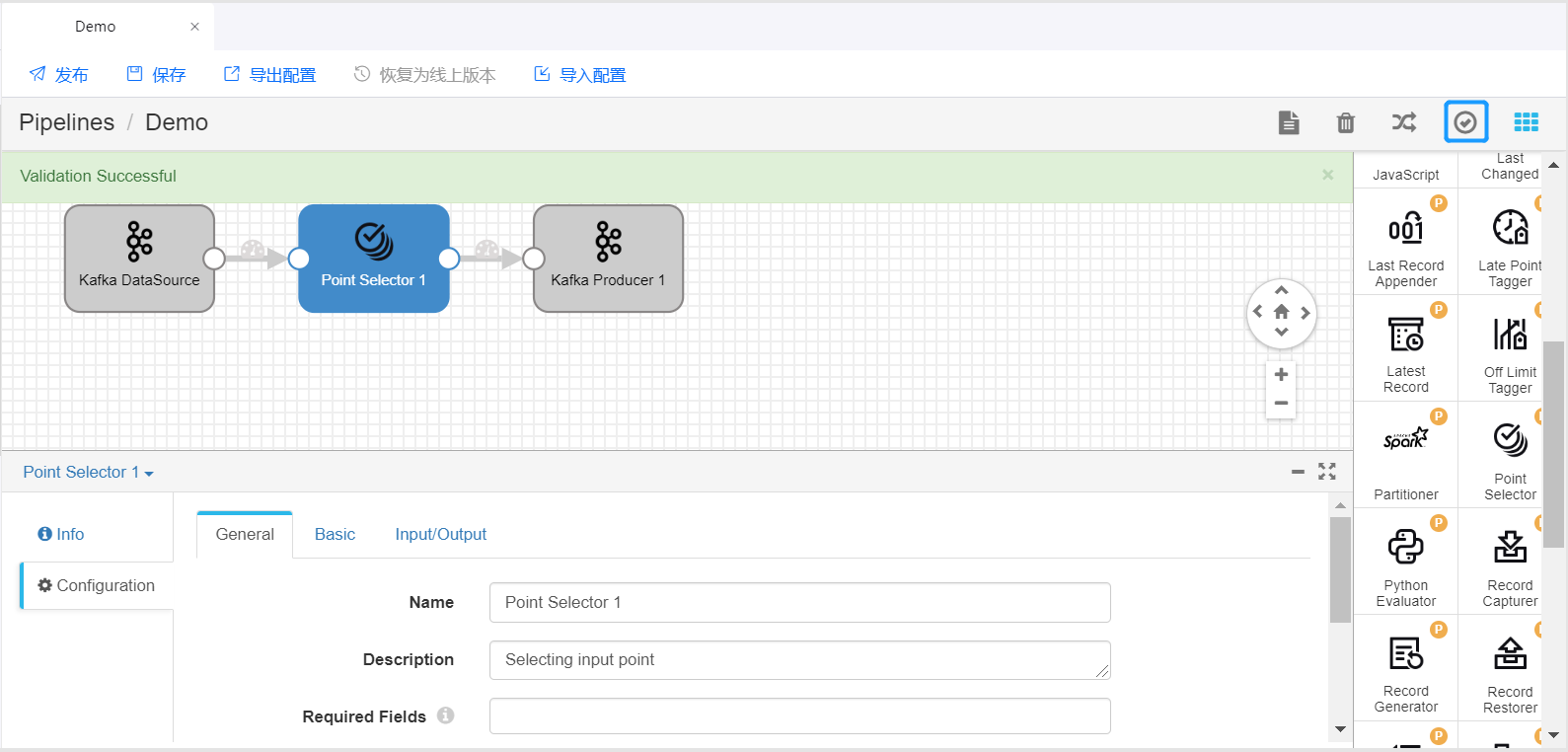
更多使用算子配置 Pipeline 的详细介绍,参考 StreamSets User Guide。
导入流数据处理任务配置¶
在数据处理任务设计页面上,除了设计全新的流数据处理任务外,也可通过导入现有流数据处理任务配置文件,快速创建和配置流数据处理任务。
在流数据处理任务设计页面中,点击任务栏中的 导入配置。
浏览并选择流数据处理任务配置文件,然后点击 确定。
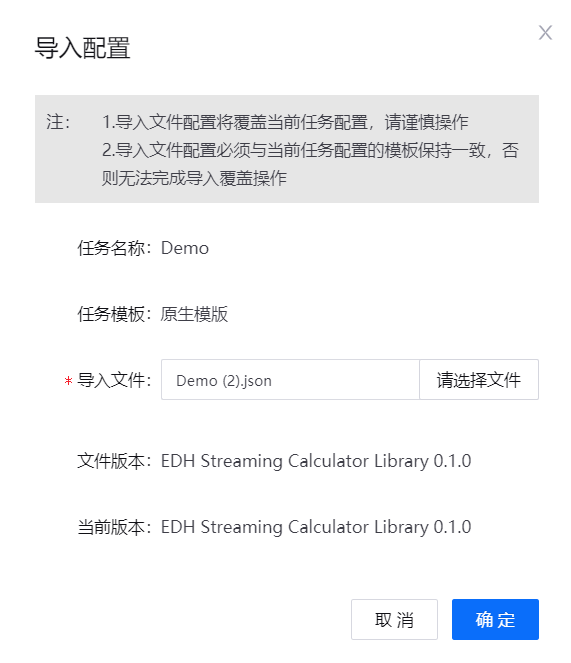
根据业务需要,编辑和保存导入的流数据处理任务。
发布和运行流数据处理任务¶
算子配置检查通过后,即可将流数据处理任务发布上线并运行。
点击任务栏中的 发布,将流数据处理任务发布上线。
进入 流数据处理 > 流运维 页面,查看已发布的流数据处理任务,其默认状态为 PUBLISHED。
完成流数据处理任务的运行配置和告警配置,确保相关的系统流任务已启动,然后启动流数据处理任务。
有关流数据处理任务运维相关的详细信息,参考 维护流数据处理任务。
算子参考文档¶
对算子的功能、配置参数、和输出结果的详细介绍,参考 算子参考说明。
教程¶
学习为更复杂的业务场景开发流数据处理任务,参考 Developing with Operators。