支持的解释器¶
%hive¶
在默认配置下,Hive解释器会使用default队列资源进行数据查询和处理,任务运行不可控且资源无法管理。若需运行资源占用较高的数据查询和处理任务,需申请批数据处理-大数据队列资源,并在notebook中配置申请的队列资源名称。详细步骤如下:
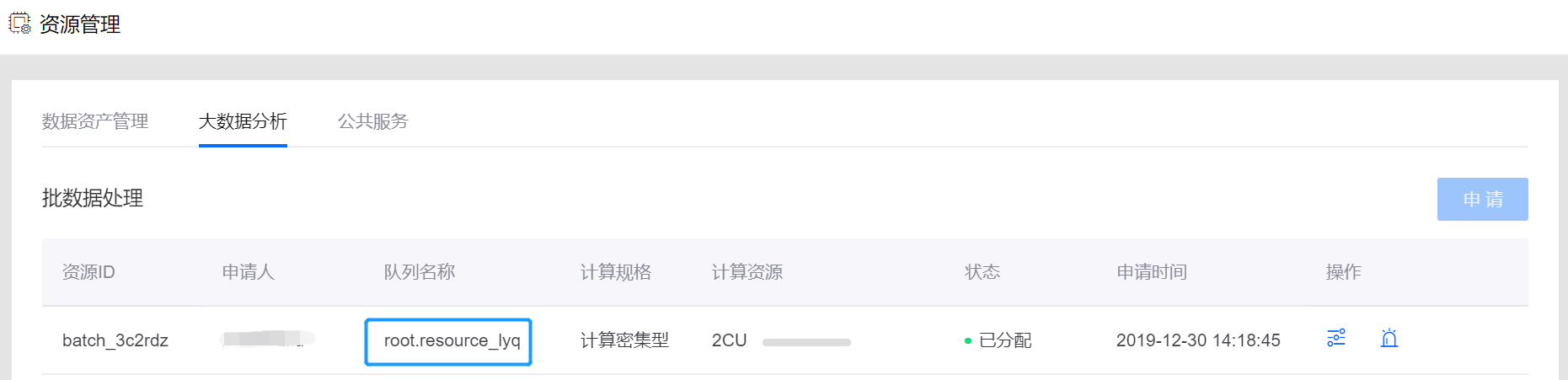
通过 EnOS管理门户 > 资源管理 > 企业数据平台(或使用Zeppelin页面链接),申请 批数据处理-大数据队列 资源。
申请的资源分配成功后,在资源列表的 队列名称 列中,查看大数据队列名称。
打开Zeppelin notebook,切换到%hive解释器,输入并执行以下代码:
set mapreduce.job.queue.name={队列名称}
查看执行结果。

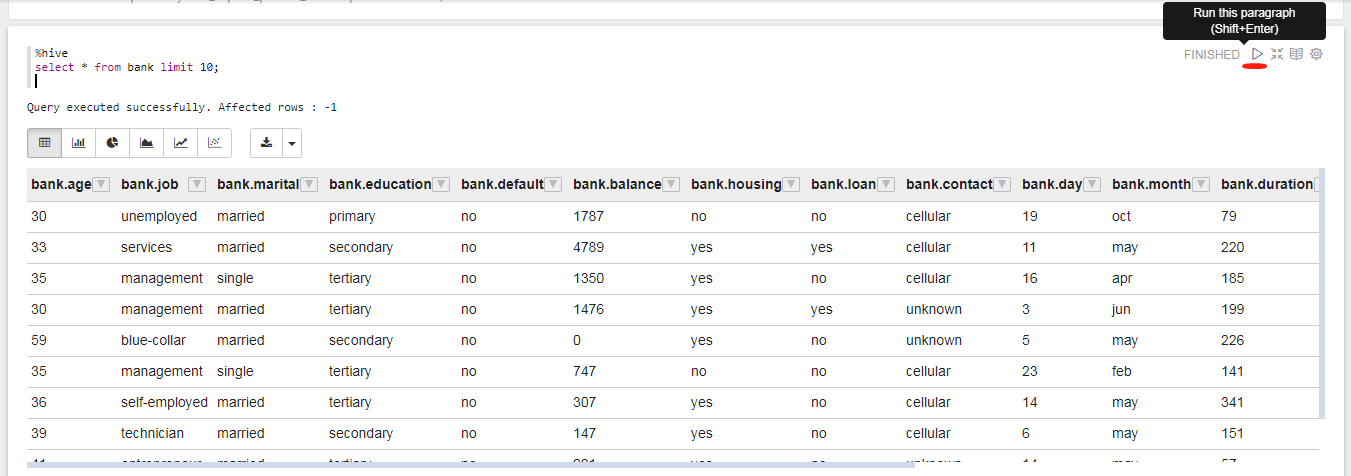
以下代码块提供的示例介绍了如何使用SQL查询原始数据表。
%hive
select * from bank limit 10;
单击  运行代码段落,你将得到类似于以下所示的结果。
运行代码段落,你将得到类似于以下所示的结果。
%md¶
以下代码块提供了markdown的示例:
%md
# hello world
- **hello world**
单击 运行代码段落,你将得到类似于以下所示的结果。

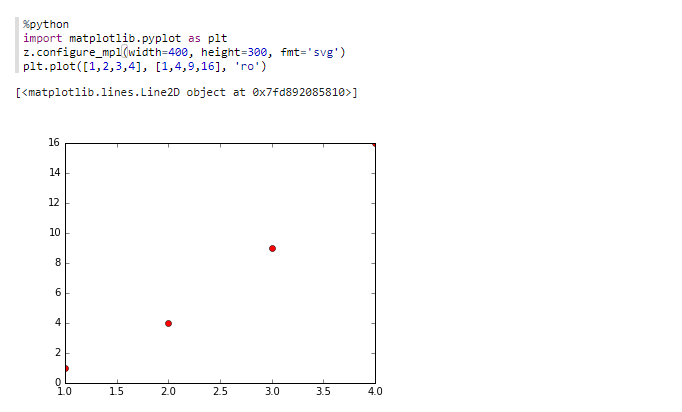
%python¶
以下代码块提供的示例介绍了python的基本操作,即如何使用python标记两个坐标点。
%python
import matplotlib.pyplot as plt
z.configure_mpl(width=400, height=300, fmt='svg')
plt.plot([1,2,3,4], [1,4,9,16], 'ro')
单击 运行代码段落,你将得到类似于以下所示的结果。
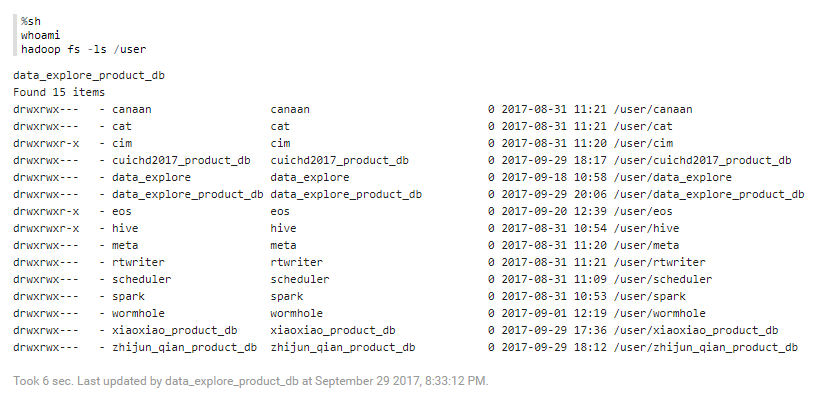
%sh¶
以下代码块提供的示例介绍了shell的基本操作。
%sh
whoami
hadoop fs -ls /user
单击 运行代码段落,你将得到类似于以下所示的结果。