从空白新建脚本¶
本章节描述如何从零开始新建脚本。
开始前准备¶
确保你已准备好脚本中需要访问的数据源和数据。
新建脚本¶
通过以下步骤,从零开始新建脚本。
登录EnOS管理门户,从左侧导航栏中选择 批数据处理 > 脚本开发,点击目录上方的 +,或点击空白页中的 新建脚本。
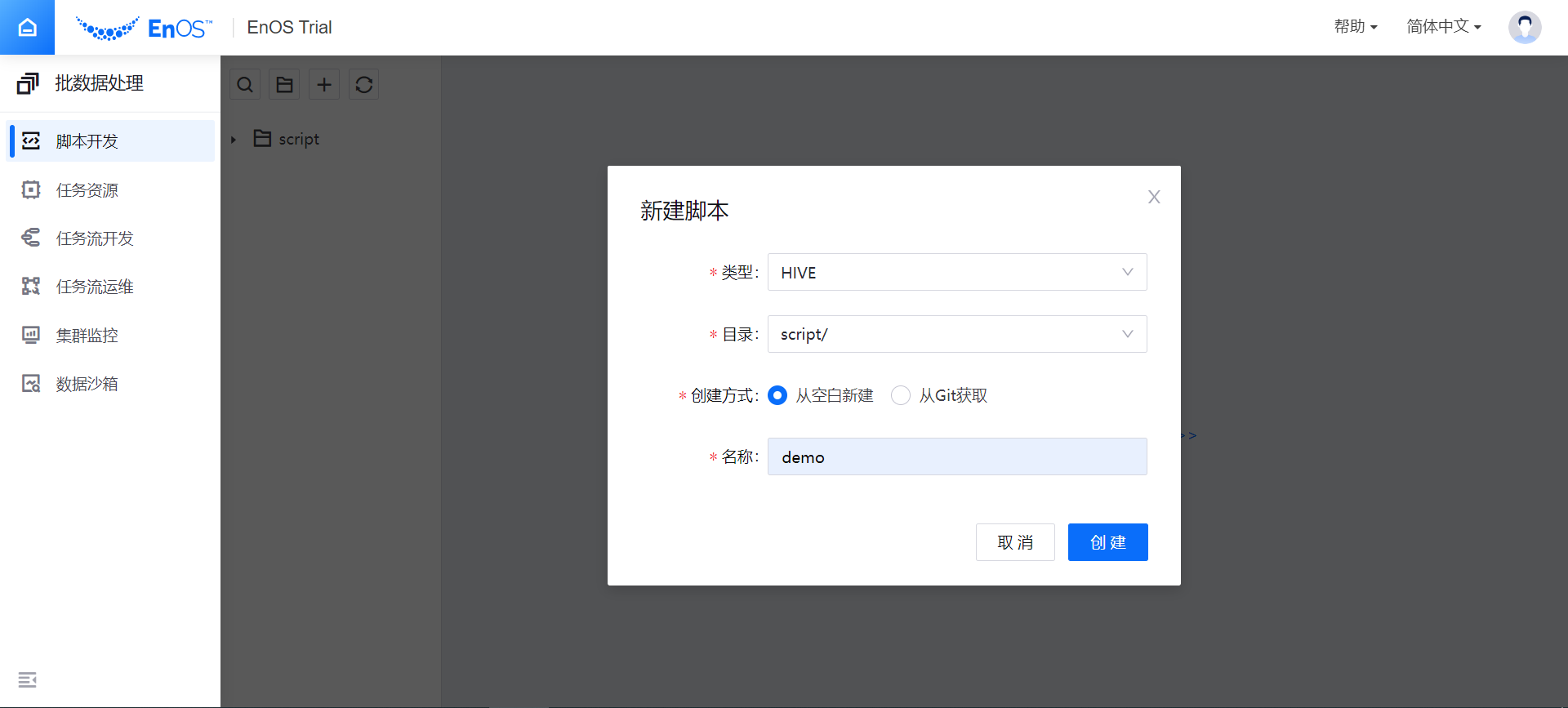
在 新建脚本 窗口中,完成以下设置,然后点击 创建。
类型:选择待创建的脚本类型(目前支持 Hive SQL 脚本 和 Spark SQL 脚本)
目录:选择保存脚本文件的目录
创建方式:选择 从空白新建
名称:输入脚本文件的名称
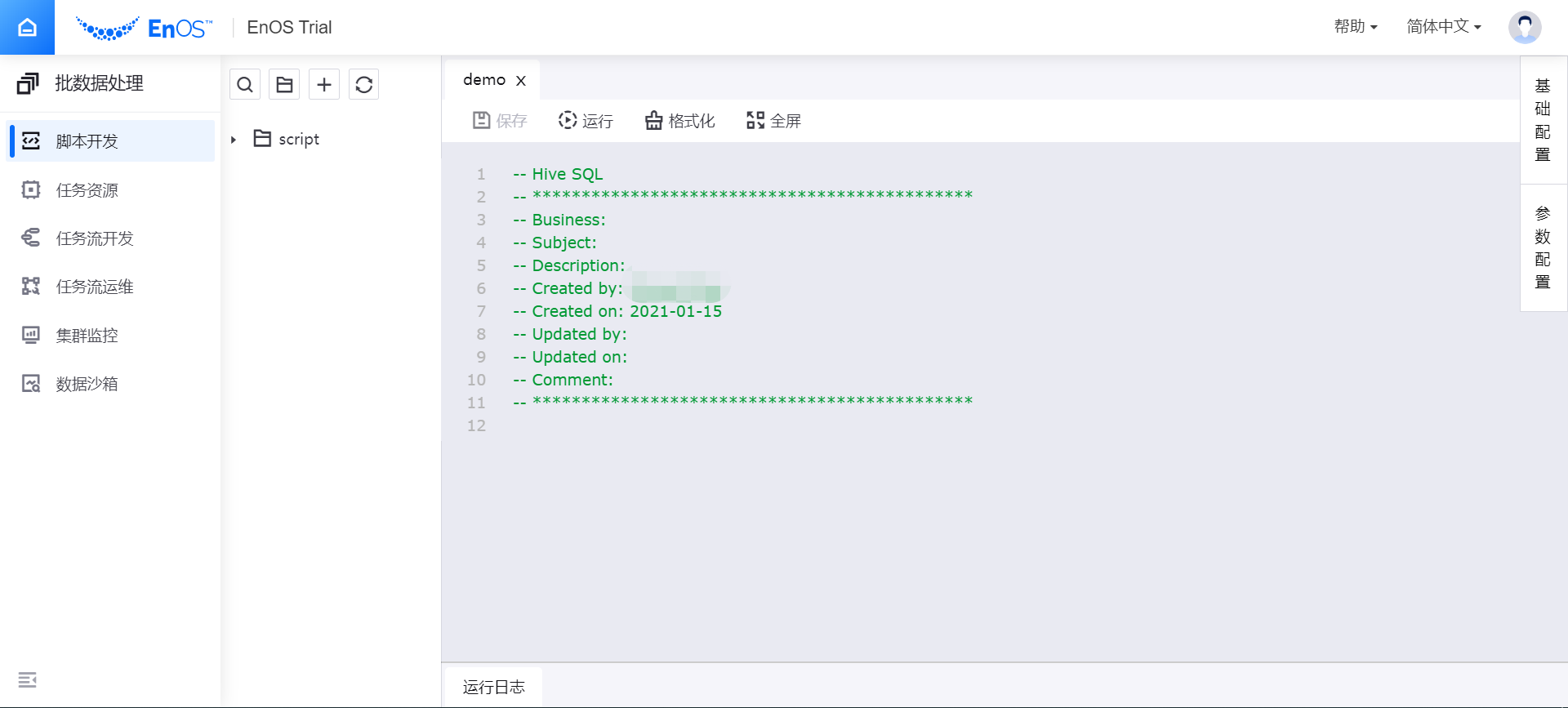
查看新建的脚本文件。生成的空白脚本文件带有创建人和创建时间等注释信息。
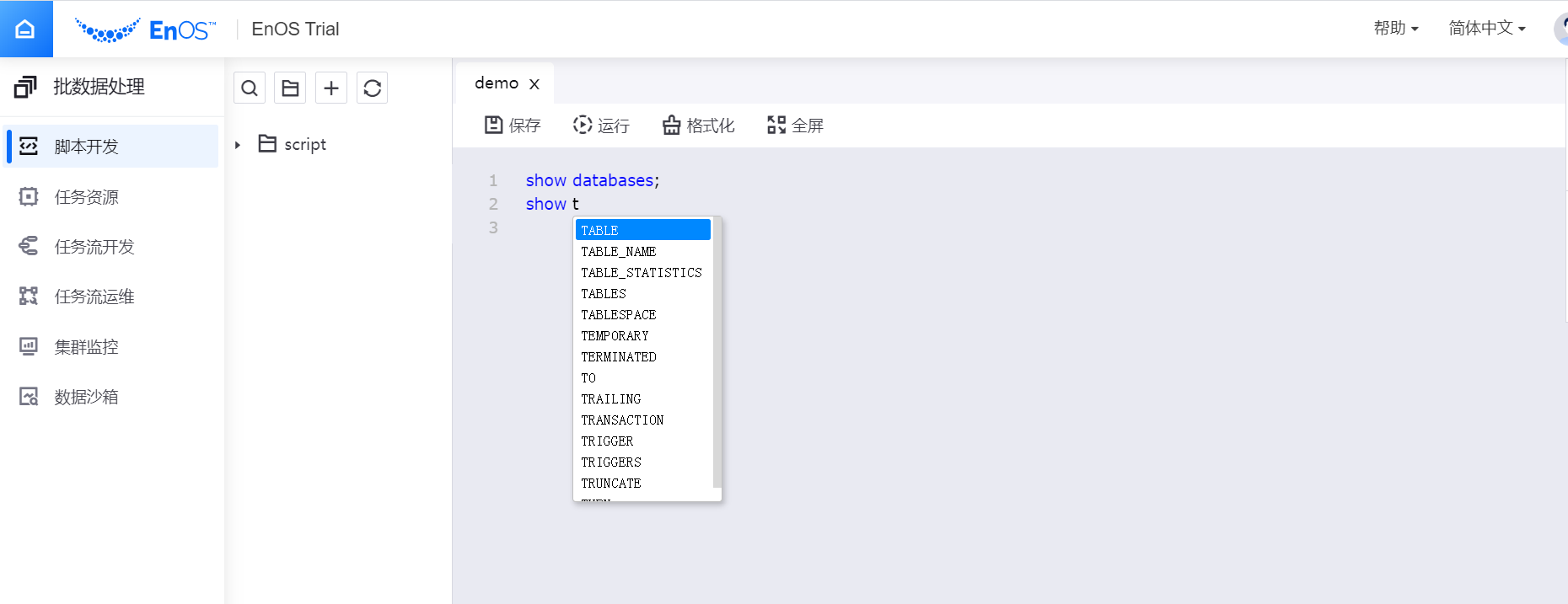
编辑脚本文件。在输入代码时,编辑器会实时显示提示信息。点击 保存,实时地保存对文件的编辑。
运行脚本
完成脚本文件编辑后,可运行脚本,查看运行结果,对脚本进行调试。
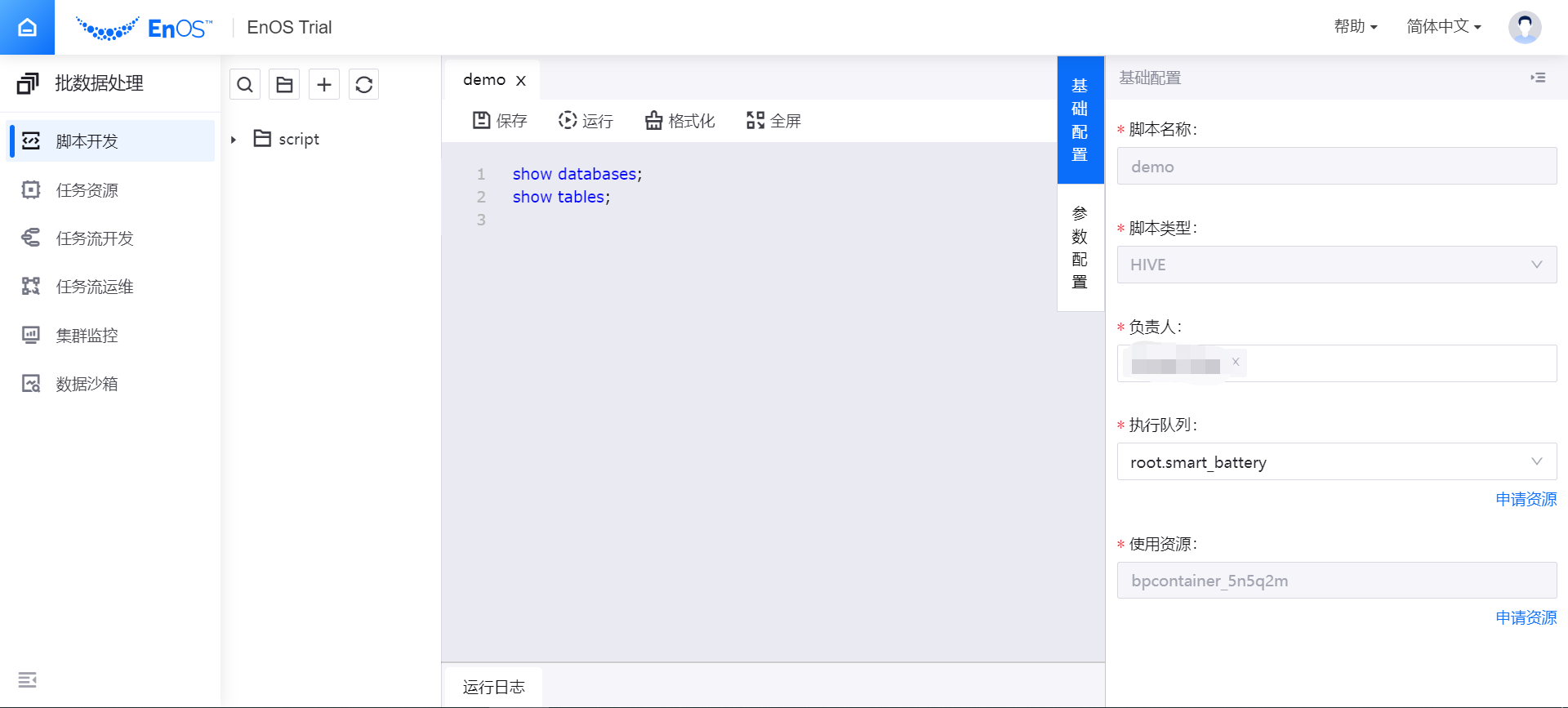
点击脚本编辑页面右侧的 基础配置,完成脚本的基础信息配置:
在 负责人 一栏中,输入脚本的负责人(仅负责人有权限编辑和使用脚本)。
从 执行队列 下拉菜单中,选择已通过 资源管理 页面申请的 批数据处理-大数据队列 资源。
从 使用资源 下拉菜单中,选择已通过 资源管理 页面申请的 批数据处理-容器计算(设计态模式)资源。
(可选)点击脚本编辑页面右侧的 参数配置,完成脚本需使用的参数配置。
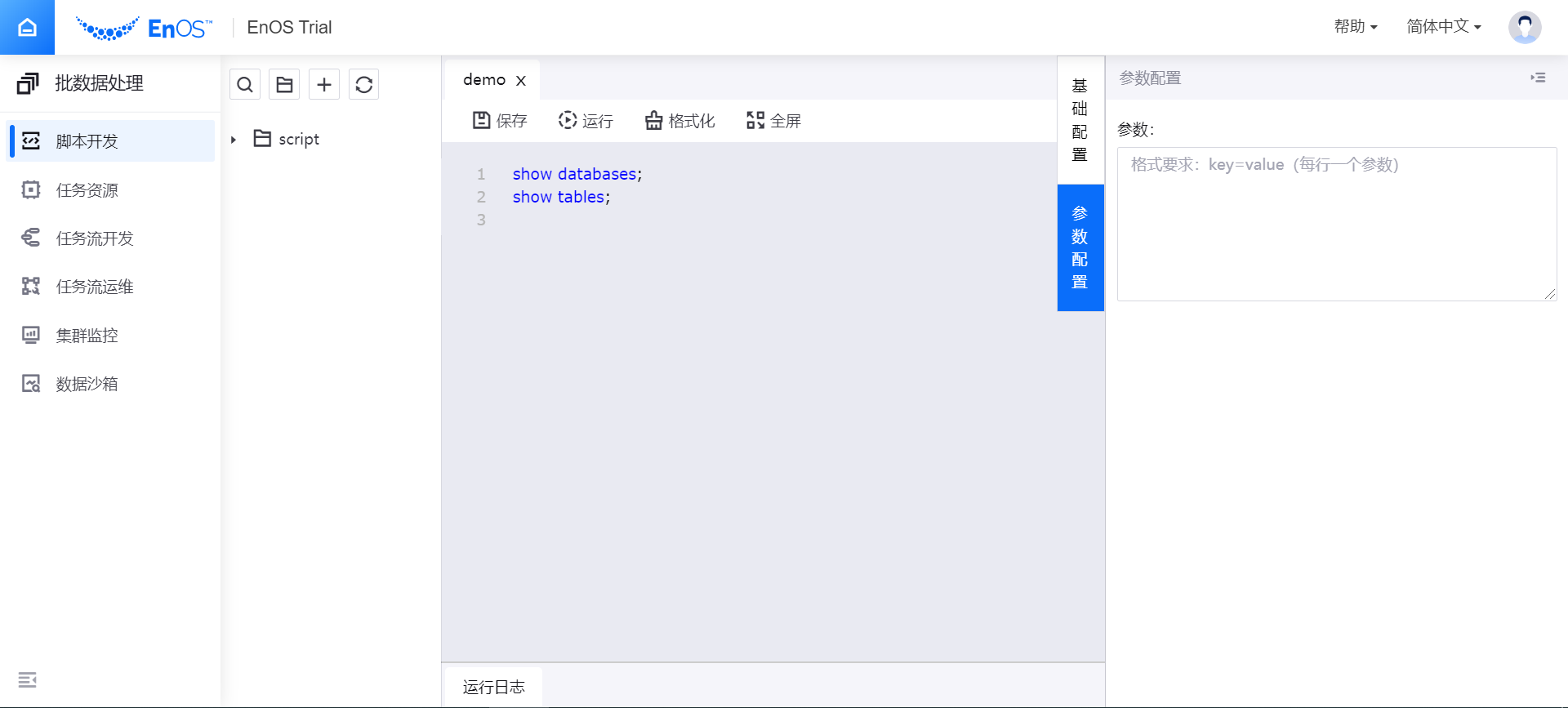
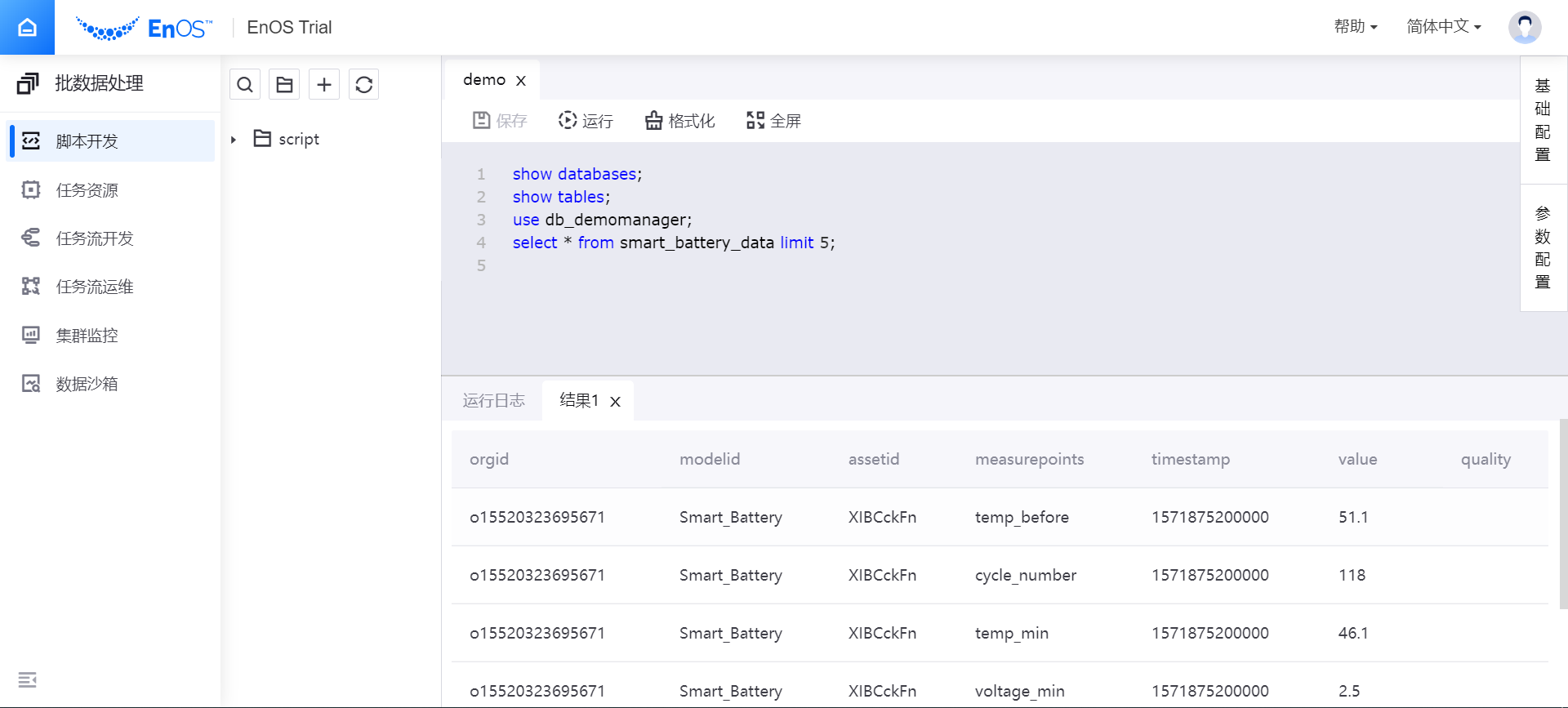
点击 运行,脚本将按指定的配置信息运行。运行结果将显示在 结果 栏中。
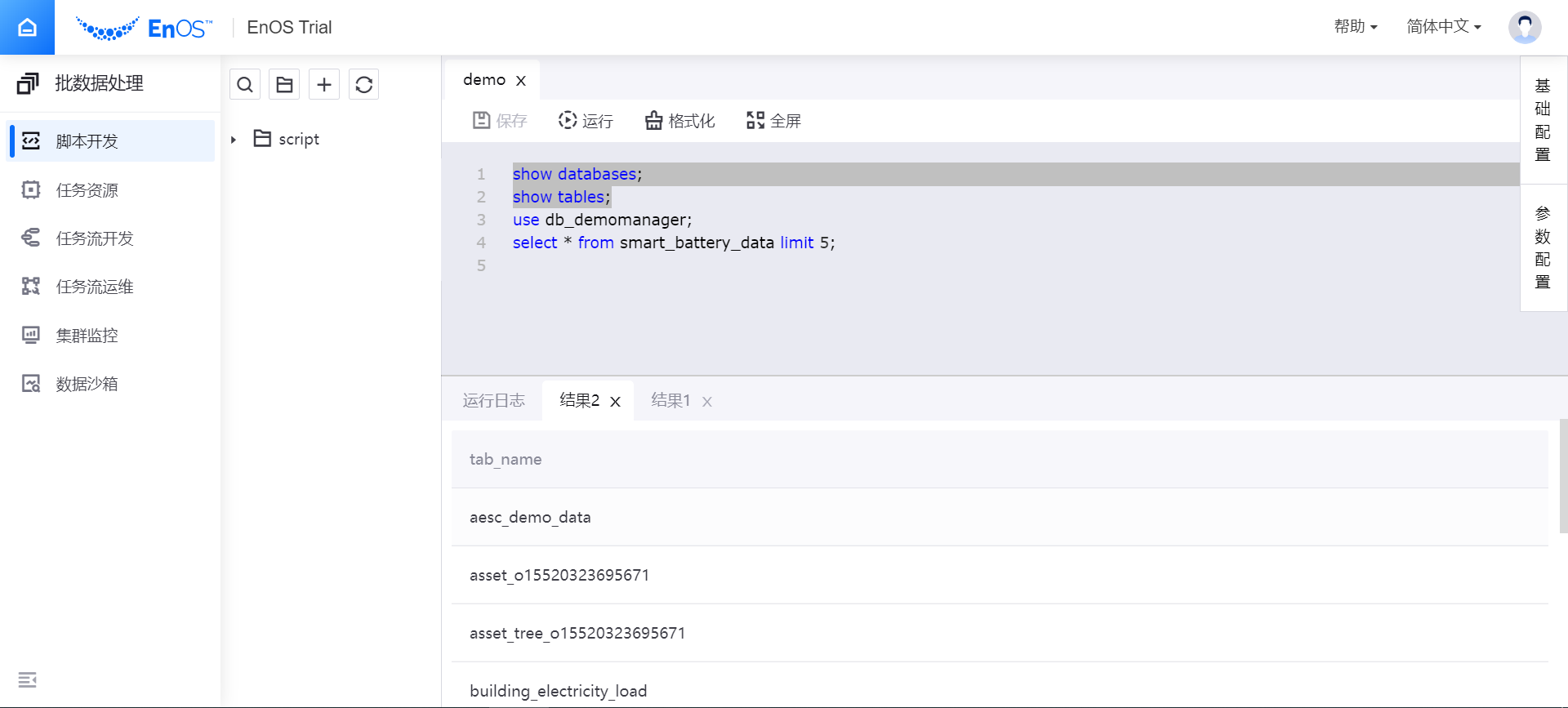
如仅需运行脚本中的某段代码,可选中需运行的代码,并执行。
如果脚本运行出错,可查看运行日志,排查故障。